论文阅读_解释大模型_语言模型表示空间和时间
1 | 英文名称: LANGUAGE MODELS REPRESENT SPACE AND TIME |
1 读后感
作者想要研究的是:模型是只学习字面意思,还是能够学习到更深层次的知识。比如人名、地名以及与时间和空间相关的位置。为了实现这一目标,作者使用了 llama-2 模型,输入数据集中的名称,然后,对每一层的输出进行线性变换,以预测其所属的时间和空间类别。实验证明,在模型的低层就开始构建了关于时间和空间的表示。而在模型中间层达到饱和点时,参数已经学习到了实体相关的时空信息。
2 摘要
目标:分析模型是只学习字面意思,还是能够学习到更深层次的知识。
方法:通过分析 Llama-2 系列模型对三个空间数据集(世界、美国、纽约地点)和三个时间数据集(历史人物、艺术品、新闻头条)的学习表示来寻找的证据。
结论:分析表明,现代大型语言模型(LLMs)能够获取关于空间和时间等基本维度的结构化知识,这支持了它们不仅仅学习表面的统计数据,而是真正学习了世界模型的观点。
3 引言
一种假设是,LLMs 学习大量相关性。但在仅接受文本训练的情况下,它们缺乏对基础数据生成过程的“理解”。另一种假设是,LLMs 在压缩数据时,会学习训练数据基础的生成过程,并生成更紧凑、连贯和可解释的世界模型。
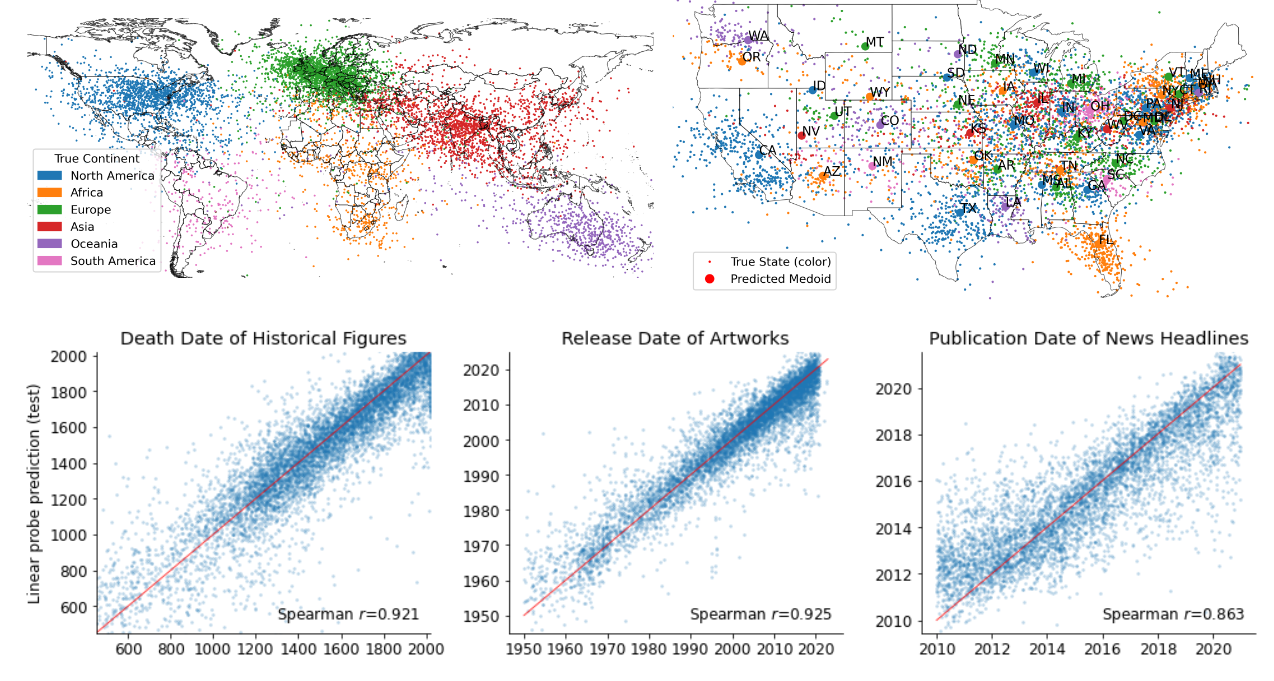
图 1:Llama-2-70b 的时空世界模型。每个点对应于投射到学习的线性探针方向上的位置或事件的最后一个 token 的第 50 层激活。所描述的所有点都来自测试集。
使用 Llama-2 模型训练线性回归探测器,以预测地点和事件名称的内部激活在真实世界中的位置或时间。实验结果表明,模型在早期层次中构建了空间和时间的表示,并在模型的一半左右达到饱和点。较大的模型始终表现优于较小的模型。此外,研究还展示了这些表示是线性的,因为非线性探测器并不能取得更好的效果。同时,这些表示对于提示变化非常稳健,并且在不同类型的实体(如城市和自然地标)之间是统一的。
