iTransformer时序预测模型解析
1 | 英文名称: ITRANSFORMER: INVERTED TRANSFORMERS ARE EFFECTIVE FOR TIME SERIES FORECASTING |
读后感
作者提出了一个疑问:为什么在很多情况下,时序问题使用 Transformer 结构反而不如线性模型好?按理说,Transformer 作为预测序列化数据的模型,应该更擅长处理时序问题。作者认为可能是数据组织方式不够优化引起。
文章主要讨论了多变量时序预测的问题,即使用多变量的 X 来预测 Y,例如使用过去的天气数据和地域数据等来预测未来的天气。
之前我们处理时序数据也存在相同的问题:每种数据的频率和范围都不一样,如果在某个时间点上对所有数据进行采样也不太合适。
因此,作者提出了针对时间序列的另一种输入方式。以前是将每个时间点的所有变量作为一个 token 传递给模型;而现在,将每个变量的整个时间序列独立地嵌入到一个 token 中。简单来说:如果想要预测明天的天气,就将之前一段时间的天气打包成一个 token 传入模型。这样既可以学习到数据时序的前后关系,也可以学习到不同特征之间的相互作用。
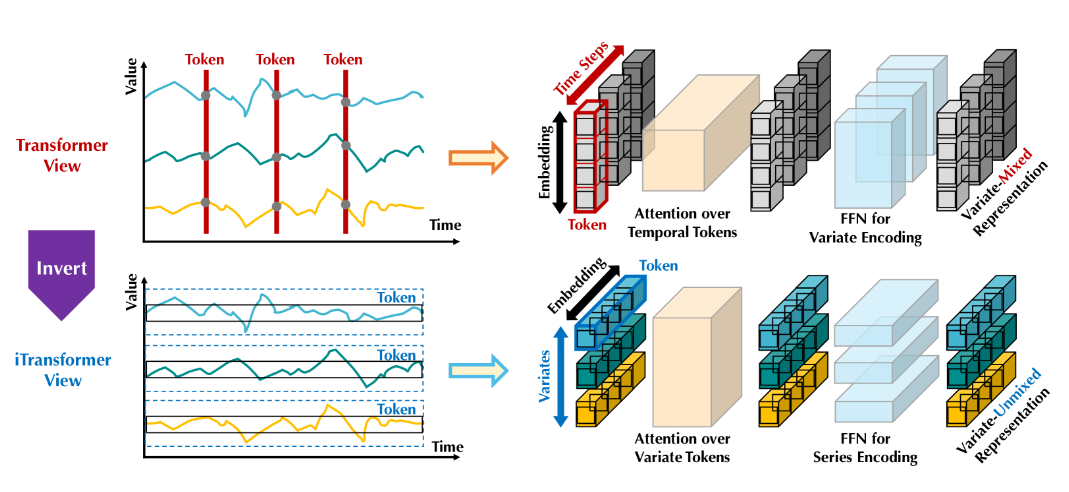
图 -2 基础模型 (上) 与将每个时间步嵌入到时间 token 的 Transformer,iTransformer 将单个变量的整个序列独立嵌入到变量 token 中,这样多变量相关性可以通过注意力机制来描述,序列表示由前馈网络编码。
摘要
目标: 解决 Transformer 模型在预测具有大范围回溯窗口的时间序列时性能下降和计算爆炸的问题。
