论文阅读_语音转换_SoftVC
1 |
|
1 读后感
语音转换的目标是在不改变内容的前提下,将任意说话人的声音转换为目标说话人的声音,论文的目标是通过自监督方法来实现这一功能。
在这个任务中,无监督学习通常会比有监督学习产生更好的效果。以前的无监督学习方法通常是提取音频特征,对这些特征进行聚类,从而构建语音单元的字典。本文提出了一种新的方法,称为软语音单元,它训练模型直接学习语音与字典单元之间的映射关系。
2 摘要
目标: 语音转换系统将源语音转换为目标语音,保持内容不变。本文目标是,提升自监督学习方法的语音转换质量。
方法: 提出了通过预测离散单元的分布来学习的软语音单元。
结论: 通过对不确定性进行建模,软单元可以捕获更多的内容信息,从而提高转换后的语音的可理解性和自然度。
3 引言
语音转换系统的目标是捕获语言内容的同时,舍弃说话人的特定细节。然后,替换说话人的信息,以合成目标说话人的语音。无监督语音转换试图通过无标签或并行语音学习来解决这个问题,但目前无监督系统与有监督系统在质量和可理解性上仍存在差距。
本文提出了一种名为“软语音单元”的新方法。它使用类似于微调的过程,训练一个网络来预测离散语音单元的分布。通过对离散单元分配中的不确定性进行建模,保留更多的内容信息。
本文的主要贡献如下:
- 提出了一种用于语音转换的新方法——软语音单元,并描述了一种从离散单元中学习的方法。
- 相较于离散语音单元,软语音单元能够提高语音的清晰度和自然度。
- 在跨语言语音转换中,软语音单元能够更好地迁移到未见过的语言。
4 方法
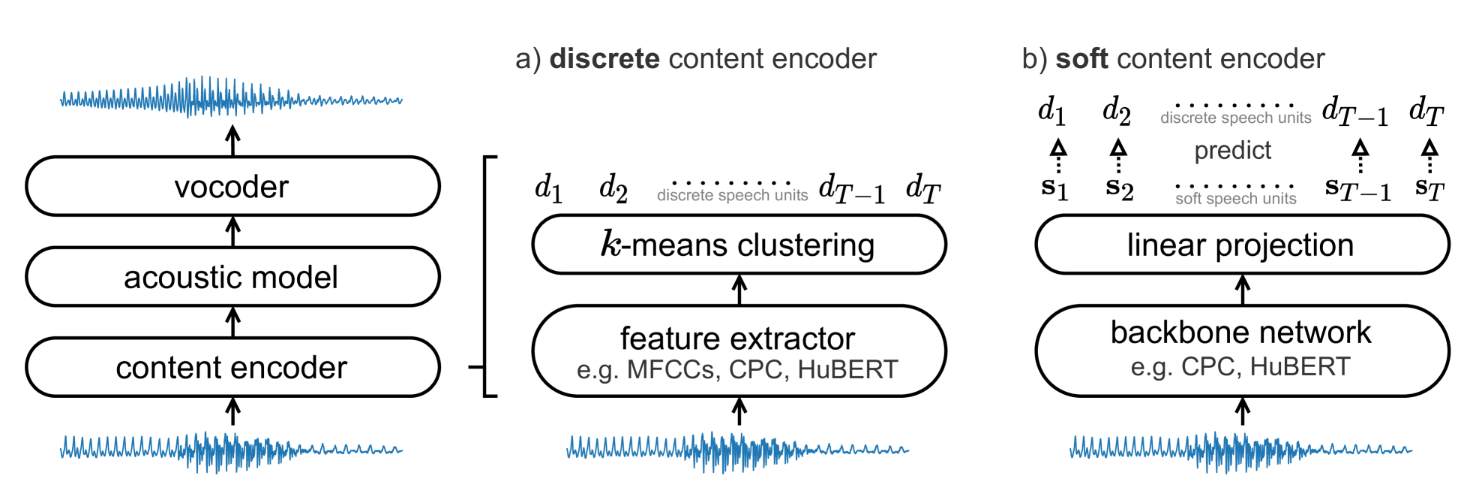
如图所示:系统由三个组件组成(左图):内容编码器、声学模型和声码器。内容编码器从输入音频中提取离散或软语音单元(分别如图 1a 和 1b 所示);声学模型将语音单元转换为目标频谱图;最后,声码器将频谱图转换为音频波形。
4.1 内容编码器
4.1.1 离散内容编码器
离散内容编码器由特征提取和 k- 均值聚类两个部分组成(如图 1a 所示)。特征提取可以使用各种不同的特征提取器进行;接着,对这些特征进行聚类,以构建离散语音单元的字典。离散内容编码器将输入的语音映射到一系列离散的语音单元。
