论文阅读_中文医学预测训练模型_MC-BERT
论文阅读 _ 中文医学预训练模型 _MC-BERT
介绍
英文题目:Conceptualized Representation Learning for Chinese Biomedical Text Mining
中文题目:中文生物医学文本挖掘中的概念化表征学习
论文地址:https://arxiv.org/pdf/2008.10813.pdf
领域:自然语言处理,知识抽取
发表时间:2020
作者:Ningyu Zhang,阿里巴巴
被引量:14
代码和数据:https://github.com/alibaba-research/ChineseBLUE
模型下载:https://drive.google.com/open?id=1ccXRvaeox5XCNP_aSk_ttLBY695Erlok
阅读时间:2022.05.07
我的收获
获得了现成可用的医学 BERT 模型,以及大量带标注的数据集。
针对问题
医疗数据集与普通数据集分布不同,医疗词汇的长尾分布也很难从普通语料中学习,中文的词和短语更复杂一些。需要训练一个类似 BERT 的针对医疗的中文预训练模型。
本文贡献
- 提出了用于评价中文医疗语言模型的 ChineseBLUE。
- 将实体和语言领域知识注入到模型,实现了基于医学的预训练模型 MC-BERT。
相关工作
BERT 类模型将语境引入建模。后续的改进包括:有效地利用外部知识,如知识图改进表征效果;通过控制 BERT 的 MASK 方法改进效果;BioBert 利用医学领域数据训练模型,本文将结合上述几种方法,以训练中文医疗知识表征。
方法
相对 BERT 的改进有以下三部分:
全实体 Masking
MC-BERT 以 BERT 为基础,因 BERT 中文以字为单位,文中方法利用知识图和命名实体识别到的词,以词作为遮蔽单位,如:同时遮蔽“腹痛”两个字。从而引入了领域知识,实体包括:症状、疾病、检查、处治、药品等。