4 实证概述
4.1 数据集
构建了六个名称数据集,分别包括人物、地点、事件等。这些数据集涵盖了跨越多个时空尺度的地点或事件名称,并提供相应的空间或时间坐标。其中包括全球范围内的地点、美国和纽约市,以及历史人物过去 3000 年的死亡年份、自 1950 年代以来艺术和娱乐作品的发布日期,以及 2010 年至 2020 年新闻头条的发布日期。
4.2 模型和方法
所有的实验都使用基础的 Llama-2 语言模型进行,该模型的参数范围从 70 亿到 700 亿。对于每个数据集,通过模型处理每个实体名称,可能在之前加上一个简短的提示,并保存最后一个实体标记在每个层上的隐藏状态激活。
在网络激活上拟合了一个简单的模型,用于预测与标记输入数据相关的目标标签。给定一个激活数据集和包含时间或二维纬度和经度坐标的目标 𝒀,拟合线性脊回归探针。
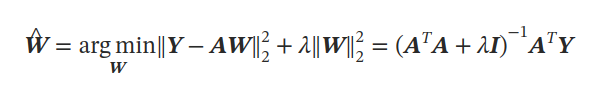
通过线性预测器𝒀=𝑨𝑾,观察到在样本外数据上表现出了高预测性。这表明基础模型的表示可以通过线性变换解码成时间和空间信息。在所有实验中,使用高效的留一法交叉验证方法对探针训练集进行调优。
4.3 评估
为了评估探针性能,使用标准回归指标如 R2 和斯皮尔曼等级相关性来报告测试数据结果(对于空间特征,经纬度的相关性取平均值)。另外,还计算了每个预测的接近误差,即比实际目标点更接近目标点的预测所占比例。
5 时空线性模型
5.1 存在
首先要研究模型是否能够表示时间和空间,以及在模型中的哪个部分进行表示。另外,需要考虑模型大小对质量的影响。对每个空间和时间数据集进行 Llama-2-{7B、13B、70B} 的探针训练。主要发现是,在不同数据集上有相似的模式。空间和时间特征都可以用线性探针恢复,随着模型规模增大,这些表示变得更加准确,并且在达到平稳状态之前,模型前半部分的表示质量会平滑提高。