然而,语音的空间并非离散的。因此,离散化的过程可能会导致一部分内容信息的丢失。
4.1.2 软内容编码器
直接使用特征提取器的输出而不进行聚类的方法,其表示中包含了大量的说话人信息,这对于语音转换来说并不适用。因此,本文提出了一种新方法,即训练软内容编码器来预测离散单元的分布。
图 1b 展示了软内容编码器的训练过程。给定一个输入语句,首先提取一系列离散语音单元⟨d1,…,dT⟩作为标签。然后,一个主干网络(如 CPC 或 HuBERT)处理这个语句。接着,一个线性层将网络的输出进行投影,生成一系列软语音单元⟨s1,…,sT⟩。每一个软单元都参数化了一个离散单元字典的分布:
\[ p\left(d_{t}=i \mid \mathbf{s}_{t}\right)=\frac{\exp \left(\operatorname{sim}\left(\mathbf{s}_{t}, \mathbf{e}_{i}\right) / \tau\right)}{\sum_{k=1}^{K} \exp \left(\operatorname{sim}\left(\mathbf{s}_{t}, \mathbf{e}_{k}\right) / \tau\right)} \]
其中,i 是离散单元的簇索引,ei 是对应的可训练嵌入向量,sim(⋅,⋅) 用于计算软单元和离散单元之间的余弦相似性,T 是一个温度参数。最后,通过最小化分布和离散目标 ⟨d1,…,dT⟩ 之间的平均交叉熵来更新编码器(包括主干网络)。在测试时,软内容编码器将输入音频映射到一系列软语音单元 ⟨s1,…,sT⟩,然后传递给声学模型。
4.2 声学模型和声码器
声学模型和声码器是文本转语音(TTS)系统中的典型组件。对于语音转换,声学模型的输入是语音单元,而不是音素或字素。声学模型将语音单元转换为目标说话人的频谱图。然后,声码器将预测的频谱图转换为音频。有多种高保真的声码器可供选择,包括 WaveNet。
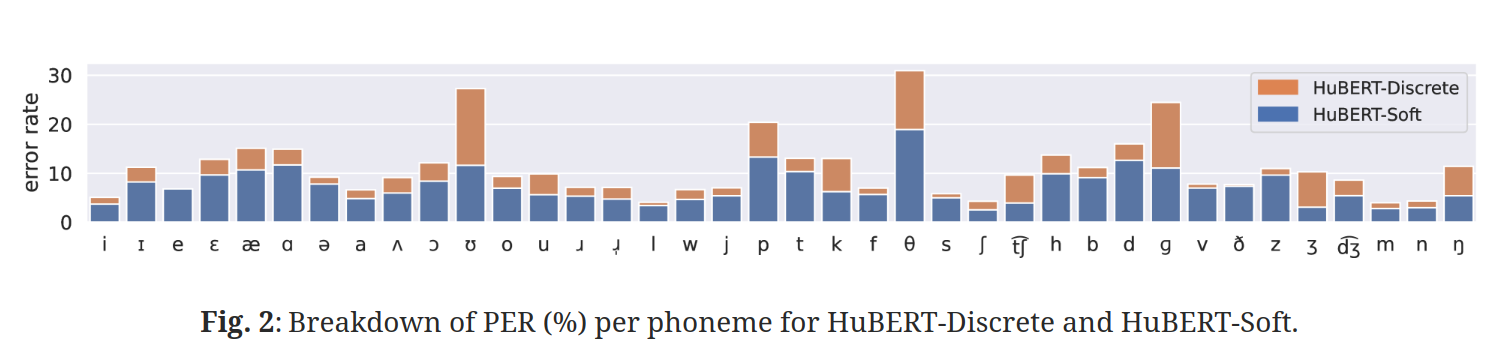
5 实验
图 2 展示了两个模型对每个音素的错误率。