论文阅读_语音合成_VITS
1 | 英文名称: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech |
1 读后感
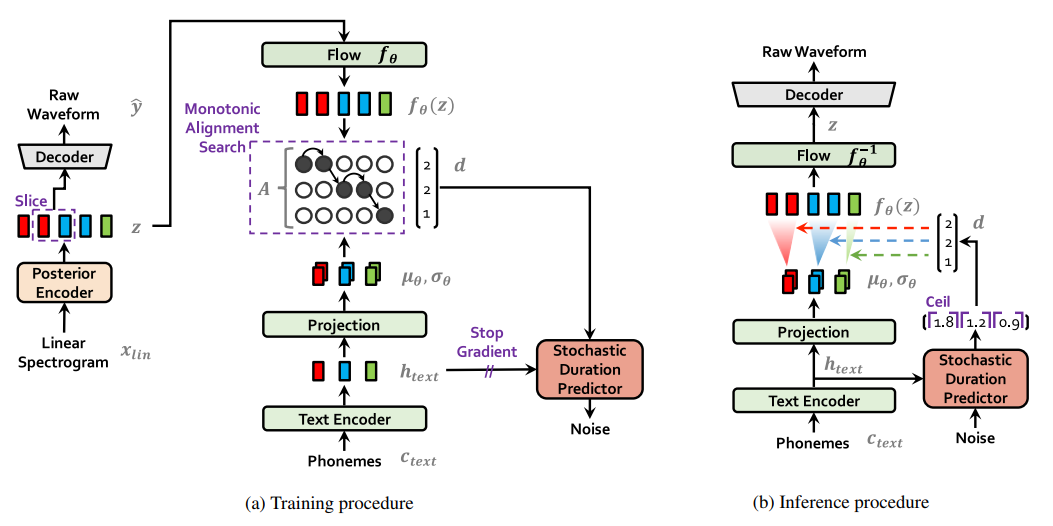
简单地说,在训练过程中将语音数据和相应的文本输入模型,让模型学习这两者之间的关系。整个逻辑结构是一个大的变分自编码器,具体细节请参考方法的 VAE 部分。
如图所示,在训练阶段,音素(Phonemes)可以被简单理解为文字对应的拼音或音标。它们经过文本编码(Text Encode)和映射(Projection)后,生成了文本的表示形式。左侧的线性谱(Linear Sepctrogram)是从用于训练的音频中提取的 wav 文件的音频特征。这些特征通过后验编码器(Posteritor)生成音频的表示,然后通过训练对齐这两者(在模块 A 中)。节奏也是表达的重要因素,因此还加入了一个随机持续时间预测器(Stochasitic Duration Predictor)模块,根据音素和对齐结果对输出音频长度进行调整。
在推理过程中,输入是文本对应的音素。将映射和对长度采样输入模型,将其转换为语音表示流,然后通过解码器将其转换为音频格式。
根据论文中描述的逻辑,文本数据被转换为音素(即词的拼音)并输入模型。模型学习了音素与音频之间的关系,包括说话者的音质、音高、口音和发音习惯等。并未涉及到具体内容的情感表达。
2 摘要
目标:提出一种可并行的端到端文本到语音(TTS)方法,生成比当前的两阶段模型更自然的音频。
方法:采用变分推断和归一化流以及对抗训练过程,提高生成建模的表达能力。同时,提出了一种随机持续时间预测器,用于从输入文本中合成具有不同节奏的语音。
结论:通过对 LJ Speech 数据集进行主观人类评估(平均意见分数,MOS),表明文中方法优于最好的公开可用 TTS 系统,并达到与真实语音相当的 MOS。
3 引言
先前的文本到语音(TTS)系统的流程常被定义为两个阶段的生成建模,除了文本规范化和音素化等预处理步骤:首先,生成中间语音表示,比如梅尔频谱图或其他语言特征;其次,根据这些中间表示生成 wav 波形。这两个阶段的模型是独立进行开发的。
然而,神经网络自回归的文本转语音(TTS)系统的顺序生成过程并不能充分利用并行处理器的优势,需要进行顺序训练或微调。另外,生成对抗网络(GAN)也在这种两阶段模型中被探索使用,以实现高质量的波形合成。
本文提出了一个并行的端到端的 TTS 方法,其目标是比现有的两阶段模型更自然地生成音频。采用了变分自动编码器(VAE)作为潜在变量,并将其与 TTS 系统的两个模块相连接,以实现高效的端到端学习。还应用了归一化流技术来处理在波形领域的条件先验分布,并采用对抗训练方法进行优化。此外,还提出了一个随机的持续时间预测器,能够通过输入文本来捕捉那些无法通过文本表示的语音变化。
4 方法
4.1 变分推理
VITS 可以表示为条件 VAE(原理见:论文阅读_生成模型_VAE)。设条件为 c(文本),潜变量为 z(模型内部表示),目标是生成 x(音频)。
\[ \log p_{\theta}(x \mid c) \geq \mathbb{E}_{q_{\phi}(z \mid x)}\left[\log p_{\theta}(x \mid z)-\log \frac{q_{\phi}(z \mid x)}{p_{\theta}(z \mid c)}\right] \]
上述公式可以简单地理解为,希望从文本 c 生成音频 x(公式左侧),但由于这个过程很难直接实现,因此将其转换为(公式右侧):在给定潜变量 z 的条件下求音频 x(数据点 x 的似然函数),在给定音频 x 的条件下求潜变量 z(近似后验分布),以及在给定文本 c 的条件下求潜变量 z(在给定条件 c 的情况下潜变量 z 的先验分布)。
4.1.1 重构损失
这里重构目标数据使用的是梅尔频谱图(mel),而非原始波形,用 xmel 来表示,最后再通过解码器生成最终的波形 y。重构的目标函数就是计算预测的 mel 和实际的 mel 之间的差异。
音频与 mel 的映射不需要训练参数,可以通过短时傅立叶变换(STFT)和在梅尔尺度上的线性投影来进行计算(可以简单地将 mel 视为音频的特征,它通过公式从音频中提取;也可以通过 mel 来还原音频)。
4.1.2 KL 散度
音素与潜在变量之间的对齐 A 是一个具有 ∣Ctext∣×∣z∣ 维度的硬单调注意矩阵。由于 z 是潜在变量,这里的对齐并没有精确的标准,因此必须在每次训练迭代时估计对齐。
