大语言模型_带来的一些启发
仅代表个人看法,不喜勿喷。
The limits of my language means the limits of my world. (Ludwig Wittgenstein)
我的语言的极限意味着我的世界的极限。——维特根斯坦
大语言模型解决的不仅是处理文本相关问题,它带来的是人对世界的理解,或者说让机器可以直接理解人的意图,而不再需要翻译成指邻、代码,而语言本身又隐含了人对世界的理解。从这个角度看,自然语言模型引领 AI 时代的进步也就不足为奇了。
十年前说这个,可能觉得很科幻吧;三年前,当看到 GPT-3 生成的驴唇不对马嘴的文章和回答,也只当是个炒作的噱头,一笑了之;最近两个月发布的 AI 进展真称得上是日新月异了,在这一刻,当 ChatGPT 仅两个月就月活过亿,那只能说,你可以不变,但阻止不了世界改变。
过分拟合人的想法是对真实世界的扭曲
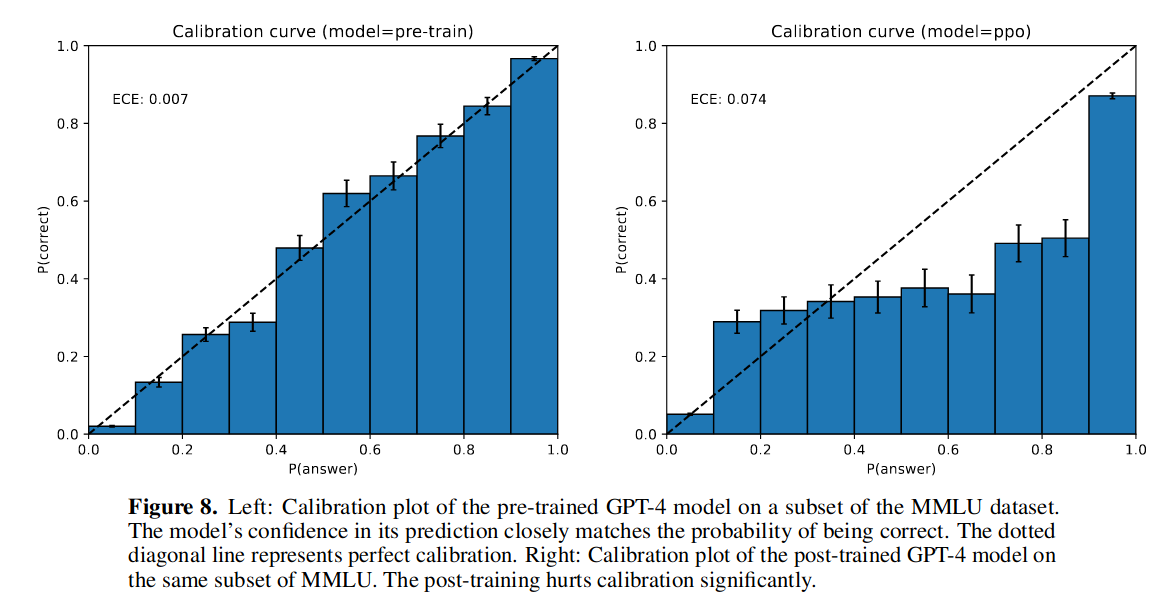
图片来自 GPT-4 论文 [1],对比了预训练模型和使用强化学习调优后模型预测的分布。可以看到,没调前(左图)和真实分布基本是一致的:世界是什么样,模型就学成了什么样;学习调优反而不一致了。强化学习的目标是让 AI 的回答更符合人的提问意图,以及去除毒性(数据中的偏见、攻击性)。
数据也是人生成的,也有鸡汤,也有漫骂,所以…… 当有一天,我们看到世界的全貌,会怎么样?
你想要的答案到底是什么
探讨来自谷歌 2022 年初探讨聊天机器人的论文 LaMDA[2],论文从三方面评估聊天机器人的回答质量:
sensibleness:文本是否合理,跟历史对话是否有冲突(靠谱)
瞎编乱造,前后矛盾肯定是不行的,回答最好还能有理有据。
Specificity:对于提问是否有针对性,避免笼统回复(有用)
比如你问 AI,这电影怎么样?它回答“不错”,这就等于没说,你需要告诉好在哪。
Interestingness:文本是否能引起人的注意或者好奇,是否是超出期待的巧妙回复(有趣)
最好还能带来启发,满足情绪上的一些需求。
(三者权重不同)
从某个角度上讲,这也是我们对人的期许,逐层渐进。是不是觉得有点像:找男朋友的筛选标准?
多闻和推理需要不同的训练途径
实验来自 DeepMind(发明 AlphaGo 的公司)在 2021 年 12 月发布的一篇论文:Gopher[3]
任何学术科目,连同一般知识,通过改进模型规模都能提升其效果,但规模对逻辑推理、常识和数学任务的好处较少。
最近一两年,出现的一些针对逻辑推理的训练方法,比如 CoT:Chain-of-Thought 思想链,主要指模型的多步推理能力,以解决更为复杂的问题。
Google 的 PaLM 论文 [4] 里,有很多推理示例,比如下面这个推理示例:
用户输入:迈克尔在法国那个非常有名的博物馆里看它最著名的画作。然而,创作这幅画的艺术家恰恰让迈克尔想起了他小时候最喜欢的卡通人物。卡通人物平时手里拿的东西是哪个国家的?
模型输出:卢浮宫最著名的画作是蒙娜丽莎。制作蒙娜丽莎的艺术家是达芬奇。Leonardo da Vinci 也是卡通忍者神龟中主角的名字。列奥纳多·达·芬奇来自意大利。列奥纳多·达·芬奇平时手里拿着的东西是武士刀。武士刀的原产国是日本。答案是“日本”。
读万卷书
来自 DeepMind 在 2022 年 3 月发布的论文 Chinchillla[5],它针对训练数据量,模型参数量,以及数据训练量进行实验,得出一些结论:
更长的训练时间,更多 token,能提升模型效果
学习更多的知识和更多训练更为重要
大模型的参数量和性能之间存在幂律分布
学到一定程度之后,进步就越来越慢了
训练时 token 越多,模型效果越好
作者认为模型的大小与训练 token 量应等比增加。
从这个角度出发,作者将模型从 280B 参数降到了 70G,用更多 token 训练模型,模型效果没有下降,反而还有些提升。
从人的角度看,不需要太过纠结于拟合当前的知识和存储量,更重要的是扩展知识面,另外应该多“思考”。
行万里路
众所周知,GPT-3.5 没有相关论文,而 GPT-4 的论文 [1] 主要介绍了模型效果,而没有具体实验的技术和模型细节。
从实验来看在 MMLU 测试中,之前模型通过种种优化,一般都在 70 分左右,最好也只有 75 分,而 GPT-4 达到了 86.4 分,其中强化学习功不可没。
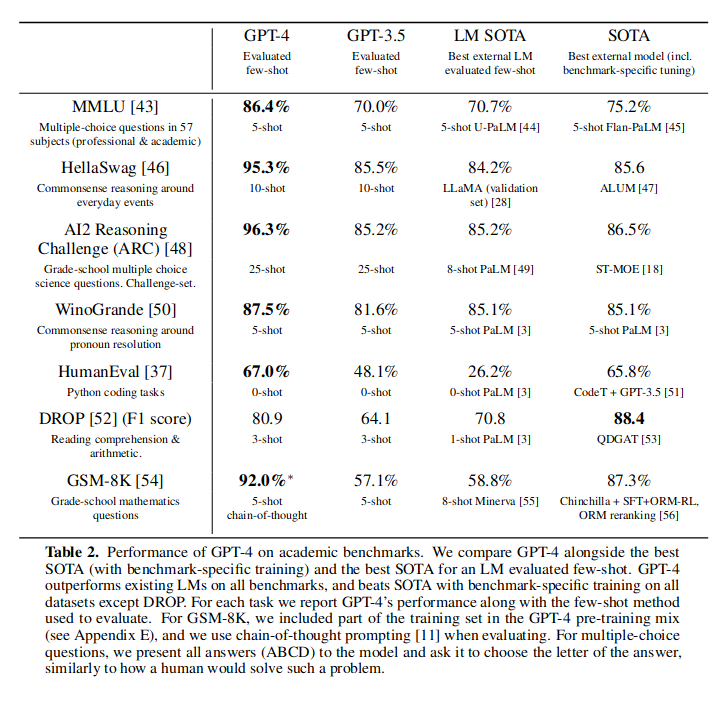
GPT-3.5 说它的结构与 InstructGPT(2022-03)[6] 一致,而 InstructGPT 主要的进步就是:RLHF(基于人类反馈的强化学习),它与之前的有监督学习和无监督学习不同的是通过模拟环境下试错,拥有了更长远的“眼光”。
当然,这个阶段的 AI 也不可能一家独大,最近发布的基于 Meta 的 LLaMA[7] 模型优化的经济型模型 ColossalChat[8] 也使用了 RLHF(基于人类反馈的强化学习)已经开源并且开放了几乎是即下即用的 github 下载,听说前两天发布的 Dolly[9] 单机模型效果也很好。
知识的互通性
当机器听得懂人话,不再用程序员翻译,更进一步还能听得懂声音,看得懂图片,视频,智力题…… 输出也不限于文字回答,还可能是图片,代码,拆解的方案,推理的步骤。从 LLM(大语言模型)到 MLLMs(多模态大语言模型)的概念提出之后,又扩展了 LLM 的用途。所有可说,不可说,无法用语言描述的规律……
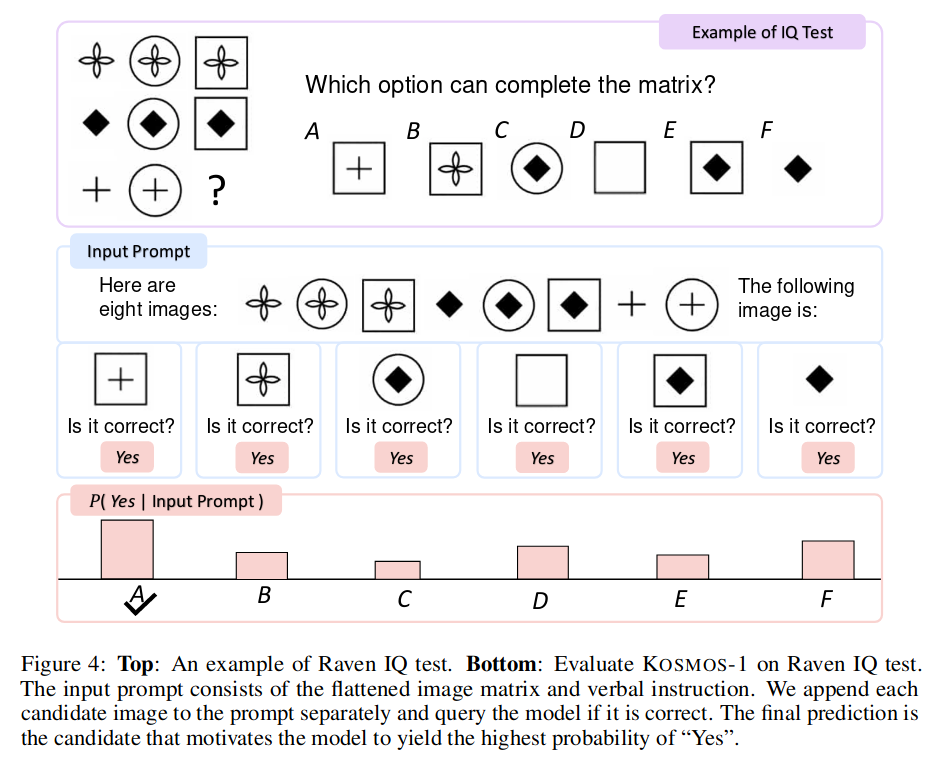
23 年 3 月发布了很多 ChatGPT 周边的应用,比如微软的 Visual ChatGPT[10],自身没有训练大模型,只调用现有的图像处理和自然语言模型就实现了很好的带图像的聊天功能,微软的 Kosmos-1[11] 结合图像和语言的大模型在智力题,直接识图方面能力也很强。

关于版权
很多训练数据和评测都是公开的,而训练大模型时一般多数数据来自互联网,因此其产出的回答版权归谁,还真不好说。巨头可以不公开模型结构,训练细节,这都是公司的产权,可以不对外开放,但是从互联网上学到的知识训练出的模型,生成的答案,这个版权就不好说了,不止是语言模型,大多数生成模型可能都会遇到这个问题。
一些想法
如果说前两次工业革命解放了人的体力,那么信息和 AI 就可能解放人的脑力,生产力的变化也会引起社会形态的变化。有点迷茫,忽然想到《双城记》:
这是最好的时代,这是最坏的时代,这是智慧的年代,这是愚蠢的年代;这是信仰的时期,这是怀疑的时期;这是光明的季节,这是黑暗的季节;这是希望之春,这是失望之冬;人们面前应有尽有,人们面前一无所有;人们正踏上天堂之路,人们正走向地狱之门。
参考引用
2 LaMDA: Language Models for Dialog Applications
3 Scaling Language Models: Methods, Analysis & Insights from Training Gopher
4 PaLM: Scaling Language Modeling with Pathways
5 Training Compute-Optimal Large Language Models
6 Training language models to follow instructions with human feedback
7 LLaMA: Open and Efficient Foundation Language Models
10 Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
11 Language Is Not All You Need: Aligning Perception with Language Models