论文阅读_扩散模型_DM
英文名称: Deep Unsupervised Learning using Nonequilibrium Thermodynamics
中文名称: 使用非平衡热力学原理的深度无监督学习
论文地址: http://arxiv.org/abs/1503.03585
代码地址: https://github.com/Sohl-Dickstein/Diffusion-Probabilistic-Models
时间: 2015-11-18
作者: Jascha Sohl-Dickstein, 斯坦福大学
引用量: 1813
1 读后感
论文目标是建立灵活且易用的数据生成模型。它利用非平衡统计物理学原理:通过扩散过程(少量加噪)系统地、缓慢地破坏数据分布中的结构;然后,学习反向扩散过程,恢复数据结构。
2 介绍
2.1 扩散模型与变分模型
扩散模型与变分模型原理类似,都是将图片拆成一系列高斯分布的均值和方差,而扩散模型是一个逐步变化的过程,主要差别如下:
- 原理不同:扩散模型使用物理学、准静态过程和退火采样的思想。由于任何平滑目标分布都存在扩散过程,因此理论上该方法可以捕获任意形式的数据分布。
- 展示了用简单的乘法,将一个分布逐步转换为另一分布的过程。
- 解决了推理模型和生成模型之间目标的不对称性,将正向(推理)过程限制为简单的函数形式,反向(生成)过程将具有相同的函数形式。
- 可训练具有数千层(时间步) 的模型。
- 精细控制每层中熵产生的上限和下限。
3 方法
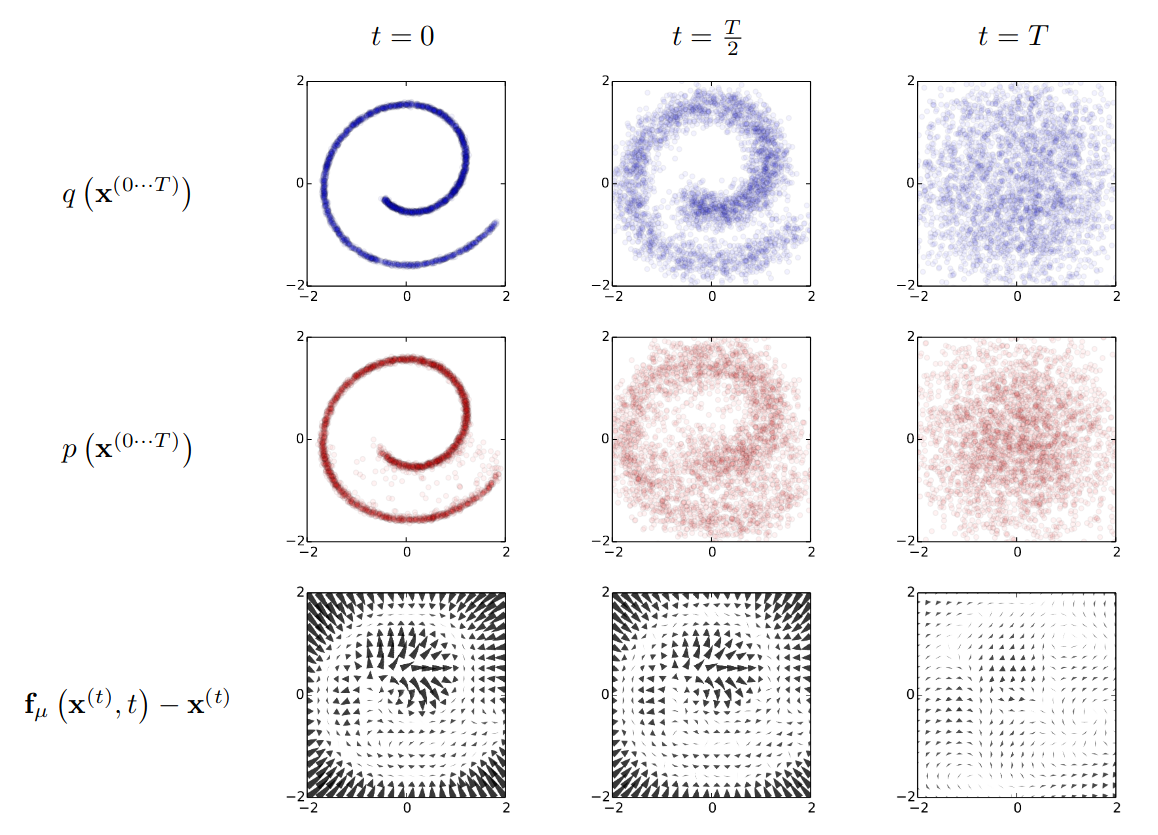
请记住图中这些符号,很多后续文章都延用了这些符号的定义。
3.1 向前轨迹
其中蓝色是扩散过程,从左往右看,总共 T 步,每步加一点高斯噪声,将瑞士卷图扩散成了高斯分布,扩展过程设为 q。每步都根据上一步数据而来:
\[ q\left(\mathbf{x}^{(0 \cdots T)}\right)=q\left(\mathbf{x}^{(0)}\right) \prod_{t=1}^{T} q\left(\mathbf{x}^{(t)} \mid \mathbf{x}^{(t-1)}\right) \] ### 3.2 反向轨迹
中间红色部分是扩散的逆过程,从右往左看,图片逐步恢复,恢复过程设为 p;在训练过程中,通过学习高斯扩散的逆过程,使数据转换回原分布,从而生成数据。
\[ p\left(\mathbf{x}^{(0 \cdots T)}\right)=p\left(\mathbf{x}^{(T)}\right) \prod_{t=1}^{T} p\left(\mathbf{x}^{(t-1)} \mid \mathbf{x}^{(t)}\right) \]
最后一行展示了反向扩散过程的漂移项。fμ (x(t), t) 是高斯逆马尔可夫转移的均值和协方差的函数。
扩散的原理是通过马尔可夫链逐渐将一种分布转换为另一种分布。最终,估计概率分布的任务简化为对高斯序列的均值和协方差函数的回归任务(这里的 0 状态指的是原始图,T 状态指高斯分布图);由于扩散链中的每个步骤都具有可分析评估的概率(对比正向和反向变化中每一步数据的相似度),因此也可以对整个链进行分析评估。
3.3 模型概率
计算将图像恢复成原图的概率,可拆解成每一步变化的累积。
