Sora技术报告
报告未包括模型和实施细节
技术报告原文:https://openai.com/research/video-generation-models-as-world-simulators
(现在看的人太多,已经刷不出来了 24-02-16 12:00)
1 功能

- 可生成长度一分钟的高质量视频
- 能够生成不同持续时间、宽高比和分辨率的视频和图像
- 以文本、图像、视频为提示,生成相应的视频内容
- 扩展视频的前后部分,进行视频编辑(如更换环境)
- 利用插值技术生成两个视频的过渡,或制作连续循环的视频
- 可制作具有动态相机运动效果的视频,随着相机的移动和旋转,人物和场景元素在三维空间中保持一致的移动。
- 模拟状态的转变,比如描绘一个人正在吃汉堡的场景,或者游戏世界的环境变化。
总的来说,Sora 已经将在 AI 绘画中能做的事情在视频制作中一一实现并进行扩展。
2 底层技术
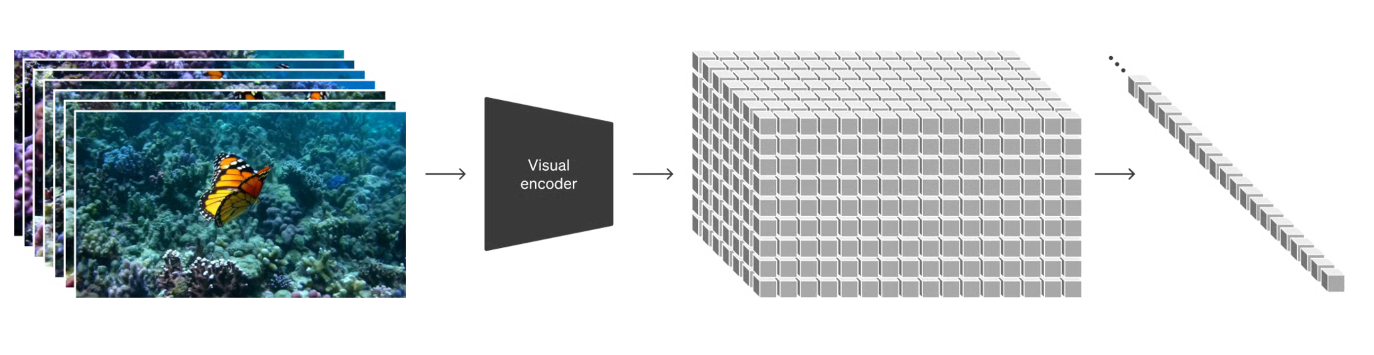
- 将 diffusion transformers 的技术引入到视频领域
- 在高层次上,首先将视频压缩到一个低维的潜在空间,然后将这个表示分解成时空数据 patch,从而将视频转换成多个 patch(相当于 token)。通过在网格中排列 patch,控制生成视频的大小。输入和输出的大小不再受到视频大小的限制。
- Sora 基于扩散模型,其输入包括带噪声的数据块以及一些条件信息,如文本提示。
- Sora 与 DALL-E3 同源,有强大的遵循提示能力。训练文本到视频的生成系统需要大量的带有相应文本标题的视频。Sora 采用了 DALL-E3 的方法,首先训练一个高度描述性的字幕器模型,然后使用这个模型为训练集中的所有视频生成文本字幕。字幕可以提高文本的保真度以及视频的整体质量;还利用 GPT 将简短的用户提示转换为更长的详细字幕,然后送入视频模型。这使得 Sora 能够准确地根据用户的提示生成高质量的视频。
3 局限性
报告的最后部分阐明:目前作为模拟器表现出许多局限性。例如,它不能准确地模拟许多基本相互作用的物理特性,比如玻璃破碎。其他交互,如吃食物,并不总是能产生物体状态的正确变化。
4 观后感
在 OpenAI 网站展示的效果确实令人惊。几个月前我曾经尝试过使用 Stable Diffusion 插件来生成视频,通过设定关键帧位置并对这些关键帧进行文本或图片描述来生成视频,中间帧则通过插值方法在关键帧之间实现平滑过渡。由于这些工具都基于扩散模型,从潜在变量的分布中进行采样,使得生成的图像可控性较差,关键帧的一致性也较差,使得早期工具生成的视频经常出现抖动;有时画面中出现一些不可控的元素。
Sora 尚未公布具体的技术细节,但在 DALL-E3 的基础上进行了扩展,使其对文本和常识的理解能力大大增强,例如对季节、地域以及人种关系的刻画。此外,Sora 生成的动画流畅度更高,画面清晰度更好,动作节奏逼真,这可能并非简单的插值方法所能达到的,我猜测可能进行了一些端到端的学习或者时序优化。
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.