使用大型语言模型预测中文咨询对话中的大五人格特质
1 | 英文名称:Predicting the Big Five Personality Traits in Chinese Counselling Dialogues Using Large Language Models |
1 摘要
- 目标:准确评估人格特征的传统方法耗时且有偏见,探讨大型语言模型能否直接从咨询对话中预测大五人格特征,并提出了一种创新框架来执行该任务。
- 方法:框架通过角色扮演和问卷提示将大型语言模型应用于咨询会话,模拟客户对大五人格量表的反应。对 853 个真实咨询会话进行了评估,并通过细化优化与监督微调的 Llama3-8B 模型提升预测精度。
- 结论:实验显示,模型预测的大五特征与实际特征具有显著相关性,验证了框架的有效性。改进的模型在人格预测有效性方面超越了现有的 Qwen1.5-110B,提升了 36.94%。
读后感
通过直接使用用户与咨询师的对话来对大五人格特征的各个维度(OCEAN)进行评分的效果并不理想,因此采用了 BFI 问题和角色扮演的方式,有效提升了 LLM 的评测效果。
该方法能够通过历史对话深入了解一个人的性格特点并进行评分,所以这篇文章非常实用。我个人很欣赏作者的切入角度和数据组织方法,实验设计也很到位。
1 引言
传统的自我报告问卷耗时且易受偏见影响(人们常常混淆现实自我和理想自我)。
文中实现方式如下:
- 收集被测试者的实际对话。
- 利用大语言模型(LLM)预测被测试者在量表上的选择。
- 根据量表结果进行评分。
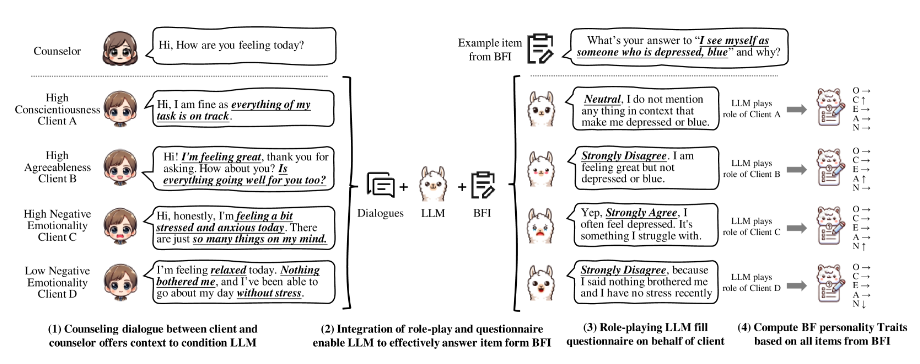
图 1:咨询对话中预测 OCEAN 特征的框架示例。
主要贡献如下:
- 提出了一个结合角色扮演和问卷提示的新框架,利用咨询对话预测 OCEAN 特征。通过对 853 次咨询会议的评估,表明预测特征与实际特征高度相关。
- 消融研究显示,将角色与任务精准对齐,并将复杂任务简化处理,能显著提升特质预测的准确性。值得注意的是,仅利用 30% 的会话内容就取得了准确的 OCEAN 特征预测。
- 通过直接偏好优化(DPO)和监督微调(SFT)调整 Llama3-8B 模型,调优的轻量级微调模型预测效度提高了 130.95%,比 Qwen1.5-110B 高出 36.94%,展现出卓越的效度和效率。
- 公开了代码和模型,为未来研究提供有效工具,支持计算心理测量学领域的研究可重复性和进一步探索。
2 相关工作
自动性格评估
现有的 LLMs 核心关注 MBTI,然而 BFI 在有效性和可靠性上更胜一筹。我们的目标是直接从咨询对话中预测 OCEAN 特质。