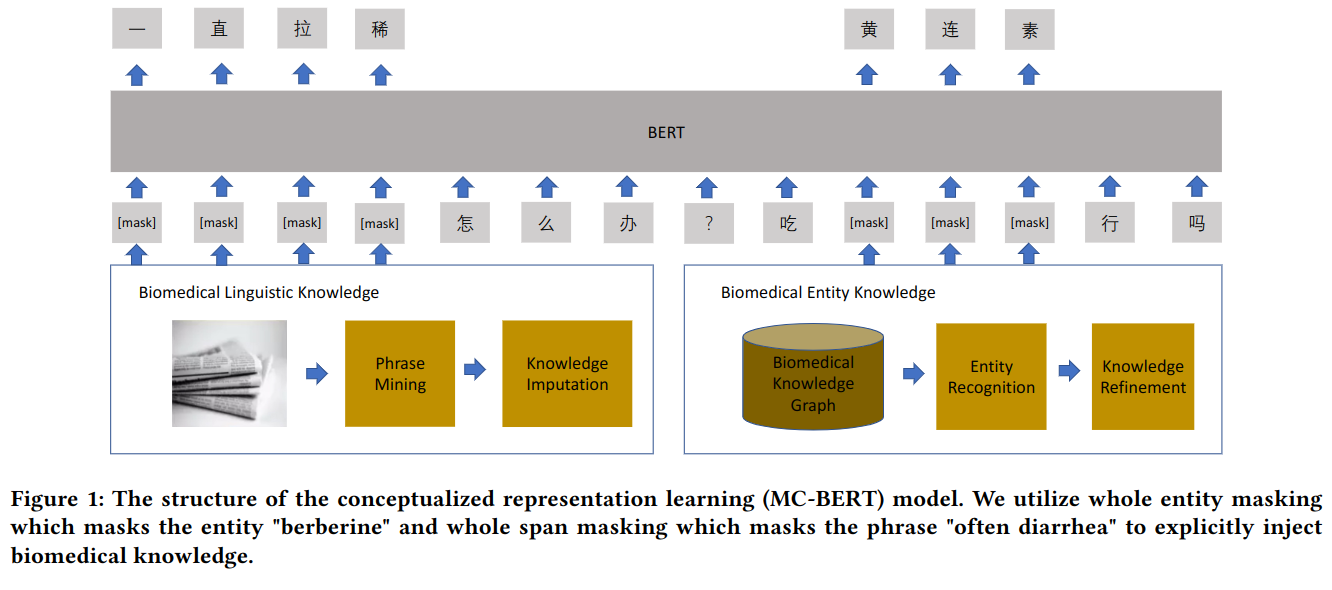
全跨度 Masking
" 肚子有一点疼 "," 腹部一阵一阵痛 "," 腹痛 " 的意思都差不多,利用Autophrase获取短语,然后从阿里巴巴认知概念图抽取医学短语,利用领域知识扩充数据,并训练一个二进制分类器来过滤那些非生物医学短语。收集了医学百科全书中实体和属性的n-gram表征作为正样本,随机采样短语作为负样本。
医学数据训练
将 BERT 模型作为基础模型,用医学数据训练。
具体训练方法如下:

数据来源

下游任务
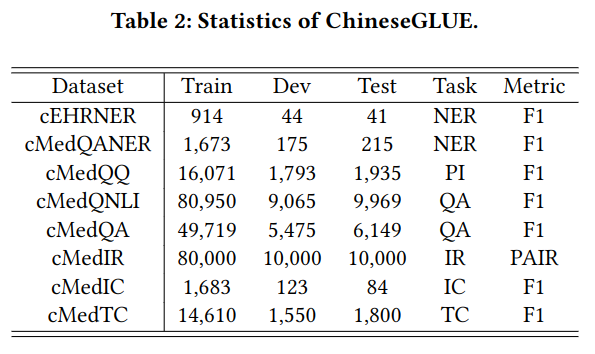
文中提出的 ChineseBLUE 评价数据集,具体任务包含:
- 命名实体识别(NER):识别疾病、药物、症状等,医疗数据集包含中国电子健康档案标注的 cEHRNER,和中国社区问题数据标注 cMedQANER。
- 解释识别(PI):评价两句话是否同意。医疗数据集名为 cMedQQ,它由成对的查询组成。
- 问答(QA):根据相似度对候选答案排序,对 QA 分配标签使之转化为二分类问题。使用了包含长文本的 cMedQNLI 和短文本的 cMeQA。
- 信息检索(IR):根据给定的搜索查询查找最相关的文档,可视为排序任务,具体数据集是 cMedIR,它包含一系列的文档及其打分。
- 意图分类(IC):目标是给文本打意图标签,可视为多标签分类任务,具体使用 cMedIC 数据集,它包含三个标签:无意图,弱意图,强意图。
- 文本分类(TC):给句子打多个标签,使用 cMedTC 数据集,由具有多个标签的生物医学文本组成。
- 中文医疗对话数据集(CMDD):包含医患对话的数据集。(文中评测未使用)
- 问题推理(QNLI):其中包含问答对,并标注是否回答正确。(文中评测未使用)
具体数据量如下:
实验结果如下
对比 BERT 与 MC-BERT:
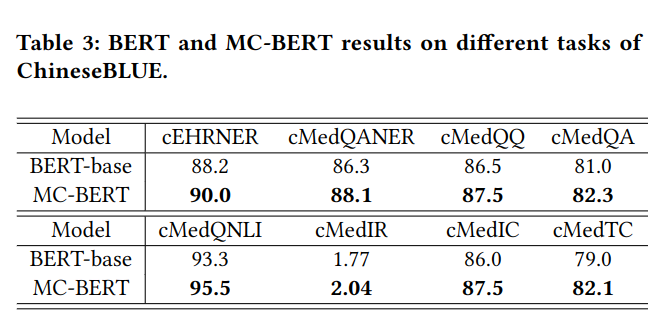
展示 Mask 改进的有效性: