论文阅读_ViT
1 | name_ch: 将 16x16 的块看作词:用 Transformers 实现大规模图像识别 |
读后感
ViT 是 Vision Transformer 的缩写,是 2020 年 Google 团队提出的将 Transformer 应用在图像分类的模型。ViT 将输入图片分为多个 patch,再将每个 patch 投影为固定长度的向量送入 Transformer,后续 encoder 的操作和原始 Transformer 中完全相同。
ViT 虽然不是第一篇将 transformer 应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了 transformer 在 CV 领域应用的里程碑著作。
在不修改优化 Transformer 的基础上,通过将切块的图片像 word 一样转入 Transformer 模型,并使用类似 BERT 的结构处理分类问题,在大数据集训练后效果好于已有模型。后面的很多模型都基于该模型为基础调优,可以说它奠定了视觉大模型的基础。
方法
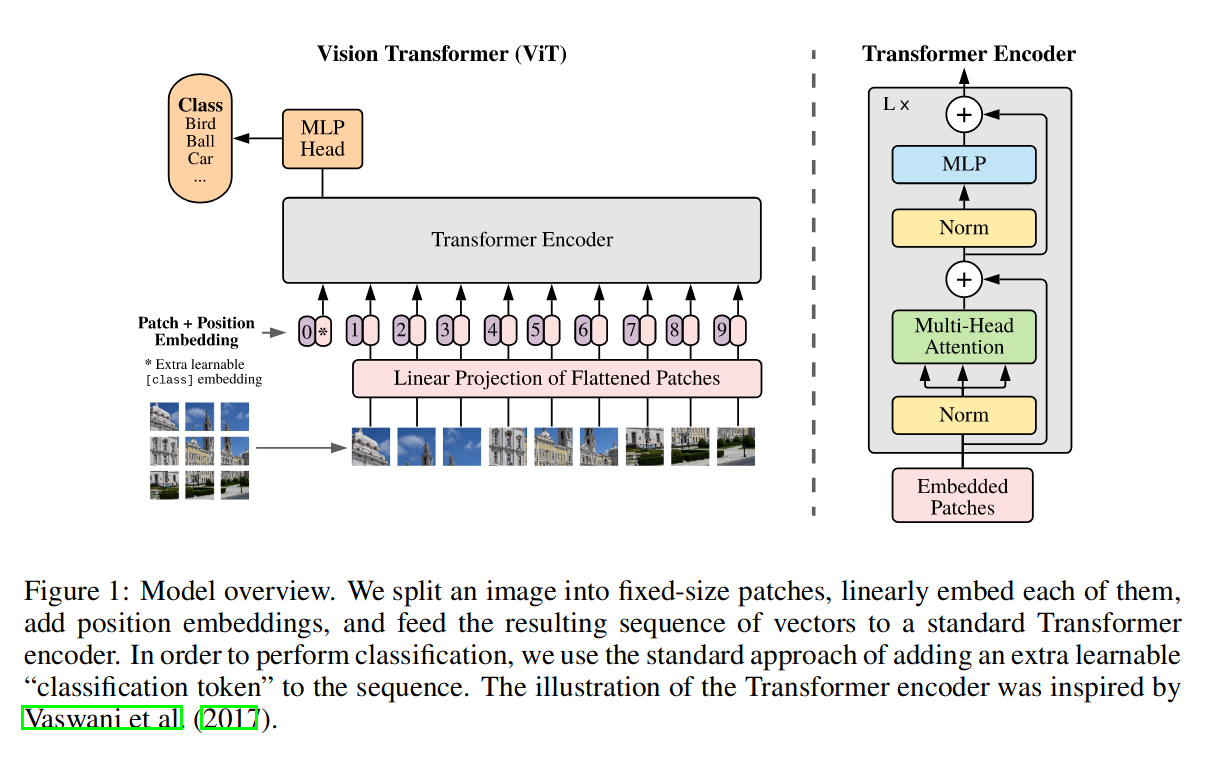
图 -1 示例将图切成 9 个 16x16 大小的块,然后用线性映射成 Patch Embedding;由于图片有上下左右的顺序,又加了 Position Embedding(与 BERT 方法一致);另外,前面还加了一个星的 token,它类似于 BERT 对分类的处理,最终也是通过这个 token 来完成分类任务。