本步骤的目标是使后验编码器提供更高的分辨率,因此我们使用目标语音 xlin 的线性尺度谱图,而非梅尔谱图作为输入。
\[ \begin{array}{l} L_{k l}=\log q_{\phi}\left(z \mid x_{\text {lin }}\right)-\log p_{\theta}\left(z \mid c_{\text {text }}, A\right) \\ z \sim q_{\phi}\left(z \mid x_{\text {lin }}\right)=N\left(z ; \mu_{\phi}\left(x_{\text {lin }}\right), \sigma_{\phi}\left(x_{\text {lin }}\right)\right) \end{array} \]
4.2 对齐估计
4.2.1 单调对齐搜索
为了估计输入文本和目标语音之间的对齐 A,文章中采用了单调对齐搜索(Monotonic Alignment Search,MAS)。对齐被约束为单调且非跳跃的(不会有重复和遗漏的内容)。文章中对 MAS 进行了重新定义,目标是找到一种最大化证据下界(Evidence Lower BOund,ELBO)的对齐方式,这可以简化为寻找一种最大化潜变量对数似然度的对齐方式。
4.2.2 基于文本的时长预测
目标是计算每个文本 token 的输出时长 d,如果用矩阵 A 的输出计算长度,不能表达一个人每次说话速度不同的方式。为了产生类似于人类的语音节奏,设计了一个随机持续时间预测器,使其样本给定音素的持续时间分布。具体引入了两个随机变量 u 和 v ,它们具有与持续时间 d 相同的时间分辨率和维数,分别用于变分去量化和变分数据增强。
\[ \begin{array}{l} \log p_{\theta}\left(d \mid c_{\text {text }}\right) \geq \\ \mathbb{E}_{q_{\phi}\left(u, v \mid d, c_{\text {text }}\right)}\left[\log \frac{p_{\theta}\left(d-u, v \mid c_{\text {text }}\right)}{q_{\phi}\left(u, v \mid d, c_{\text {text }}\right)}\right] \end{array} \]
4.3 对抗训练
生成对抗网络(GAN)的概念源于对抗学习,GAN 由生成器和鉴别器组成。生成器负责生成数据,例如语音,而鉴别器则负责区分生成的语音与真实语音之间的差异。通过迭代训练让这种差异逐渐减小,以提高模拟效果。中文采用了对抗训练的方法,添加了一个鉴别器 D,以优化语音合成。
4.4 最终损失函数
结合 VAE 和 GAN,损失函数可以表示:
\[ L_{\text {vae }}=L_{\text {recon }}+L_{k l}+L_{\text {dur }}+L_{\text {adv }}(G)+L_{f m}(G) \]
其中 Lavd 和 Lfm 是 GAN 损失,Ldur 为时间预测损失,Lkl 为 kl 散度,Lrecon 为重建损失。
4.5 整体框架
4.5.1 后验编码器
这里的后验编码器主要用于处理音频,因此只在训练阶段使用。文章中采用了 WaveGlow 中的非因果 WaveNet 残差块和 Glow-TTS 作为后验编码器。对于多说话人的情况,通过在残差块中添加说话人嵌入,使用全局条件。
4.5.2 先验编码器
先验编码器由文本编码器和归一化流程(图中的三个绿色模块)构成。文本编码器采用了 Transformer 编码器,并使用了相对位置表示。通过文本编码器及其顶部的线性投影层,可以获得隐藏表示 htext。归一化流程则是通过堆叠仿射耦合层和 WaveNet 残差块实现的。对于多说话人的情况,可以通过全局调制将说话人嵌入添加到归一化流程中的残差块中,以增强模型的灵活性。
4.5.3 解码器
解码器由一系列的转置卷积层构成,每个转置卷积层后都接有一个多感受野融合模块(MRF)。MRF 的输出是由不同感受野大小的残差块的输出相加得到的。对于多说话者的环境,还添加了一个线性层,用于转换说话者的嵌入,并将其加入到输入的潜变量中。
4.5.4 识别器
文章中的识别器采用了 HiFi-GAN 中提出的多周期并行计算架构,这种多周期鉴别器是基于马尔可夫窗口的子鉴别器的混合,其中每一个操作都对输入波形的不同周期模式进行识别。
4.5.5 随机时长预测器
随机时长预测器从条件输入 htext 中估计音素持续时间的分布。
5 实验
主实验结果如下:
