论文阅读_GPT-4
name_ch: GPT-4 技术报告
name_en: GPT-4 Technical Report
paper_addr: https://arxiv.org/abs/2303.08774
date_publish: 2023-03-14
摘要
评测了 GPT-4:一个大规模的多模态模型,可以接受图像和文本输入并产生文本输出。
GPT-4 是一种基于 Transformer 的模型,它延续了 GPT-3 的结构,经过预训练可以预测文档中的下一个 token。训练后的对齐过程可提高真实性和遵守所需行为的措施的性能。
介绍
当前大语言模型的主要目标是提高模型理解和生成自然语言文本的能力,尤其是在更复杂和微妙的场景中。
模型在评估中多数超过绝大多数人类测试者,在这方面明显优于 GPT-3.5。尽管 GPT-4 生成的文本仍然不太可靠(提升了利用知识去解决具体问题的能力)。
模型训练具体使用了互联网数据和一些三方版权数据。然后使用人类反馈强化学习 (RLHF) 对模型进行微调。本报告不包含关于架构 (包括模型尺寸)、硬件、训练计算、数据集构建、训练方法或类似的更多细节。
方法
预测可扩展性
GPT-4 项目的一大重点是构建可预测扩展的深度学习堆栈。开发了基础设施和优化方法,这些方法在多个尺度上具有可预测的行为,使计算量缩小了 1000-10000 倍。
用小模型来预测某些参数组合下对应大模型的某种能力,如果预测足够精准,能够极大缩短炼丹周期,同时极大减少试错成本。
