论文阅读_用引导调优模型
name_ch: 微调语言模型是零样本学习者
name_en: Finetuned Language Models Are Zero-Shot Learners
paper_addr: http://arxiv.org/abs/2109.01652
code: https://github.com/google-research/flan
date_publish: 2022-02-08
读后感
介绍
指令调优是:在通过指令描述的一组数据集上微调语言模型,它显著提高了未见任务的 zeroshot 性能。将此类模型称为 FLAN(Finetuned Language Net),采用 137B 参数预训练语言模型,并在 60 多个通过自然语言指令模板的 NLP 数据集上对其进行指令调优。
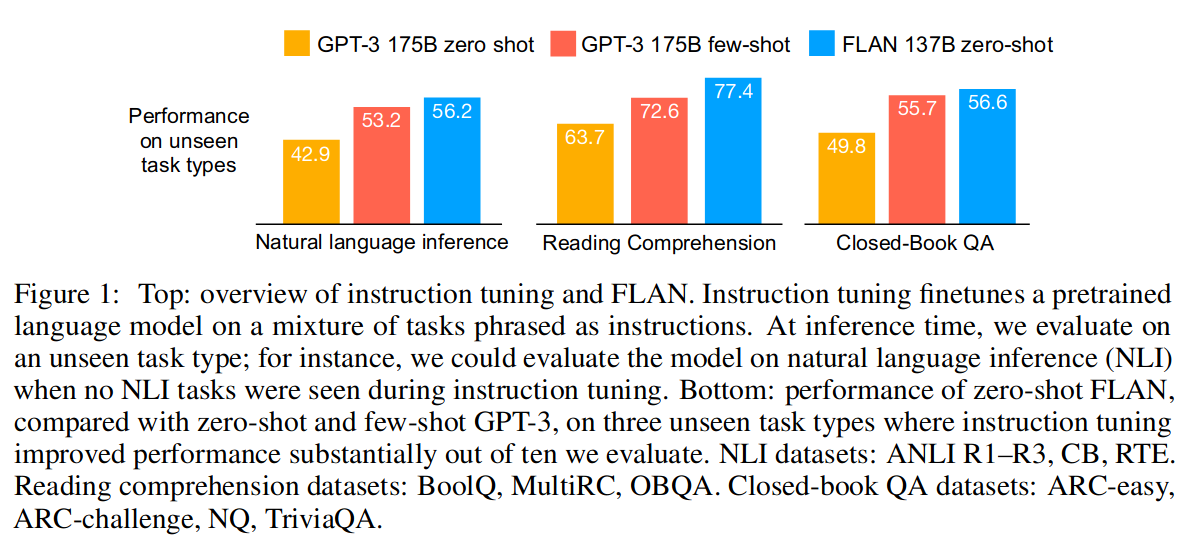
模型效果,图 -1 展示了模型在不同类型任务上的效果对比:
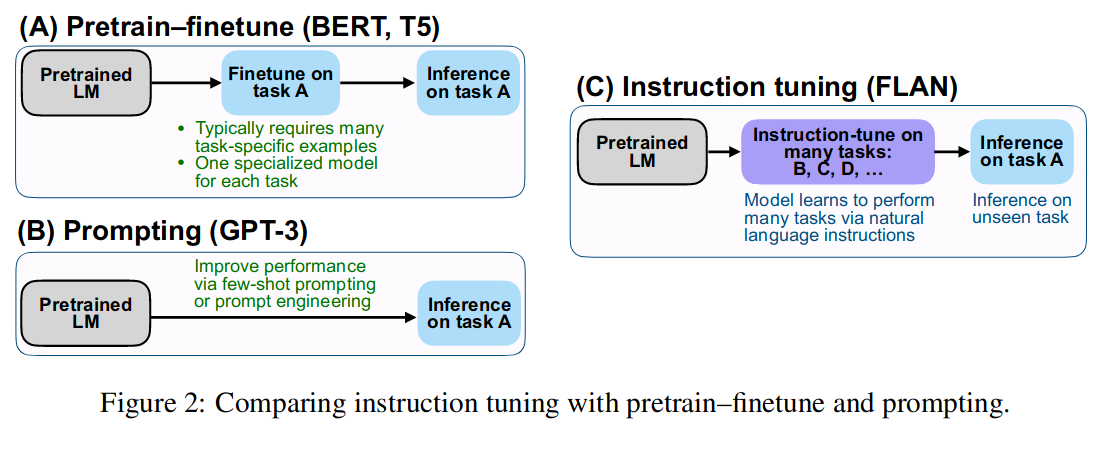
