论文阅读_大型语言模型增强强化学习调查
1 | 中文标题:Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods |
来自:241011 哲明分享
摘要
目标: 提供对大型语言模型(LLMs)增强强化学习(RL)相关文献的全面综述,明确其与传统 RL 方法的对比,澄清研究范围和未来研究方向。
方法: 基于经典的代理 - 环境互动范式,提出结构化分类法,将 LLMs 在 RL 中的功能系统地划分为信息处理器、奖励设计者、决策者和生成器四个角色。逐一总结方法、分析所缓解的 RL 挑战,并提供未来研究的见解。
结果: 提出了一个用于分类 LLM 在 RL 中角色的框架,讨论了各角色间的对比分析、潜在应用、未来机遇和挑战。期望能加速 LLM 在复杂应用中的 RL 落地,如机器人技术、自动驾驶和能源系统。
读后感
这是一篇综述性论文,主要研究 LLM 帮助训练和提升强化学习模型。这篇论文从四个方面讨论了 LLM 对 RL 的加强。
提出了将表示学习与 RL 解耦,从而拆分了 LLM 和 CV 与控制决策模块;这里主要讨论使用 LLM 提升控制和决策能力,最终提升了 RL 整体能力。这里的 LLM 是用于帮助训练模型,而非用于直接决策。
1 引入
有论文提出结合语言和视觉能力的深度强化学习(RL)面临四大挑战:
- 样本效率低下
- 奖励函数设计复杂
- 泛化问题
- 自然语言理解难题
2 背景
2.1 强化学习
2.1.1 经典强化学习
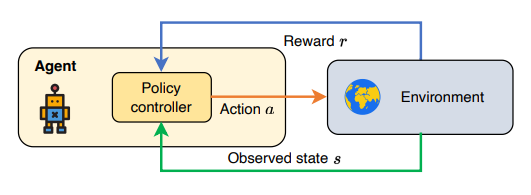
图 1:经典的强化学习范式。
2.1.2 强化学习的挑战
- 不可见环境中的泛化:实际环境很少是静态或完全可预测的。
