论文阅读_Search-R1:大模型+搜索引擎
1 | 英文名称:Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning |
1 读后感
由于大语言模型(LLM)的知识更新不够迅速,LLM 结合搜索的应用场景变得非常普遍。未来的发展趋势可能会是“小而美”的 LLM 与强大的 Agent、工具、搜索、RAG 等结合,而不是追求“大而全”的 LLM 来解决所有问题。
这篇文章主要探讨大模型与搜索的结合策略:如何判断何时需要检索、如何调用检索功能,以及如何整合检索结果。
具体研究方法对比了 PPO 和 GRPO,展示了强化学习在特定应用中的实际应用和探索过程。对我而言,关键启发性点包括:在每个步骤中判断是否需要检索,不限定具体过程而专注于优化整体结果,以及发现模型自我进化过程中,自主验证搜索内容是否存在矛盾。实验细节和结果都具有启发性。
(下文中斜体为个人观点,正常字体以翻译为主)
2 摘要
- 目标:提高大型语言模型(LLMs)在推理和文本生成中的外部知识获取和及时信息处理能力。
- 方法:引入 Search-R1 模型,通过强化学习自行生成搜索查询,优化多轮搜索交互,利用检索的标记屏蔽进行稳定的强化学习训练。
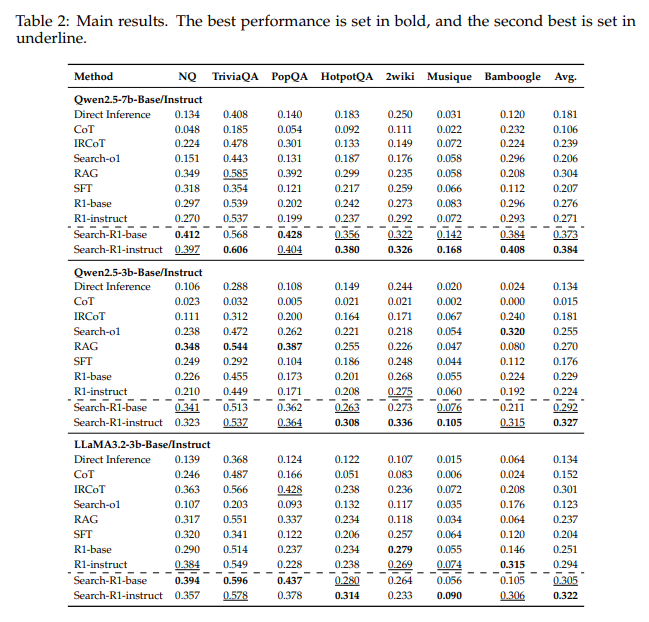
- 结论:在七个问答数据集上的实验表明,Search-R1 在性能上提高了 26%(Qwen2.5-7B)、21%(Qwen2.5-3B)和 10%(LLaMA3.2-3B),相较于强基线显著提升。由于大模型自带丰富的知识,因此选择小模型进行实验能更加明显地体现效果
3 Search-R1 方法
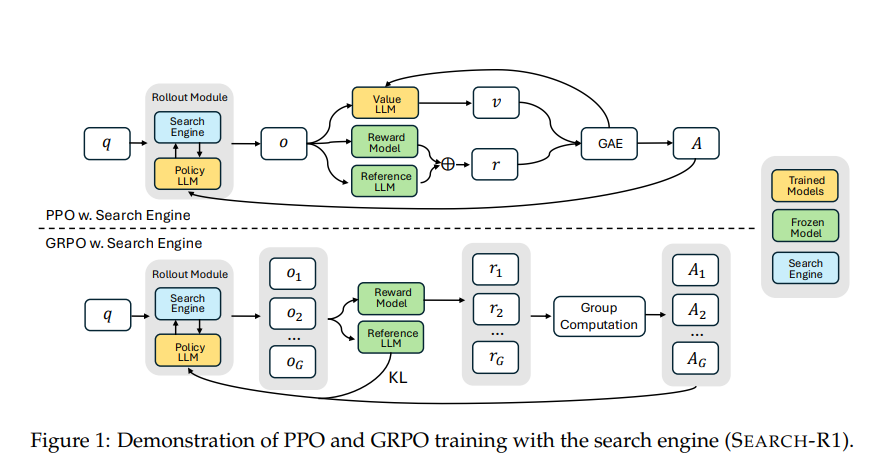
我先用简单但不太严谨的语言解释一下主图:上面是 PPO 方法(传统强化学习),下面是 GRPO 方法(DeepSeek 方法)。
上图中绿色的块是已知模型,黄色是训练过程中被调参的模型,蓝色为搜索引擎,白色是流动的数据。
先看 PPO:每个步骤的输入是 q,通过策略模型 Policy LLM 和搜索引擎 Search Engine,得到输出 o,把 o 代入价值评价模型 Value LLM(通过训练过程得到),奖励函数 Reward Model(已有)和参考策略 Reference LLM(现有的,效果还可以但不是最优的策略,可以理解为基于这个策略优化);通过它们计划出奖励 r 和价值 v,再代入 GAE 广义优势估计;然后一方面用其结果优化价值模型 ValueLLM,一方面得到下一步的行为 A;再进行下一步的策略选择和搜索,以此类推。
GRPO 与 PPO 不同的是:每一步计算出一组输出 o1…oG;这里省去了价值函数,而只有事先已知的奖励函数 Reward Model 和参考模型 Reference LLM。参考模型用于计算 KL 散度,作为惩罚项,以免模型变化太大;Reward Model 则用于评价组中每个输出的好坏,根据每组内输出的相对奖励计算优势(效果好的权重大),以此决定下一步的行为 A,再开始下一步的策略选择和搜索,以此类推。
3.1 使用搜索引擎进行强化学习
基本公式如下:
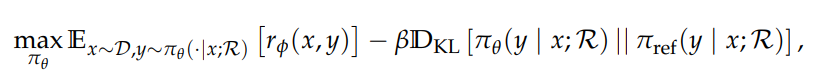
其中 πθ 是策略 LLM,πref 是参考 LLM,rφ 是奖励函数,DKL 是 KL 散度。公式中πθ(· | x; R) 显式地结合了检索交错推理(推理 + 检索),(注意:这里的大写 R 指的是搜索引擎,小写 r 是奖励函数)
3.1.1 计算 Loss 时遮蔽搜索结果
在基础的 PPO 和 GRPO 中,令牌级别的损失是在整个推出序列上计算的。在 SEARCH-R1 中,推出序列包括 LLM-generated token 和从外部通道中检索到的 token。虽然优化 LLM-generated token 增强了模型与搜索引擎交互和执行推理的能力,但对检索到的 token 应用相同的优化可能会导致意外的学习动力学(dynamics)问题。为了解决这个问题,我们为检索到的 token 引入了损失掩码,确保仅在生成的 token 上 LLM 计算策略梯度目标,从优化过程中排除检索到的内容。这种方法稳定了训练,同时保留了搜索增强生成的灵活性。
3.1.2 PPO + 搜索引擎
展示近端策略优化(PPO)是一种流行的 actor-critic 强化学习算法,它通常是在 RL 的场景下 finetune 大模型。在我们的推理加搜索引擎调用场景中,它通过最大化以下目标来 LLMs 优化:
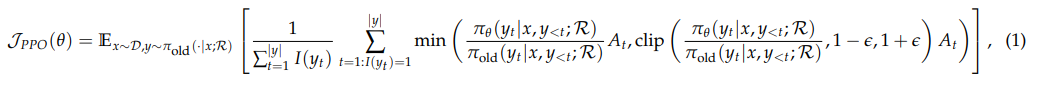
这里的 x 是输入样本,y 是模型输出,它结合了从搜索引擎 R 中检索; I(yt) 是上述的损失掩码操作,如果 yt 是 LLM 生成的令牌,则 I(yt)= 1,如果 yt 是检索到的令牌,则 I(yt)= 0。 ε 是 PPO 中引入的与剪辑相关的超参数(clip 用于截断,如果低于 1-ε,则使用 1-ε;如果超出 1+ε,则使用 1+ε,以避免过度变化),用于稳定训练。优势估计 At 是使用广义优势估计(GAE)计算的,基于未来奖励 {r≥t} 和已学习价值函数 Vφ。
3.1.3 GRPO + 搜索引擎
为了提高策略优化的稳定性并避免使用额外的价值函数近似,引入了群体相对策略优化(GRPO)。GRPO 与 PPO 的不同之处在于,它利用多个采样输出的平均奖励作为基线,而不是依赖学习到的值函数。具体来说,对于每个输入问题 x,GRPO 从参考策略 πref 中抽取一组响应 {y1,y2,…,yG}。然后通过最大化以下目标函数来优化策略模型:
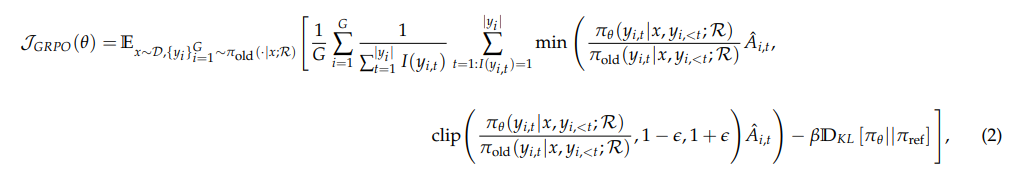
其中 ε 和 β 是超参数,ˆAi,t 表示优势,该优势是根据每组内输出的相对奖励计算的。这种方法避免了在 ˆAi,t 的计算中引入额外的复杂性,使用 I(yi,t)是令牌损失掩码作(计算方法同上)。此外,GRPO 通过将训练策略和参考策略之间的 KL 背离直接添加到损失函数中来进行正则化。在计算 KL 背离损失 DKL 时,也应用检索到的令牌掩码。
3.2 使用交错多轮搜索引擎调用生成文本
Rearch-R1 采用了一种迭代框架,其中 LLM
在文本生成和外部搜索引擎查询之间交替进行。具体来说,系统指令会引导 LLM
在需要外部检索时,将搜索查询封装在两个指定的搜索调用标记
<search> 和 </search>
之间。在生成的序列中检测到这些标记后,系统会提取搜索查询,向搜索引擎查询,并获取相关结果。检索到的信息会被放在特殊的检索标记
<information> 和 </information>
中,并附加到当前的展开序列里,作为下一步生成的附加上下文。这个过程会持续进行,直到以下任一条件满足:(1)搜索引擎调用的预算用尽,或(2)模型生成了最终响应,并将其封装在指定的答案标记
<answer> 和 </answer>
之间。完整的流程在算法 1 中进行了说明。

简单解释一下伪代码:首先初始化一个空的探索序列 y 和已用资源 b 为 0。在资源限制 B 内循环,直到找到答案(第 16 行判断是否找到答案),最终返回探索序列 y。核心在第 4-15 行:通过当前策略计算出当前步的 yt(可能包含 answer),将 yt 加入序列 y;若 yt 中指定需要搜索,则提取搜索内容 q,使用搜索引擎 R 搜索,并将搜索结果以 information 标签加入 y,同时增加资源消耗 b+1。
3.3 训练模板
输入给模型的提示如下:

3.4 奖励建模
采用基于规则的奖励系统,该系统仅由最终结果奖励组成,这些奖励评估模型响应的正确性。例如,在事实推理任务中,使用基于规则的标准(如精确字符串匹配)来评估正确性。
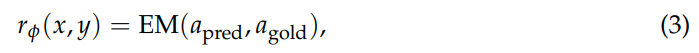
这里没有纳入格式奖励,因为学习的模型已经表现出很强的结构一致性。此外,故意避免训练神经奖励模型用于结果或过程评估。其动机是神经奖励模型在大规模强化学习中对奖励黑客攻击的敏感性,以及重新训练这些模型带来的额外计算成本和复杂性。
4 实验
SEARCH-R1 的性能始终优于强大的基线方法。使用 Qwen2.5-7B、Qwen2.5-3B 和 LLaMA3.23B 分别实现了 26%、21% 和 10% 的平均相对改进。
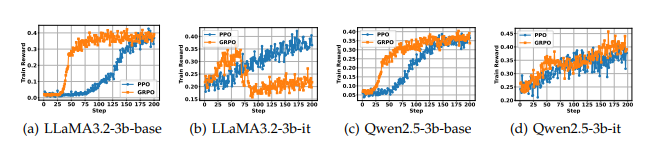
对比 PPO 和 GRPO 可见:GRPO 收敛快,PPO 相对更稳定。
分析原因:GRPO 收敛快是因为并行进行多种探索;PPO 一直与之前的模型做比较,所以不会跳变很快,更稳定;最终结果其实差不多。