语音方向精典论文品读_HuBERT
1 | 英文名称: HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units |
1 读后感
HuBERT 是一篇偏向底层技术的语音领域的精典论文。作者并没有针对具体的语音识别或语音转换的任务优化,HuBERT 研究成果却成为这些应用的基础。他的研究主要集中在语音和音频表征,即如何描述声音。除了语义信息外,声音还可以描述身份、情绪、犹豫、笑声、咳嗽声、咂嘴声、背景车辆声、鸟鸣声或食物嘶嘶声等。
为了处理没有见过的语言或无标注的语音数据,作者采用了自监督学习的方法。这种方法不需要语言相关的标注数据,同时保持了语言之外声音数据的丰富性。具体方法是,通过对转换后的隐变量进行聚类,将其划分为不同的类别。简当地说,他对未标注的语音数据,先提取特征,然后自动归类。
该方法的底层逻辑是,为了能够正确地聚类,模型中间过程生成的隐变量需要更好地表现声学和语言学的特征,从而得到了声音的表征。此外,由于声音信息的连续性,模型还需要对序列数据的前后关系进行建模。因此,这个问题不仅仅是一个声音小片段的聚类问题,更是一个声音表示学习问题。
2 摘要
目标:自监督语音表示学习的目的是解决三个问题:(1) 每个输入话语中有多个声音单元,(2) 在预训练阶段没有输入声音单元的词典,(3) 声音单元的长度不固定且没有明确的分割。
方法:利用离线聚类步骤为 BERT-like 预测损失提供对齐的目标标签。该方法的一个关键要素是在掩码区域上应用预测损失,这迫使模型在连续输入上学习组合的声学和语言模型。
结论:使用 1B 参数模型,HuBERT 在更具挑战性的 dev-other 和 test-other 评估子集上显示出高达 19% 和 13% 的相对 WER 降低。
3 引言
HuBERT 模型被迫从连续输入中学习声学和语言模型。首先,模型需要将未掩蔽的输入建模为有意义的连续潜在表示,这对应于经典的声学建模问题。其次,为了减少预测误差,模型需要捕获学习表示之间的长期时间关系。模型除了训练正确的聚类,在过程中还训练模型表征的一致性,这使得模型能很好地对输入数据的序列结构建模。
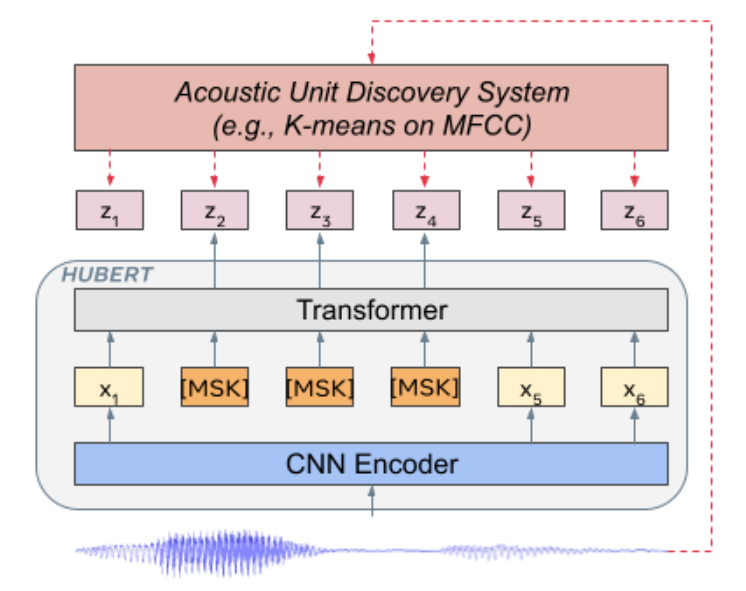
HuBERT 全称为 Hidden unit BERT(HuBERT)。它是一种类似于 BERT 的预训练模型,通过离线聚类生成有噪标签的隐藏单元。
HuBERT 模型被迫从连续输入中学习声学和语言模型。首先,模型需要对未掩蔽的输入建模为有意义的连续潜在表示,这对应于经典的声学建模问题。其次,在对掩蔽的输入建模时,模型需要捕获学习表示之间的长期时间关系。在训练过程中,除了训练正确的聚类,模型还训练模型表征的一致性,这使得模型能够很好地对输入数据的序列结构进行建模。
4 方法
与半监督学习相比,自监督学习无需任何标注数据,只使用纯音频即可训练。