预测损失
计算量和模型的最终损失之间存在幂律关系。用此方法可以高精度地预测 GPT-4 的最终损失。
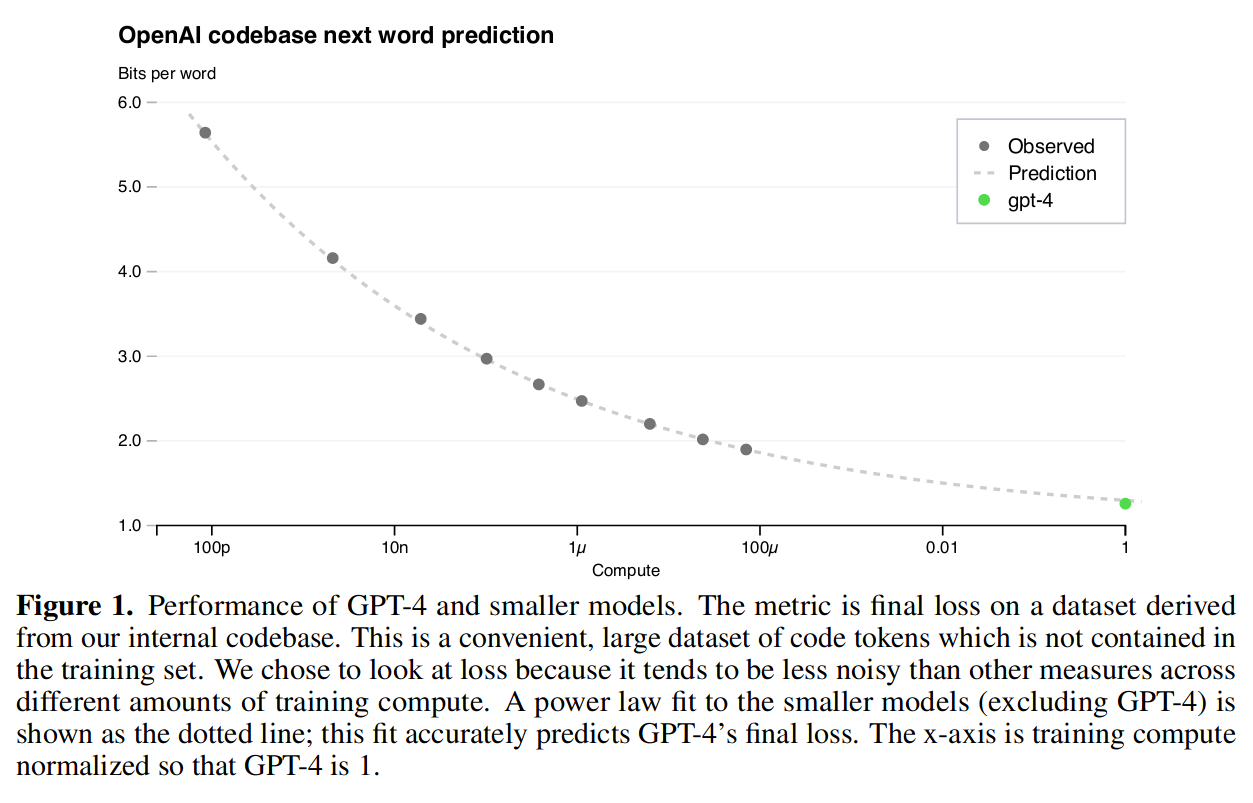
图中 X 轴用 GPT-4 做了归一化,p、n、μ是计量单位的前缀,表示 10 的负 12 次方、负 9 次方和负 6 次方。
预测 HumanEval 上的能力扩展
除了预测模型的损失,还想在训练前评估模型的其它能力。GPT-4 提出了 HumanEval 数据集,由 164 个编码问题组成,测试了编程逻辑和熟练程度的各个方面,将它作为另一个性能指标,并在训练之前对模型在 HumanEval 上的水平进行预测。同样也发现了类似幂律分布的情况。
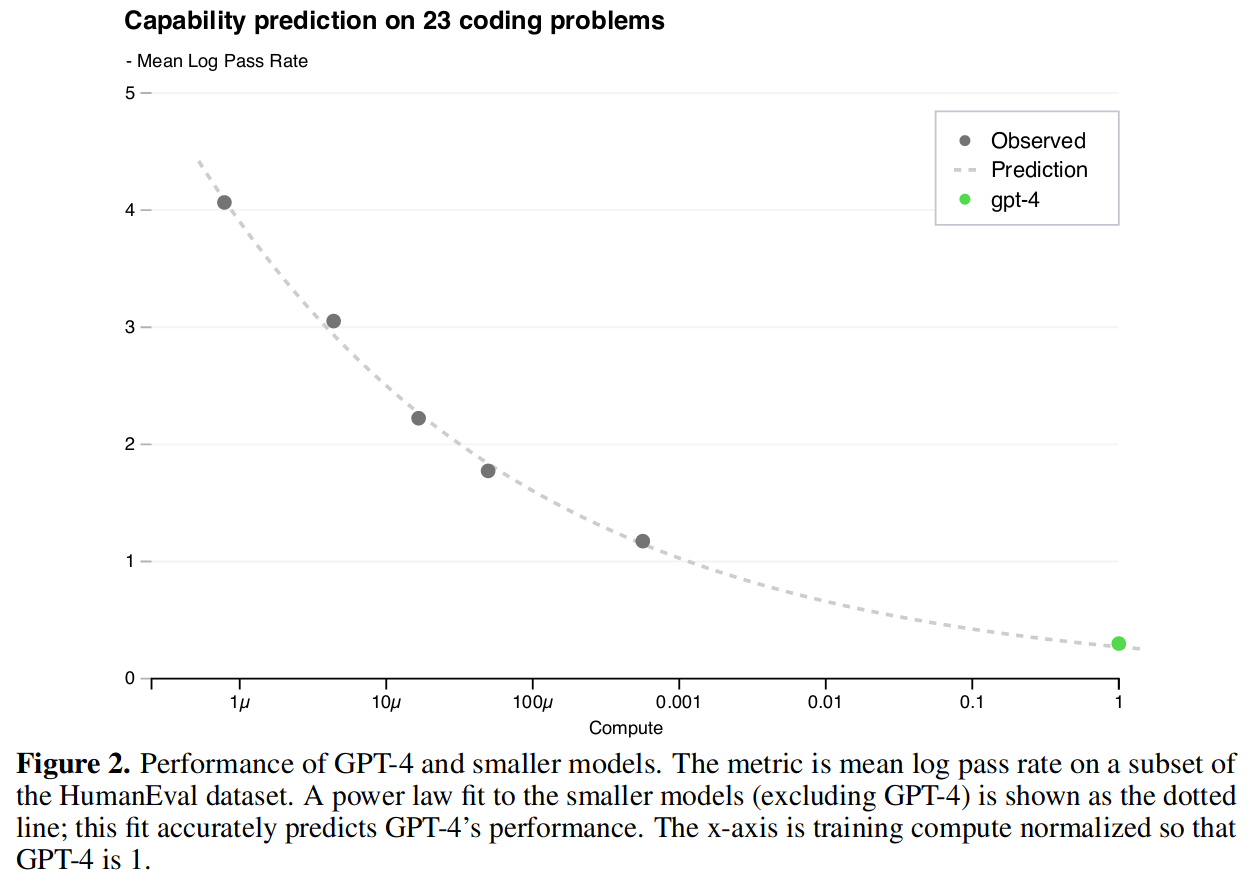
模型能力
对于非常复杂的指令,GPT-4 的理解能力和创造力远超 3.5。
GPT-3.5 与 GPT-4 在各种考试中得分比较
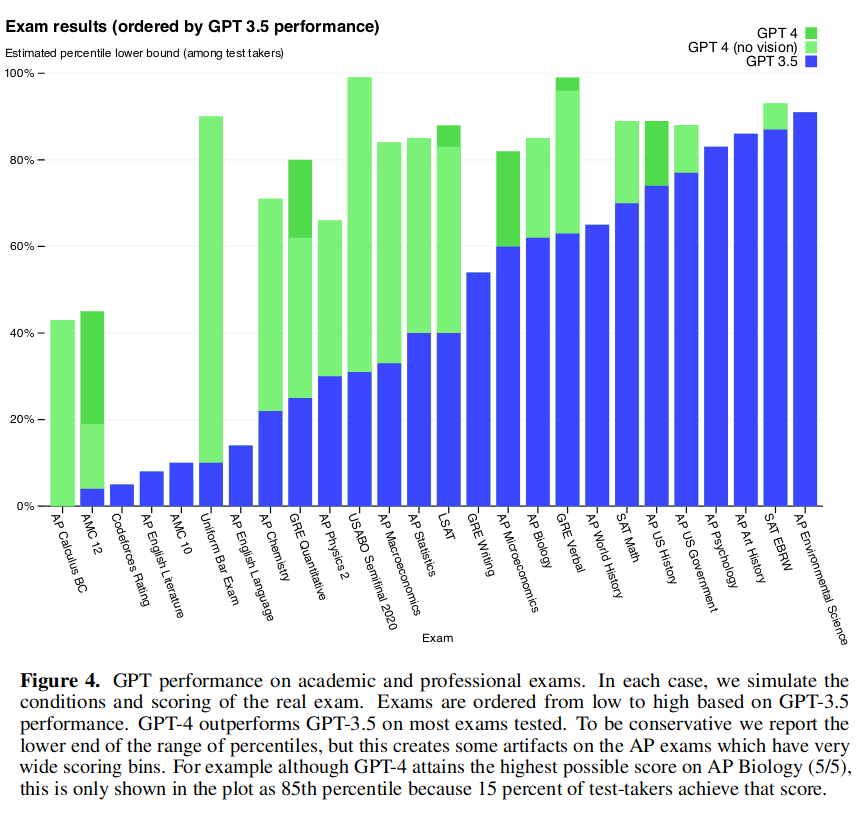
详见表 -1。
表 -2 列出了一些常用的自然语言评测方法,其中 MMLU 几乎是最常用的一个,GPT-4 在其上的得分,是其它模型无法比拟的。
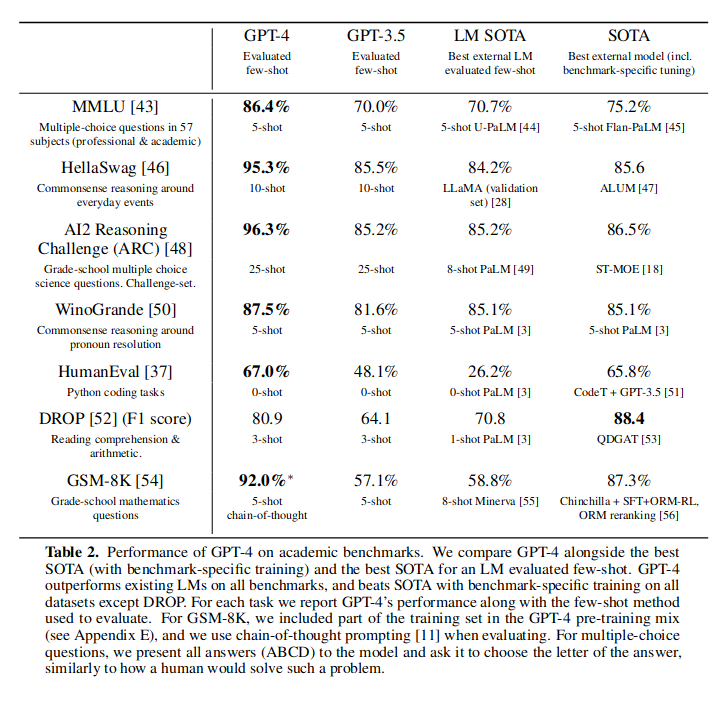
在 MMLU 测试英语以外的其它语种分数也非常高:
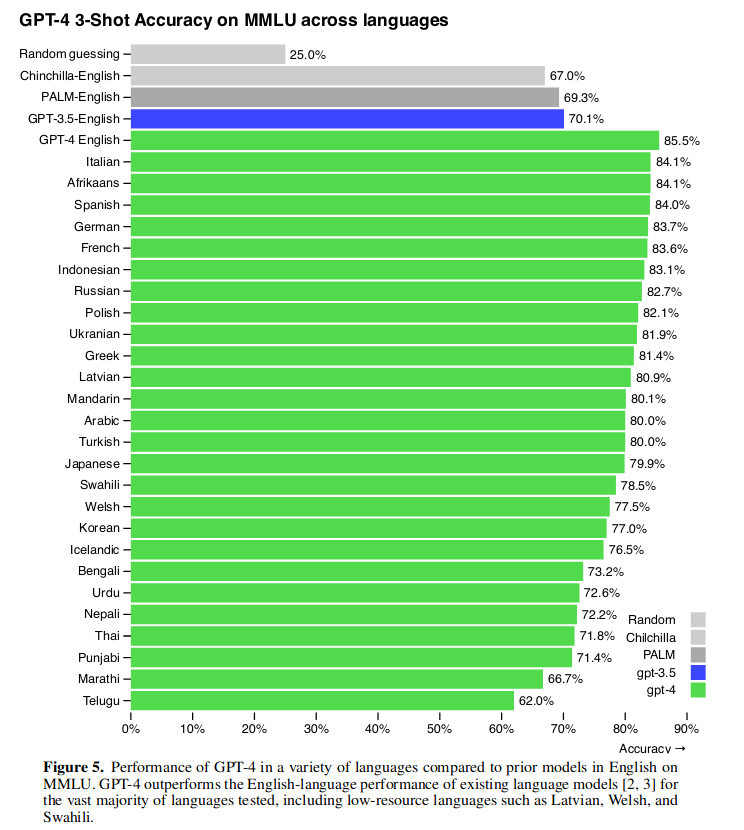
图 -3 还示例了将图片和文本作为输入,通过解释图中的幽默之处,展示了 GPT-4 对图的解释和推理能力。
图 -6 展示了 GPT-4 生成的文本真实性的测试,明显高于最新版本的 chatGPT。
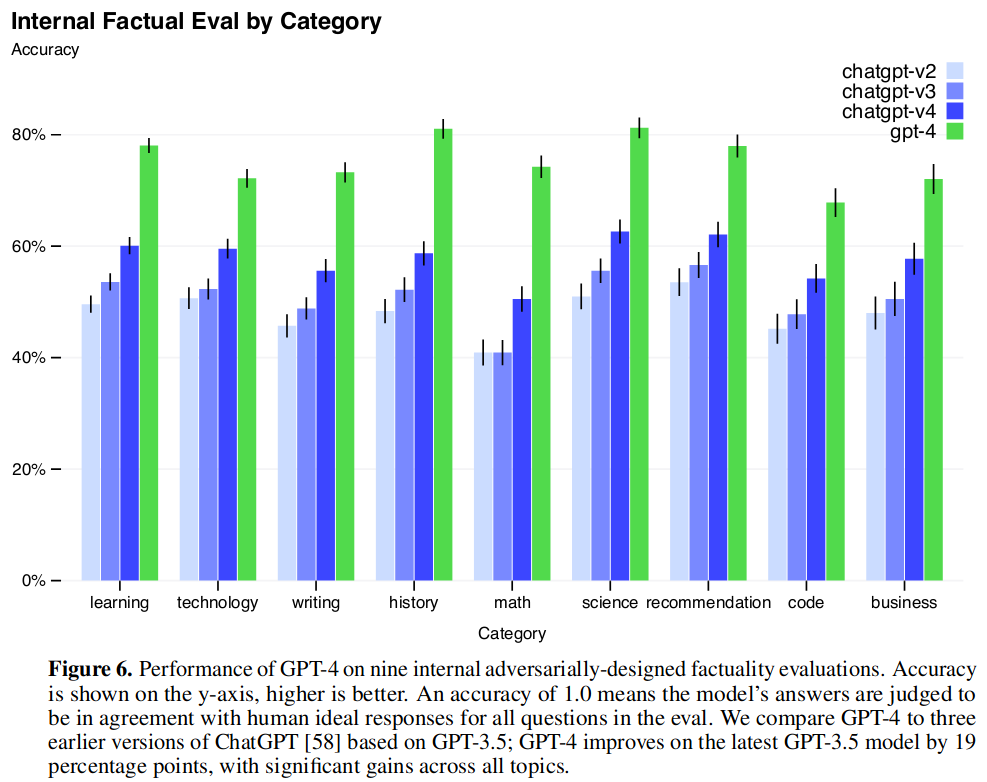
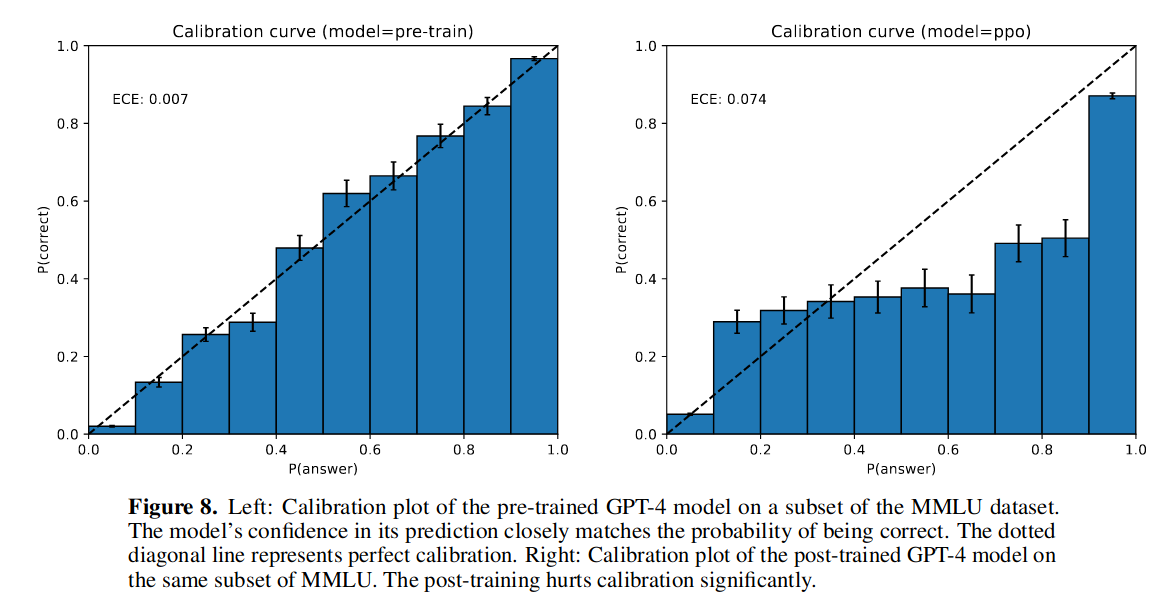
图 -8 还展示了预训练和强化学习后的校准曲线,可以看到强化学习后的分布与原始分布不再一致。
个人总结
GPT-4 优势
- 支持多模态
- 更擅长解决问题
- 更高的“事实性、可控性”
- 可使用更小计算量精调模型