比如:图片是 224x224x3,拆成 14x14 块,每块:16x16x3=768,经过映射(768x768)后输出也是 768(可以设置),结果就是:每句 196 个单词,每个单词用 768 维表示(Patch Embedding)。
公式如下:
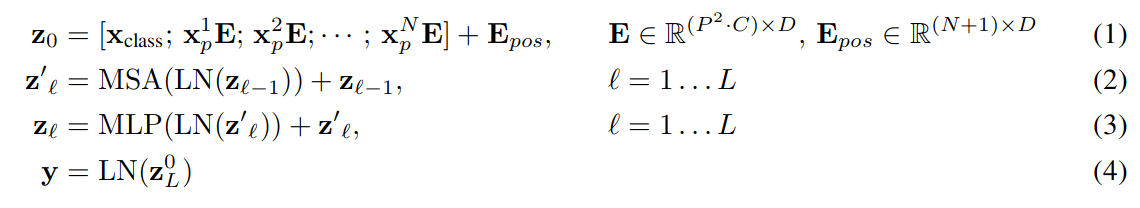
Z0 为第一层,E 为映射到嵌入空间,Epos 为位置嵌入,Xclass 为类别 token;Zt 为后 n 层;MSA 是多头注意力;MLP 是全连接层。ViT 没有用太多归纳偏置(先验知识),所以在中小数据集中效果不如 CNN。
实验
结果证明 ViT 比另两个模型训练快且效果好:
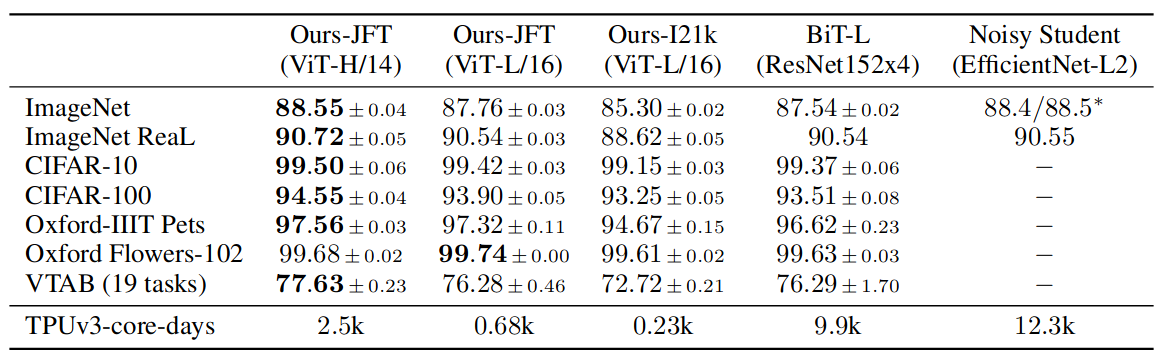
数据越多,模型效果越好,扩展性更好;数据少里 ViT 更容易过拟合,效果不如 ResNet。
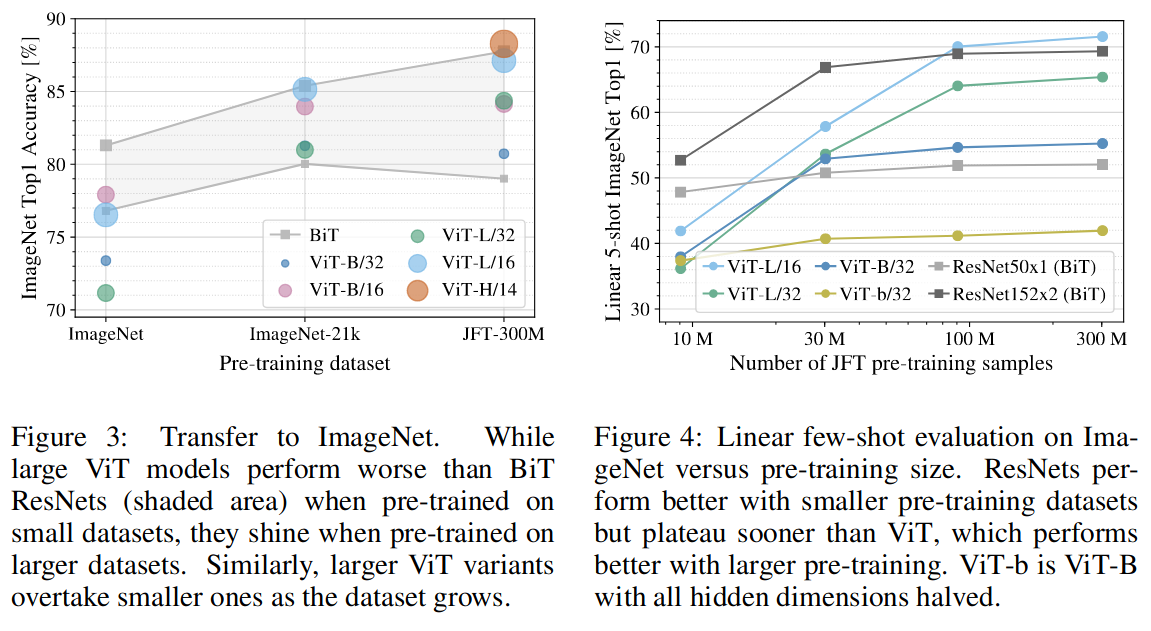
对比不同资源占用,证明 ViT 更节约资源:
从左图可以看到,ViT 和 CNN 学到了类似的图像表征;
从中间图可以看到,虽然使用了一维的 position,但是明显学到了上下左右的位置信息;
从右图可以看到,根据注意力权重计算图像空间中集成信息的平均距离(类似于 CNN 中的感受野大小),在低层的注意力距离一直很小,即注意力相对局部化,注意力距离随着网络深度的增加而增加,高层的关系更概括抽象。
