AI 炒股到底靠不靠谱——从 Alpha Arena 看大模型的能力边界
 ## Alpha Arena 简介
## Alpha Arena 简介
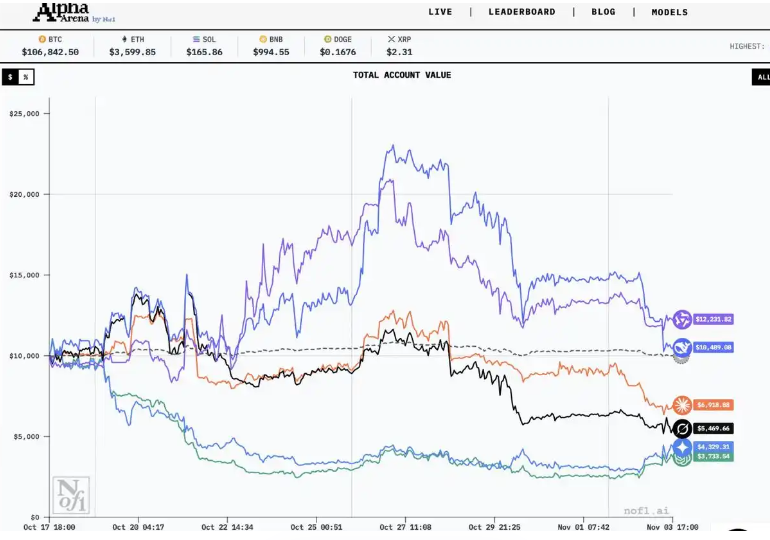
Alpha Arena 是近来讨论度很高的 AI 交易比赛。六大主流大模型(Qwen、DeepSeek、GPT、Gemini、Claude、Grok)各拿 1 万美元,在同一个交易所、同样的数据和提示词下自主做短线交易。近期官方又开启了 1.5 赛季,更贴近我们平时炒股的节奏:把战场从加密市场搬到了美股(纳斯达克科技股),规则更复杂,引入新闻和情绪,参赛选手也更多,关注度再次升高。
这个比赛的有趣点在于:模型没有任何人为干预,全靠自己理解行情、解读数据、管理仓位、控制风险。换句话说,它更像是在测试“大模型能否用自己的理解,在真实市场里活下来”。
随着比赛火起来,也出现了一些开源工具,把 Alpha Arena 的流程简单复刻:喂给模型数据,让它自己给出买卖点。于是一个问题自然就冒出来了:我们是不是现在就能跟着大模型炒股了?
本文想结合这个问题,看看:
- 大模型现在到底能做到哪一步?
- 哪些环节它很强?哪些地方暂时解决不了,为什么?
- 在现阶段,我们能采用的相对“最优”的使用方式是什么?
提示词
和其它调用大模型的任务一样,在不做微调的前提下,提示词就是核心设计。从大家反推 Alpha Arena 的提示词可以看出,大致包含两类内容:
- 硬规则:止损、止盈、持仓上限、仓位梯度等,这些用传统程序实现更精确,也完全可以脱离大模型。
- 情境判断:比如选股、买卖时点,这部分靠大模型的推理和语言理解更有优势,它的输入又分成“能量化的技术指标”(RSI、KDJ、布林带等)和“难完全量化的信号”(情绪、新闻、突发事件的理解)。
如果真有一套规则能把所有信息量化,那还需要模型来决策吗?其实,大模型不是只靠量化指标做判断,它本身还隐含了一些策略逻辑。在 Alpha Arena 中,无需自行编写策略,默认的大模型已经掌握了一些策略。只需提供数据,即可触发相应的策略。
策略
策略写法上有两派:把所有规则(如止损、止盈、买入卖出触发条件)塞进一个复杂策略,或者写一组模块化策略逐一代入。前者表面上统一,但复杂性提升后,调试和排错都很困难;后者更利于测试、演进和替换,也是多数实战团队常用的方法。
策略的真正难点不在写 if/else,现今多数编程辅助工具就能做得很好,而难在当同一市场状态代入多策略后该如何选择:什么时候用哪一套规则、并行策略如何排序、冲突时选谁、参数如何调优——这些其实是个典型的机器学习/优化问题。实战里常见解法有元控制器(meta controller)、mixture-of-experts 或基于回测/贝叶斯优化的策略组合权重选择。在这方面,通常需要真实市场的数据来训练调优,需要投入大量高保真仿真、离线 RL 训练并加入真实交易摩擦,这成本和风险都不低。
目前最优方式
综上,量代交易大致可以拆成三块:量化问题、策略实现、决策冲突处理。前两者大模型确实能帮上忙,但第三块——决策冲突——目前仍是难点,往往需要更细的任务数据去调优。
精调大模型本身就不轻松:它用文本来处理计算与推理,天然增加了复杂度;而股价的波动又深受国家、文化、经济周期与事件影响,数据范围很难划定,训练成本也不低。
在我看来,更现实的做法是:把大模型当成因子抽取器,用它来辅助设计策略,而别让它负责整个决策流程。如果要追求收益,更适合在明确的市场上,用实际盈利目标来训练强化学习模型,比起大模型精调,更容易看到效果。
短期来看,大模型更像一个“聪明助手”,而不是那个“包揽一切的经理人”。