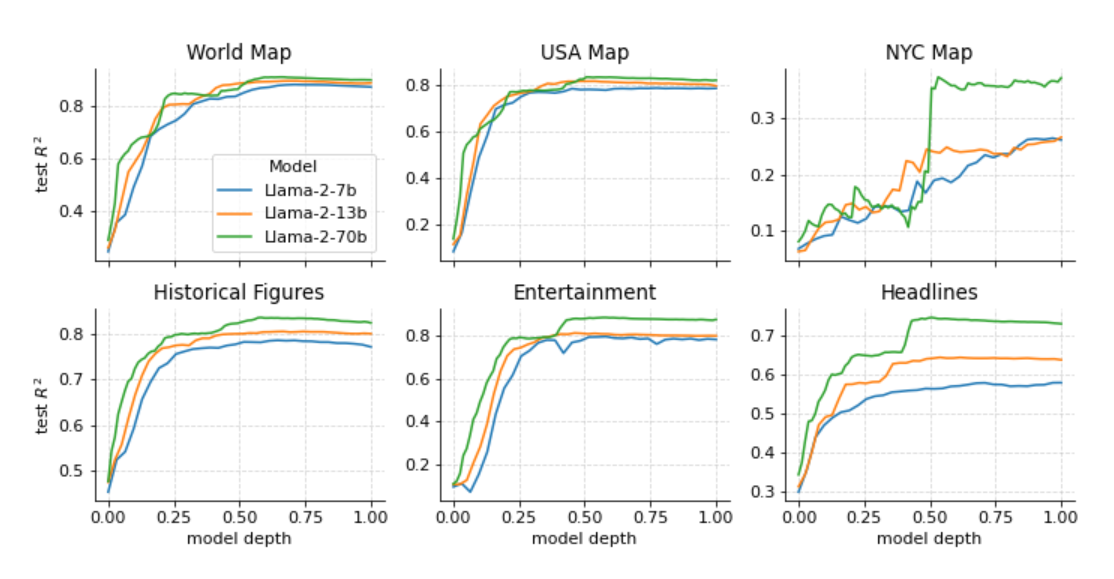
图 2:在每个模型、数据集和层上训练的线性探针的样本 R2
5.2 线性表示
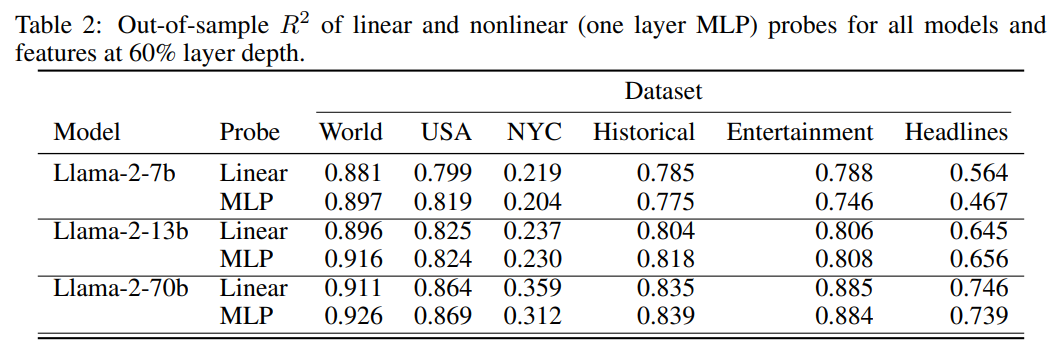
使用非线性探针对任何数据集或模型的改进都很小。这证明了空间和时间也是线性表示的(或者至少是线性可解码的)。
5.3 对提示的敏感度
另一个问题是,这些空间或时间特征是否对提示敏感?换句话说,上下文是否可以影响或抑制对这些事实的回忆?
为了研究这个问题,创建了新的激活数据集,在每个实体标记之前添加了不同的提示语。在所有情况下,实验都包括一个“empty”提示。然后,包括一个提示,要求模型回忆相关事实,例如“地点的纬度和经度是多少?”或者“作者/书名发布日期是什么?”最后,在新闻标题数据集中,尝试在标题末尾进行探测,并在标题后附加一个句号标记。
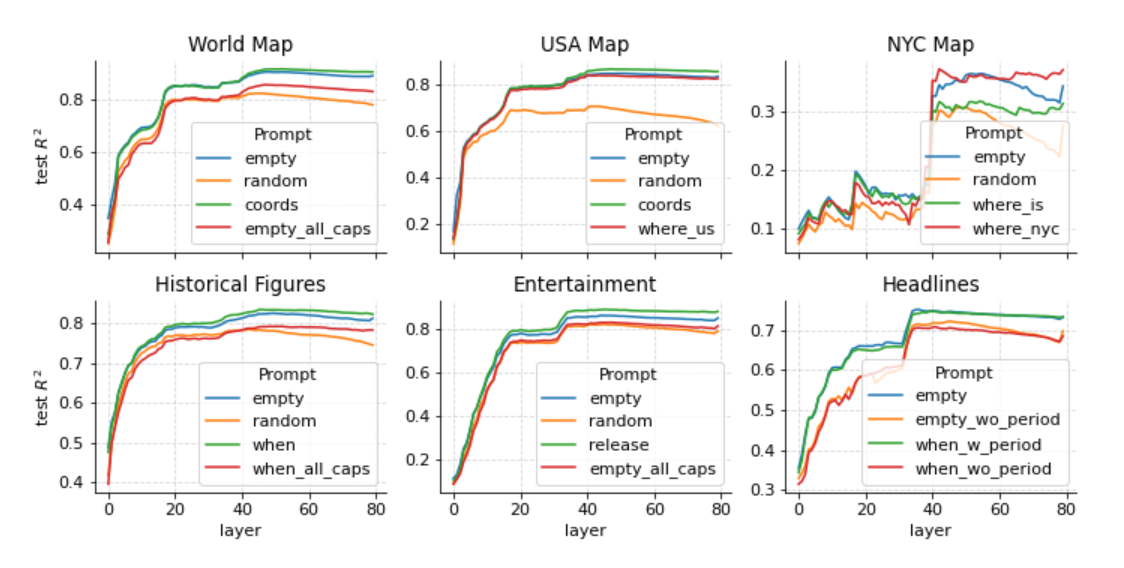
图 3:当实体名称包含在 Llama-2-70b 的不同提示中时 R2 。
在图 3 中,明确提示模型获取信息,或给出消除歧义的提示,不会影响性能。而随机分散注意力明显降低了性能。大写实体也会降低性能。对于提高性能来说,最显著的改进是句子末尾的句点标记。这表明句点可能包含了一些摘要信息,用于概括它们所在句子的内容。
6 稳健性检查
6.1 通过泛化进行验证
上述实验证明,可以利用模型中后层的输出通过线性变换探针计算出名称对应的时间和空间位置。然而,这种探针可能仅仅学习了模型简单特征的某种线性组合,并不一定是模型本身的能力。
为了进一步验证,作者提出了 held out 方法,即训练一系列探针,分别针对世界、美国、纽约市、历史人物、娱乐和头条新闻数据集建模。在这过程中,保留其中一个数据集不参与训练(例如,在世界范围内保留了日本的数据)。然后评估探针在保留部分数据上的表现,并将其与正常划分训练/测试数据进行比较。