提示策略
我们主要使用高级提示策略和角色扮演技术。
对齐策略
通过精调模型提升其效果,通常应用 DPO、RLHF 和 SFT 方法对齐模型并增强生成质量。
3 框架
框架由三大关键组成部分构成:1. 提示策略设计,2. 为 LLM 设置条件,3. 评估指标。
3.1 提示策略设计
提示策略结合了角色扮演和问卷调查。其中,角色扮演涉及三个角色:客户、顾问(主要参与者)和观察者(外部评估者)。调查利用 BFI 的项目来简化预测任务。
- 任务与角色介绍:任务描述明确了 LLM 的角色、其处理的输入以及预期的操作。角色扮演明确了各角色,并概述了其功能和职责。
- 咨询对话:顾问与客户间的对话为 LLM 提供必要的上下文信息。这些真实对话被结构化为聊天历史,与 LLM 的预训练模式相符,使其能够有效模拟客户的回应,从而提高对 OCEAN 特征的预测准确性。
- 预测目标:将 BFI 的问题作为预测目标,引导 LLM 回答问题。这种方法确保 LLMs 与经过验证的心理评估保持一致。
以下是具体方法示例:

3.2 LLM 预测的条件
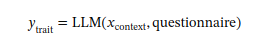
3.3 评估指标
有效性
有效性衡量测试的准确性和相关性,主要包含两个方面:
- 标准有效性:评估预测与基本事实的一致性。采用心理学标准 PCC 来测量预测与实际 OCEAN 性状之间的关联强度和重要性,并通过 MAE 进行预测误差的详细分析。
- 内容有效性:审查预测背后的合理性。
可靠性
可靠性通过评估内部一致性和重测信度来确定。
4 实验
我们收集了来自 82 名成年客户(其中 55 名女性,年龄范围 19 至 54 岁,平均年龄 27.62 岁,标准差 5.94)和 9 名咨询师(其中 7 名女性,年龄范围 25 至 45 岁,平均年龄 34.67 岁,标准差 7.45)的 853 次咨询对话。其中约 30%(242 次)用于验证集,剩余 70%(611 次)用于训练。实验结果显示,模型越大,PCC 性能越佳。
4.1 RQ1: 能否利用 LLMs 从咨询对话中预测 OCEAN 特征?
通过直接从对话中提取 OCEAN 特征来建立基线,不需使用额外策略。
角色扮演与问卷的影响
消融实验结果如下所示:
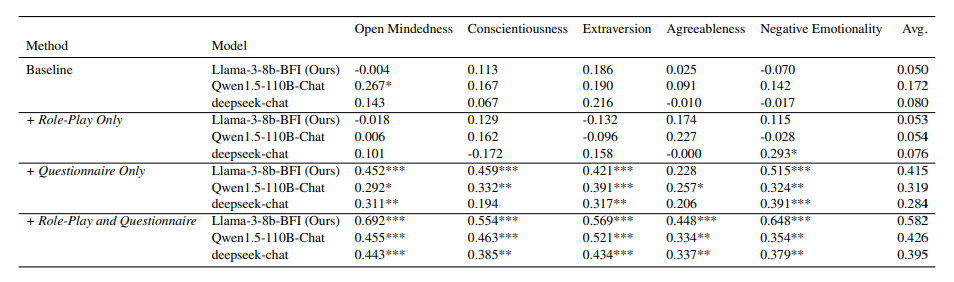
通过不同方法预测 OCEAN 特征的皮尔森相关系数(PCC)。我们对比了 LLMs 在角色扮演、问卷及其结合下的基线与改进表现。结果表明,整合角色扮演和问卷提示显著提升了预测准确性。