\[ \begin{aligned} p\left(\mathbf{x}^{(0)}\right)= & \int d \mathbf{x}^{(1 \cdots T)} p\left(\mathbf{x}^{(0 \cdots T)}\right) \frac{q\left(\mathbf{x}^{(1 \cdots T)} \mid \mathbf{x}^{(0)}\right)}{q\left(\mathbf{x}^{(1 \cdots T)} \mid \mathbf{x}^{(0)}\right)} \\ = & \int d \mathbf{x}^{(1 \cdots T)} q\left(\mathbf{x}^{(1 \cdots T)} \mid \mathbf{x}^{(0)}\right) \frac{p\left(\mathbf{x}^{(0 \cdots T)}\right)}{q\left(\mathbf{x}^{(1 \cdots T)} \mid \mathbf{x}^{(0)}\right)} \\ = & \int d \mathbf{x}^{(1 \cdots T)} q\left(\mathbf{x}^{(1 \cdots T)} \mid \mathbf{x}^{(0)}\right) \\ & p\left(\mathbf{x}^{(T)}\right) \prod_{t=1}^{T} \frac{p\left(\mathbf{x}^{(t-1)} \mid \mathbf{x}^{(t)}\right)}{q\left(\mathbf{x}^{(t)} \mid \mathbf{x}^{(t-1)}\right)} \end{aligned} \]
3.4 训练
具体方法是计算熵 H 和 KL 散度。其推导与变分贝叶斯方法中对数似然界限的推导类似。DK 散度描述了每一时间步数据分布的差异,熵描述了数据的混乱程度。
\[ \begin{aligned} L & \geq K \\ K= & -\sum_{t=2}^{T} \int d \mathbf{x}^{(0)} d \mathbf{x}^{(t)} q\left(\mathbf{x}^{(0)}, \mathbf{x}^{(t)}\right) . \\ & D_{K L}\left(q\left(\mathbf{x}^{(t-1)} \mid \mathbf{x}^{(t)}, \mathbf{x}^{(0)}\right) \| p\left(\mathbf{x}^{(t-1)} \mid \mathbf{x}^{(t)}\right)\right) \\ & +H_{q}\left(\mathbf{X}^{(T)} \mid \mathbf{X}^{(0)}\right)-H_{q}\left(\mathbf{X}^{(1)} \mid \mathbf{X}^{(0)}\right)-H_{p}\left(\mathbf{X}^{(T)}\right) . \end{aligned} \]
设置扩散率 βt
热力学中,在平衡分布之间移动时所采取的时间表决定了损失多少自由能。简单地说,就是如何设置每一步变化的大小。一般情况下,第一步β设成一个很小的常数,以防过拟合,然后 2-T 步逐步扩大。将在之后的 DDPM 中详述。
3.5 乘以分布计算后验
对大多数模型而言,乘以分布计算量大,而在扩散模型中则比较简单,第二个分布可以被视为扩散过程中每个步骤的小扰动。