方法: 提出 iTransformer 的模型,该模型通过重新利用 Transformer 架构的基本组件来解决问题。iTransformer 只对转置的维度应用注意力机制和前馈网络。将与单个变量相关联的一系列时间点嵌入到变量 token 中,这些 token 被注意力机制用于捕捉多变量之间的相关性;同时,对每个变量 token 应用前馈网络以学习非线性表示的时序规律。
结果: iTransformer 模型在具有挑战性的实际数据集上取得了最先进的结果。它提高了不同变量之间的泛化能力,并更好地利用了任意回溯窗口,成为时间序列预测的良好基础骨架。
方法
预测使用前 T 步的 X 来预测将来 S 步的 Y,其中 X,Y 都包含 N 个变量。模型结构如下:
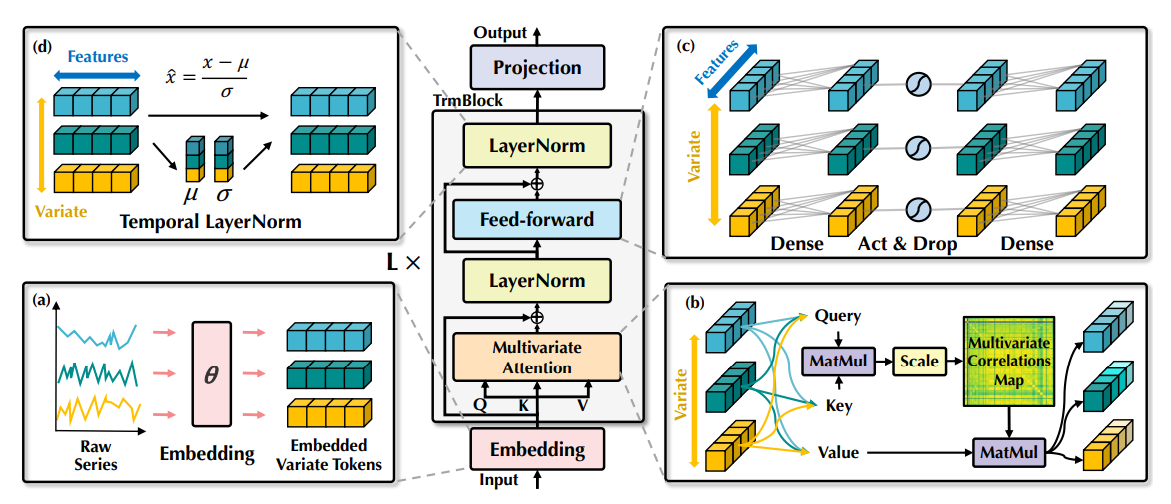
图 4:iTransformer 的整体结构,它与 Transformer 的编码器有着相同的模块结构:(a)不同变量的原始系列独立嵌入到 token 中。(b)自注意力应用于嵌入的变量 token,具有增强的可解释性,揭示了多变量相关性。(c)每个 token 的序列表示由共享前馈网络提取。(d)采用层归一化法来减少变量之间的差异。
简单地说,该模型使用了自我注意力机制来学习变量之间的关系,并且利用前馈神经网络(MLP)来学习时序变化的规律。最后,通过一个简单的投影层(Projection)生成对未来各个变量的预测 Y。
实验
实验包括 6 个真实世界的数据集:ETT、天气、电力、交通、能源等。
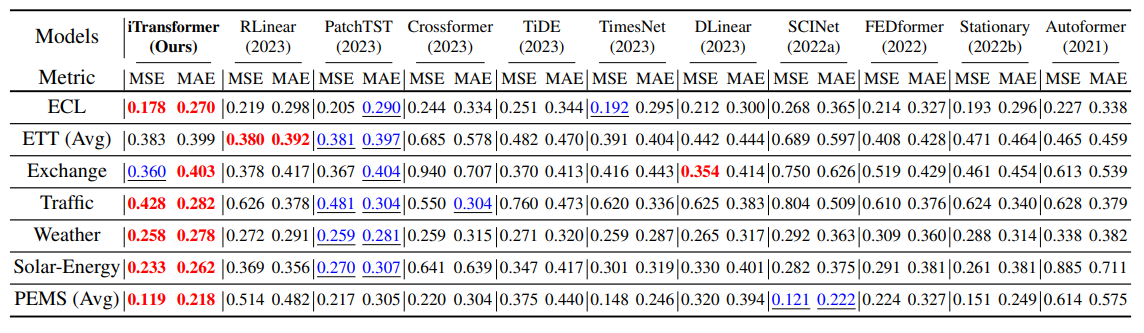
主实验多变量预测结果如下:
相关论文
- TimeLLM
- TimeGPT