- 奖励函数设计:尤其是在稀疏奖励环境和复杂场景中,大多数设计的奖励都是次优的,可能导致意外行为。
- 基于模型的规划中的复合误差:模型预测中的误差不断累积,导致与最佳轨迹出现重大偏差。
- 多任务学习:简单任务可能掩盖对更复杂任务的学习,导致负迁移。任务之间共享参数或数据可能导致单个任务性能不佳。
2.1.3 多模态强化学习
自然语言在强化学习中的使用可以分为以下两类:
- 语言条件强化学习:通过自然语言与环境交互。代理在解释指令后执行动作,也可将自然语言作为状态或动作空间的一部分,用于文字游戏、对话系统等任务中,直接指导代理操作与决策。
- 语言辅助强化学习:通过自然语言促进学习,但不直接用于问题制定。可传达领域知识,如任务相关文本帮助代理;通过语言构建策略,用抽象指令引导代理行为,间接增强强化学习任务的执行。
2.2 大语言模型
大模型在上下文学习、推理和泛化能力方面对强化学习有帮助。
- 上下文学习:将与任务相关的文本作为上下文信息包含在提示中,帮助大型语言模型(LLMs)理解情况并执行指令。
- 指令遵循:利用以自然语言描述格式化的各种特定数据集,使 LLMs 能够理解新任务指令,并有效泛化到以前未遇到的任务。
- 循序渐进推理:将解决问题过程构建为顺序或分层步骤,从而促进更清晰易懂的推理路径。
3 大型语言模型 经典的强化学习范式
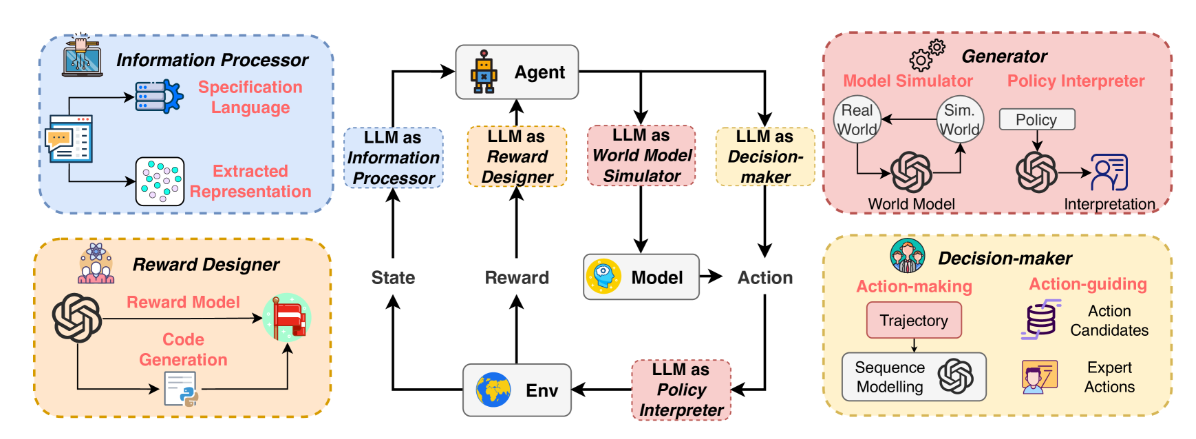
图 2:经典代理 - 环境交互中的 LLM 增强 RL 框架,LLM 在增强 RL 中起着不同的作用。
4 信息处理者
预训练的 LLM 或视觉语言模型(VLM)具备强大的表示能力和先验知识,可以作为强化学习(RL)的信息处理者。这提高了样本效率和零样本性能,使代理能够在不同且奖励稀疏的环境中有效泛化。
4.1 特征表示提取器
预训练的 LLM 或 VLM 模型可以凭借其强大的表示能力和先验知识,作为 RL 的信息处理器,从而解耦信息处理任务和控制任务。
4.1.1 特征表示提取器
通过采用计算机视觉(CV)和自然语言处理(NLP)中的大型预训练模型,其学习到的特征表示可以作为下游网络学习的基础嵌入,提升样本效率。冻结或微调 LLM 可以为下游 RL 网络提取有意义的表示。
4.1.2 语言翻译器
LLM 能将自然语言信息翻译成强化学习模型可以理解的形式,如特征表示或任务特定语言,从而辅助 RL 代理进行学习。这包括指令信息翻译和环境信息翻译。
5 奖励设计者
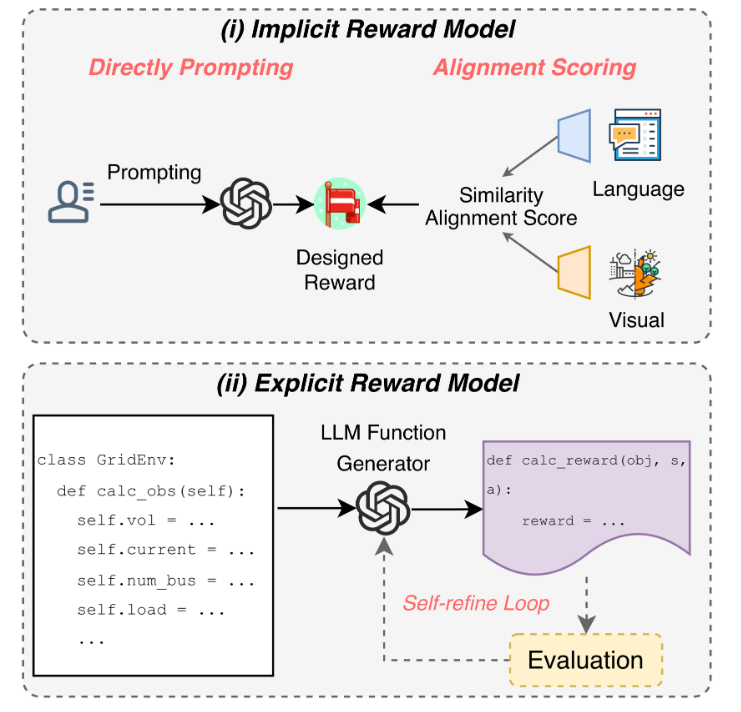
图 4:LLM 作为奖励设计者。(i)隐性奖励模型:LLM 提供基于语言指令与视觉观察之间直接提示或对齐评分的奖励。(ii)显式奖励模型:LLM 为奖励函数生成可执行代码,并通过评估循环进行自我优化。
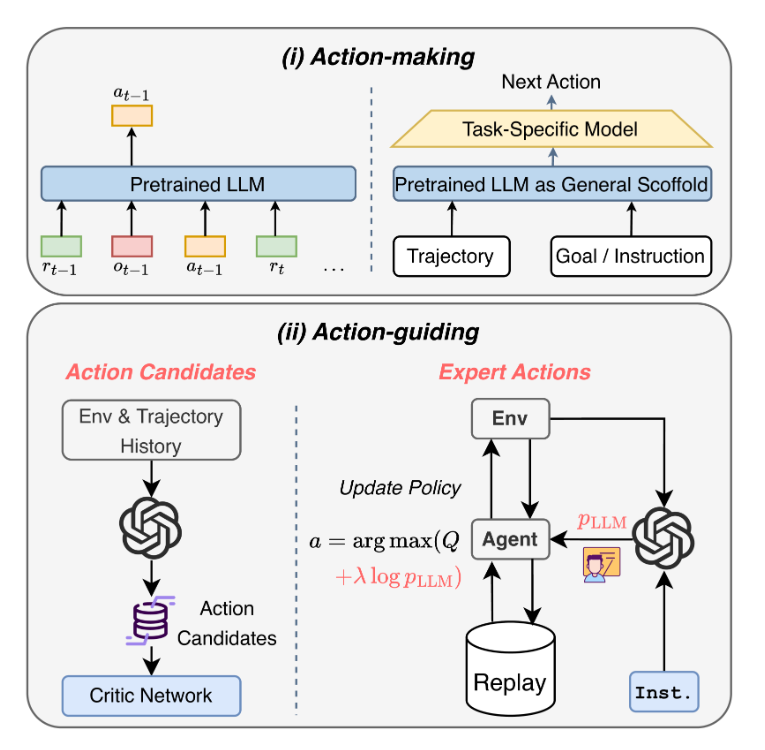
6 决策者
基于 LLM 在决策问题中的潜力,LLM 可用于:
- 动作生成;
- 动作指导:
- 操作备选项:简化动作空间,LLM 通过生成合理候选行动或专家行动来指导行动选择。
- 专家操作:基于对人类行为和常识的理解,LLM 产生高质量专家行动以规范 RL 代理解决问题。
7 生成器
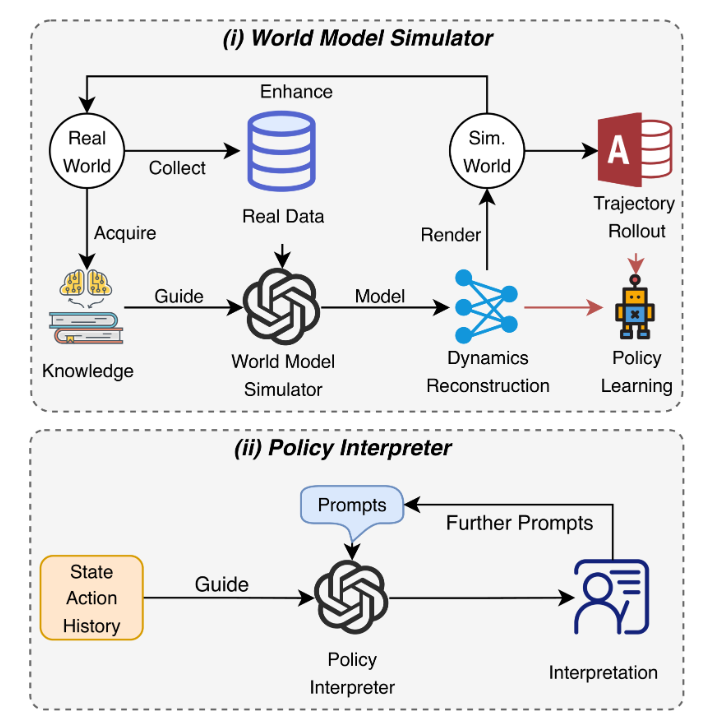
LLMs 可以应用于环境模拟和行为解释。
- 世界模型模拟器:LLM 使用真实世界的数据和知识来模拟动态,生成模拟世界,并协助政策学习。
- 策略解释器:LLM 根据状态操作历史记录和提示生成代理行为的解释,这可能会导致可解释的 RL。