图 -3 显示了 held-out 方法的平均接近误差与普通的 nominal 方法中该数据块的测试点误差进行比较,随机性能为 0.5。实验证明,尽管 held-out 方法的泛化性能受到影响,但它显然比随机更好,尤其是对于空间数据集。
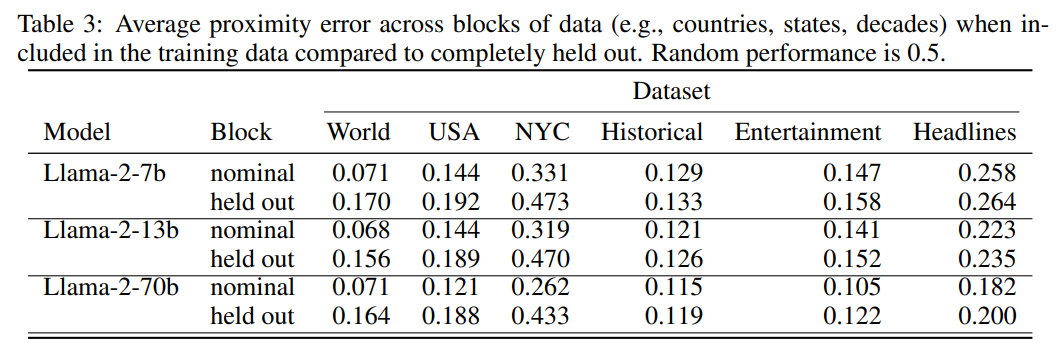
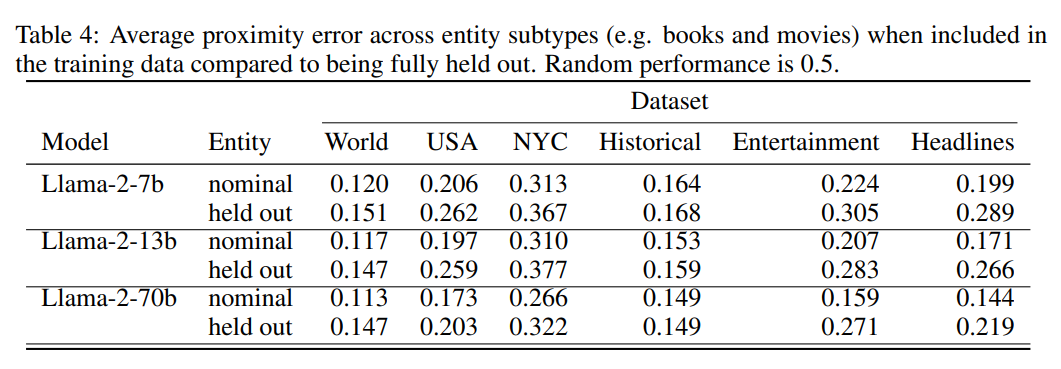
图 -4 展示了实体子类别(例如书籍和电影)识别的效果,并对比了 nominal 和 held out 的平均接近误差。结果显示,这些探针能够在实体类型之间进行泛化,唯一的例外是娱乐数据集。这也间接证明了模型以统一的方式表示不同类型的实体。
6.2 降维
尽管探针是线性的,但它们有大量的可学习参数,使得它们能够记忆大量信息。通过减少参数并将数据投影到主成分上进行训练,发现 Spearman 相关性随参数数量的增加而快速增加,这表明模型能显式地表示空间和时间。另外,数据的前几个主成分能够将不同类型的实体聚集在一起,这解释了为什么需要更多的主成分。
7 时空神经元
搜索具有输入或输出权重的单个神经元,这些神经元与学习的探针方向具有高度的余弦相似性。也就是说,这些神经元的方向与探针学习的方向相似。
最终发现,模型中存在单个神经元,这些神经元本身就是可预测的特征探针。此外,这些神经元对数据集中的所有实体类型都很敏感。如果将监督训练的探针视为模型表示这些空间和时间特征的程度的近似上限,那么单个神经元的性能就是一个下限。从而表明该模型已经学习并利用了空间和时间特征。
8 参考
https://baijiahao.baidu.com/s?id=1778899666625948263&wfr=spider&for=pc