方法
原理图
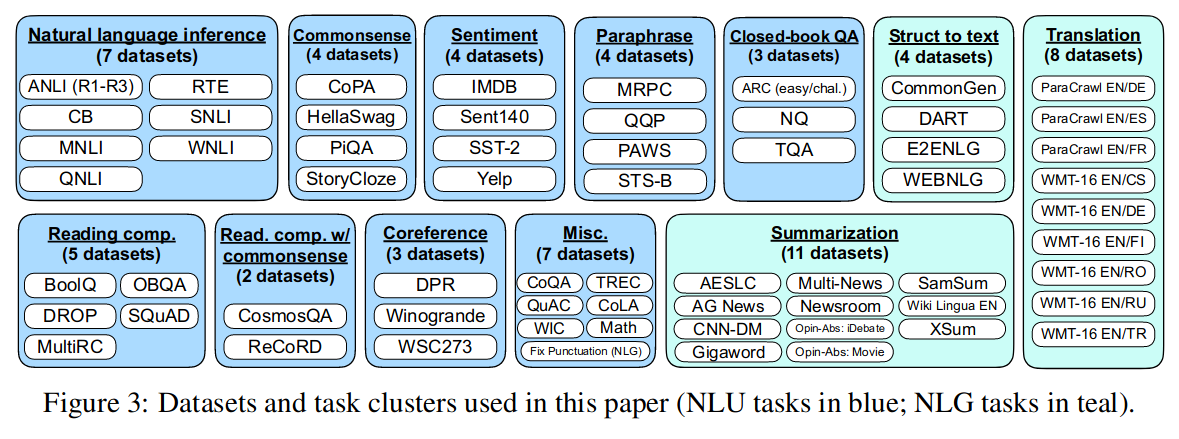
用 Tensorflow Datasets 上公开可用的 62 个文本数据集(包括语言理解和语言生成任务)聚合到一起,每个数据集被分类为十二个任务集之一。
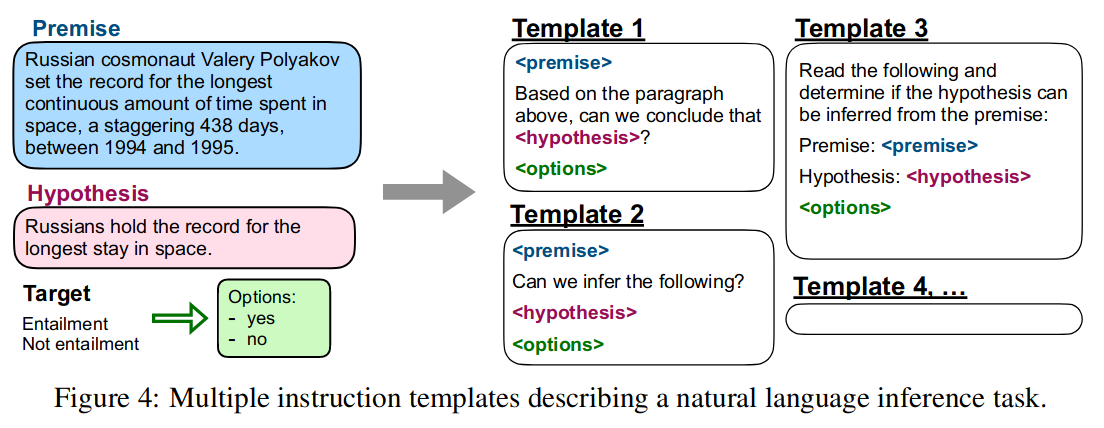
对于每个数据集,我们手动编写了十个独特的模板,这些模板使用自然语言指令来描述该数据集的任务。
模板如下图所示:
模型架构和预训练
我们使用 LaMDA-PT,这是一种密集的从左到右、仅解码器的 137B 参数变换语言模型。该模型在一组网络文档、对话数据和维基百科上进行了预训练,并使用 SentencePiece 库标记为具有 32k 词汇的 2.49T BPE 标记。大约 10% 的预训练数据是非英语的,PT 指的是预训练语言模型。
指令调整程序
