论文阅读_图像生成_unCLIP
读后感
OpenAI 出品,应用于 DALL-E 2。主要实现了以文本为条件生成图像。它在图像的还原和生成过程中,利用了图像与文本间的映射关系,文本可以看作是人对图片内容的抽象,它让模型从人的视角“看”图片,识别了其中人觉得最重要的内容;在图片内容和人类概念之间建立联系,并能通过文本描述的概念来生成和编辑图片。
从技术层面看,它主要基于 CLIP,Diffusion 模型,并在 GLIDE 的方法之上进行了改进(之前 GLIDE 尝试了有分类的 CLIP,本文尝试了无分类的 CLIP;GLIDE 对 Diffusion 中加噪图片训练 CLIP 对齐嵌入,本文用不加噪图片做 CLIP)。
介绍
CLIP 模型在图片和文本之间建立映射关系,能很好的获取图片的含义和风格。本文基于 CLIP,提出了两阶段模型(如图):首先,生成给定文本描述对应的 CLIP 图像嵌入,然后,用解码器生成以图像嵌入为条件的图像。其解码器尝试了自回归和扩散两种方法,发现扩散模型效率更高。
其核心逻辑如图所示:虚线上结合了文本和图像的表示空间;虚线下是生成图片的过程,用文本嵌入产生一个图像嵌入,然后利用这个嵌入在条件约束下送入扩散解码器产生最终图像。
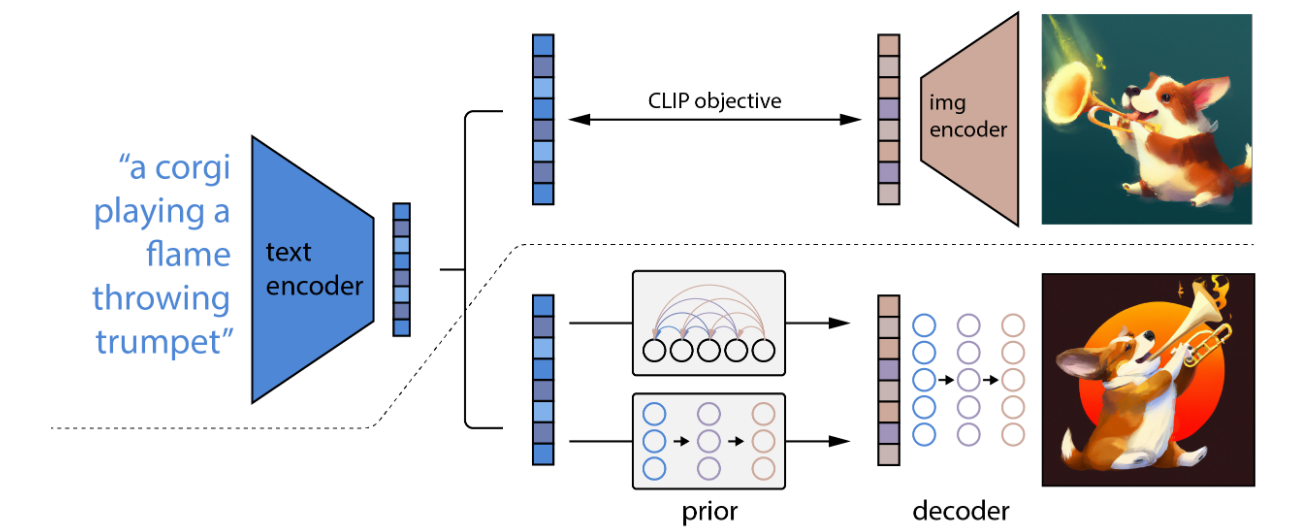
方法
数据集由成对的 (x, y):图像 x 和它们对应的描述 y 组成,用 zi 和 zt 分别表示 CLIP 图像和文本嵌入。
\[ P(x \mid y)=P\left(x, z_{i} \mid y\right)=P\left(x \mid z_{i}, y\right) P\left(z_{i} \mid y\right) \]
利用上述公式,生成图片,其中先验(上图中 prior)P (zi | y),生成以字幕 y 为条件的 CLIP 图像嵌入 zi;解码器(上图中 Decoder)P (x|zi, y),生成以 CLIP 图像嵌入 zi (以及可选的文本标题 y) 为条件的图像 x(具体训练细见附录 C)。
解码器 Decoder
使用扩散模型生成基于 CLIP 图像嵌入 (以及可选的文本标题) 的图像。基于 GLIDE 模型做了一些修改(GLIDE 模型使用加噪后的图片训练 CLIP),将 CLIP 嵌入投影到额外的 4 个上下文标记中,这些上下文标记串联到 GLIDE 文本编码器的输出序列中;并在训练过程中随机丢弃文本标题 50 % 的来实现无分类器指导;另外,还考虑了上采样以改进模型精度,以及提升模型鲁棒性的方法。
先验 Prior
上述编码器可用嵌入空间数据生成图像,但还需要一个先验模型,从标题 y 生成 zi,以便从文本生成图像。本文探索了两种不同的模型作为先验模型:
- 自回归先验
- 扩散先验
其中扩散模型效率更高。训练一个带因果注意力掩膜的解码器 Transformer,之前的扩散先验由:编码文本、CLIP 文本嵌入、扩散时间步嵌入、带噪 CLIP 图像嵌入、最终通过 Transformer 预测不带噪 CLIP 图像嵌入。本文生成 zi 的两个样本,并选择与 zt 点积较高的样本来提高采样质量。并且发现更好的 Diffusion 方法是训练模型直接预测不带噪的 zi,因此改进了 Diffusion 损失函数。
\[ L_{\text {prior }}=\mathbb{E}_{t \sim[1, T], z_{i}^{(t)} \sim q_{t}}\left[\left\|f_{\theta}\left(z_{i}^{(t)}, t, y\right)-z_{i}\right\|^{2}\right] \]
另外,还使用主成分分析 (PCA) 对 CLIP 图像嵌入 zi 进行降维。通过在原始的 1024 个主成分中只保留 320 个主成分,能够保留几乎所有的信息,从后面实验部分,主成分中越重要的维度对应的概念越核心。
操作图像
下面展示了几种应用模型的方法:
生成语义相似的图像
给定一幅图像 x,可以生成具有相同本质内容(主体元素和风格)但在其他方面不同的相关图像,如形状和方向。具体方法是通过η值控制 DDIM 采样的随机性。