角色邻近性对有效性的提升
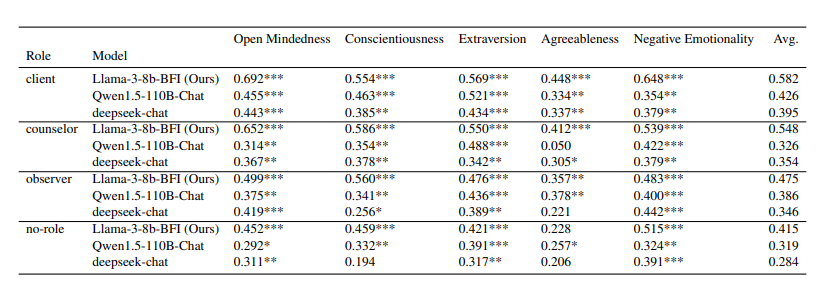
图 2 显示,当 LLM 扮演不同角色时,PCC 相关度不同,以客户和咨询师的角色表现最佳。更贴近角色有助于 LLM 理解上下文,从而提升预测的准确性。
30% 的上下文足以进行预测
粒度指咨询会议中,对准确预测 OCEAN 特质所需的上下文信息量。
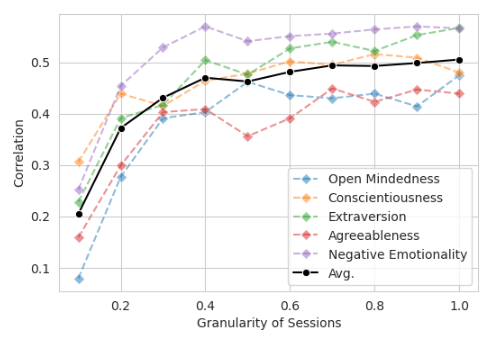
结果显示,仅用 30% 的咨询内容便可有效预测 OCEAN,增加信息量并无显著作用。
模型容量的影响
更高容量的模型展现出统计学上显著的预测相关性。
4.2 RQ2:什么因素影响预测的效度?
识别异常值
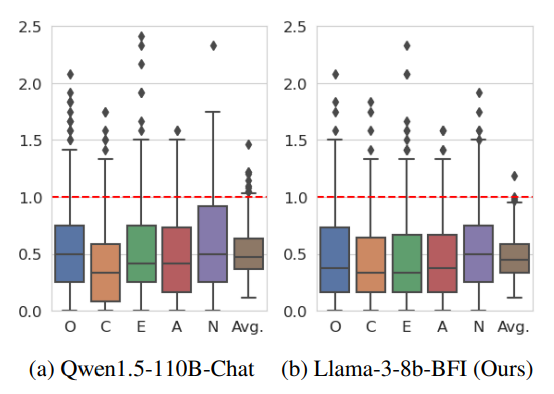
图 4 显示了 OCEAN 维度的 MAE 箱线图。红线标识了重要误差阈值 \(error=1\),其中中位数和上四分位数均低于该阈值。
对话推理能力
研究表明,通过在预测过程中进行归因分析,可以提高预测的效度。
LLM 的局限性
我们分析了 GPT-4-turbo 最不准确的预测,与其最准确的预测进行对比。尽管客户承认有时夸大其感受以显得更具影响力,但这导致了错误的推理,未能准确地反映客户真实的 OCEAN 特征。另外,LLM 表现出的如“作为 AI 模型,我没有个性”的安全拒绝影响了预测的效度。
客户偏差
我们探讨了客户层面的偏差,尤其是通过识别异常值来分析客户的自我表现与其自我报告性格的不一致之处,这可能会影响预测的效度。
4.3 RQ3:将 LLM 与预测 OCEAN 性状任务对齐是否有效?
我们评估了微调模型 Llama-3-8b-BFI 的效度和效率。结果表明,在 PCC 方面,微调模型的预测效度较基础模型提高了 130.95%,较先进模型 Qwen1.5-110B-Chat 提高了 36.94%。
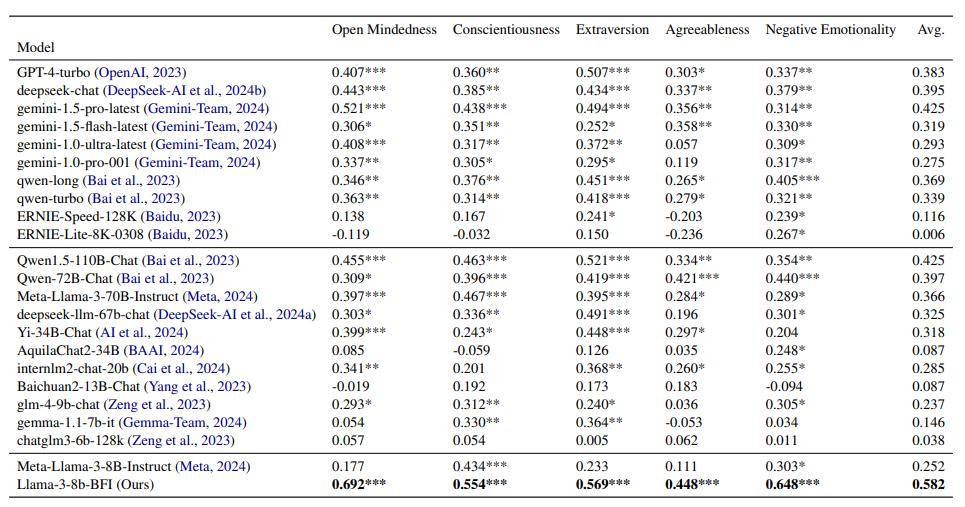
表 -3 展示了不同模型的对比结果,可能与中文语料相关。