FLAN 是 LaMDA-PT 的指令调整版本。指令调优管道混合了所有数据集并从每个数据集中随机抽样。为了平衡不同大小的数据集,将每个数据集的训练示例数量限制为 30k,并遵循示例比例混合方案。在具有 128 个内核的 TPUv3 上,此指令调整大约需要 60 个小时。对于所有评估,并报告了经过 30k 步训练的最终检查点的结果。
实验
在自然语言推理、阅读理解、闭卷 QA、翻译、常识推理、共指消解和结构到文本方面评估 FLAN。
观察到指令调优对自然语言化为指令的任务(例如,NLI、QA、翻译、结构到文本)非常有效,而对直接表述为语言建模的任务效果较差,其中指令在很大程度上是冗余的。
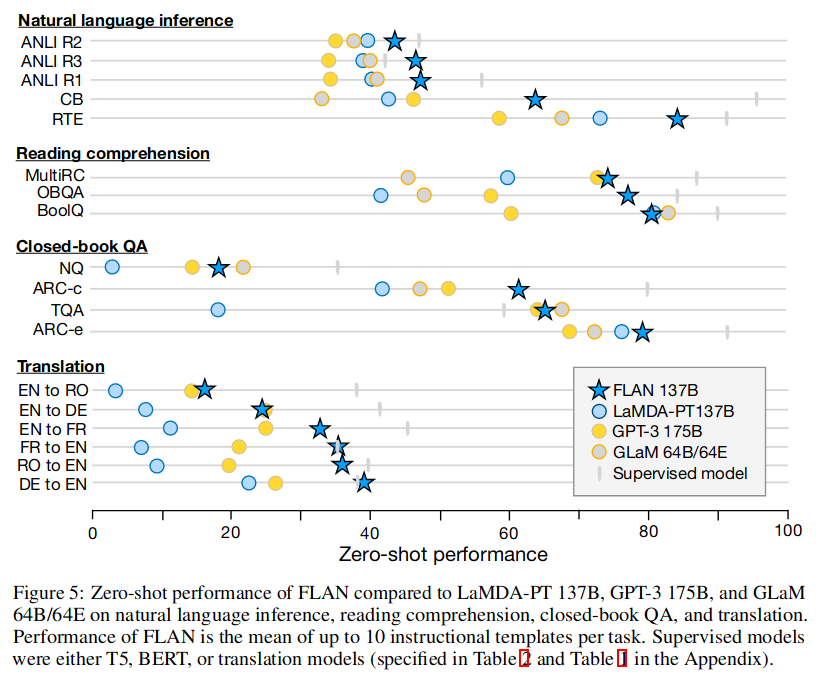
FLAN 的性能相对于 LaMDA 每个任务平均值提升了 10 左右。
在指令调优中添加额外的任务集,可以提高保留任务集的零样本性能。
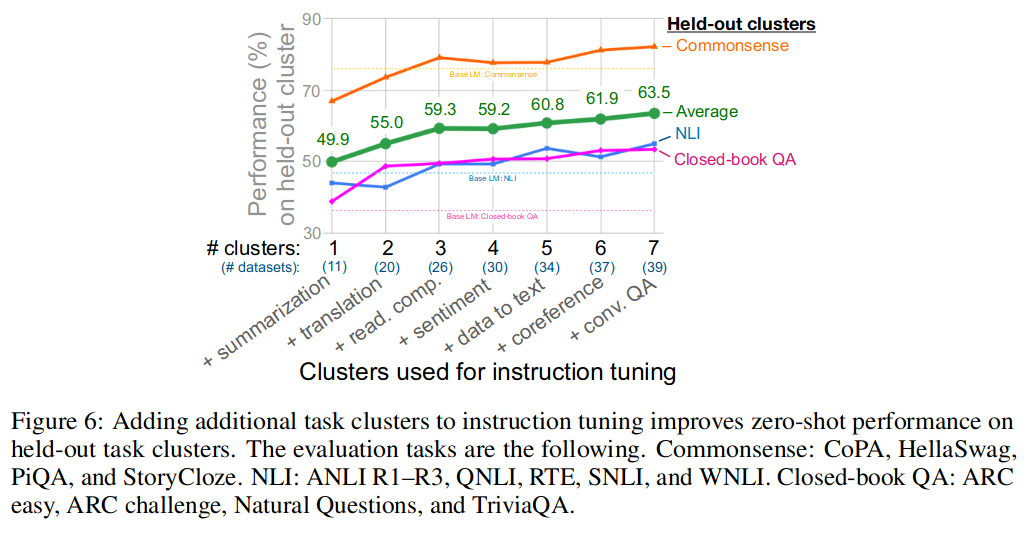
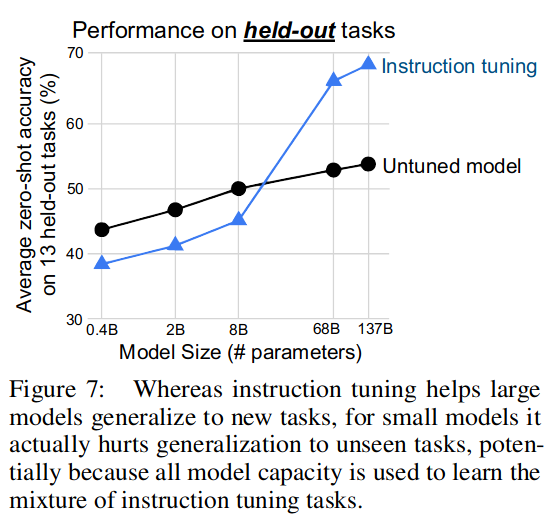
尽管指令调优有助于大型模型泛化到新任务,但对于小型模型,它实际上会损害对未见过任务的泛化。