上方是原图,下面九张为修改后生成的图。
混合图像
混合 x1,x2 两张图(最左和最右两张),通过对输入图像的嵌入使用球面插值在它们的 zi1 和 zi2 之间旋转。

修改图像
通过语义描述修改图像。输入是一个图像和对它的描述,以及转换目标的描述,如图第四行:输入为冬天图片,目标是将其转成秋天的图片。实现方法是计算两个输入标题嵌入的差值,然后使用插件方法在图像嵌入和文本差值间旋转。

探索稳空间
PCA 重构提供了一种探测 CLIP 潜在空间结构的工具。在图 -7 中,右侧是原图,对 CLIP 的嵌入空间降维,原空间维度为 1024,仅保留重性为 24,30,40... 320 的 PCA 维度进行重建。可以看到不同维度编码了哪些语义信息。
我们观察到重要性高的 PCA 维度保留了粗粒度的语义信息,如场景中的物体类型,而重要性相对低的 PCA 维度编码了更细粒度的细节,如物体的形状和精确形式。
例如,在第一个场景中,重要的维度只有食物,也许还有一个容器,而增加维度后则有西红柿、绿植和瓶子。

之后,作者还对图片的逼真度、多样性和美学性进行了评测,展示 unCLIP 优于之前模型。
Zotero 地址
Hierarchical Text-Conditional Image Generation with CLIP Latents
zotero id: I52IZHL8