4.1 学习 HuBERT 的隐藏单元
HuBERT
以帧为单位处理声学单元。用 X 表示 X=[x1,⋯,xT] 的 T 帧的音频。隐藏单元用 ℎ(X)=Z=[z1,⋯,zT] 表示,其中
z 的取值 zi∈[C] C 是 C-class
分类变量(可视为聚类后的类别),且 h 是聚类模型, 例如 k-means。
4.2 基于蔽码预测的表示学习
用 M 表示 T 帧的索引集,X^表示遮蔽后的音频,模型用于预测每个时间步 t 上的目标索引帧所对应类别的分布。
遮蔽方法采用了与 SpanBERT 和 wav2vec 2.0 相同的策略来生成掩码,其中随机选择 p% 的时间步作为起始索引,并屏蔽 l 步长的跨度。误失函数是将在屏蔽和未屏蔽时间步长上计算的交叉熵损失分别表示为 Lm 和 Lu :
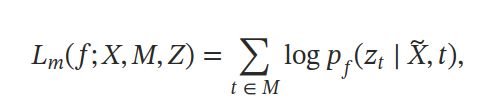
最终的损失函数是二者的加和:
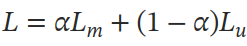
当 a 为 0 时,仅关注可以看到的帧,类似于混合语音识别系统中的声学建模,更注重对音频特征的提取;在 a 为 1 时,仅对遮蔽的帧建模,类似于语言建模,更注重前后帧之前的关系长跨度的时序结构。通过设置 a 结合二者。
4.3 学习聚类
利用多个聚类模型提升效果,可以创建具有不同码本大小的 k 均值模型集合,从而实现不同粒度的目标。这些目标可以从方式类(元音/辅音)到子音状态进行划分,即将单个 Z 变成了 k 个聚类 Z(k)。
4.4 迭代细化聚类
除了聚类功能,模型的另一个目标是希望预训练模型能够提供比原始声学特征(如 MFCC)更优质的表示。我们可以通过在学习到的潜在表示上训练一个离散的潜在模型来创建一个新的聚类。随后,学习过程将继续利用新发现的单元。
4.5 实现
预训练模型遵循 wav2vec 2.0 架构,包括一个卷积波形编码器,一个 BERT 编码器,一个投影层和一个代码嵌入层。我们考虑了三种不同的 HuBERT 配置:Base,Large 和 X-Large。前两者紧密遵循 wav2vec 2.0 Base 和 Large 的架构。X-Large 架构将模型大小扩展到约 10 亿个参数。BERT 编码器由许多相同的 Transormers 块组成。
卷积波形编码器为 16kHz 采样的音频生成一个 20ms 帧率的特征序列(CNN
编码器的下采样因子是 320 倍)。然后,对音频编码的特征进行随机掩蔽。BERT
编码器接受掩蔽的序列作为输入,并输出一个特征序列
[o1,⋯,oT]。codewords 上的分布是参数化的:
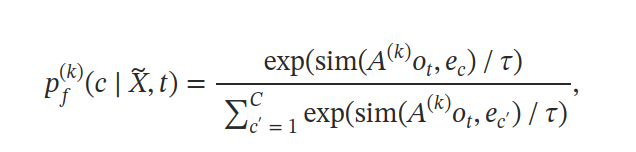
其中 A 是投影矩阵,ec是 codeword 的嵌入,sim(⋅,⋅) 计算两个向量之间的余弦相似度,τ为缩放参数设置为 0.1。当使用聚类时,将为每个聚类模型 k 应用一个投影矩阵 A(k)。