RepoCoder:通过迭代检索和生成实现存储库级代码完成
1 | 英文名称: RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation |
读后感
三句话能说明白的,就不要花太长时间。
最初的代码生成采用了 in-file 方式,仅将当前代码内容传递给模型;后来,采用了 RAG 方式,将项目中相关代码也传递给模型;文中提出的 RepoCoder 通过迭代的方式,先将待生成的代码转给模型,让模型预测代码段,然后在当前项目中找到与预测代码段最相似的段落,再将其传递给模型作为生成代码参考,迭代多次。
摘要
目标:提出 RepoCoder 框架来解决代码补全工具难以利用散落在不同文件中有用信息的挑战。
方法:RepoCoder 框架通过相似性检索器和预训练代码语言模型在迭代的检索 - 生成流程中整合,简化了存储库级别的代码补全过程。
结论:实验结果表明,RepoCoder 在所有设置中将传统的 In-File 完成基线提高了超过 10%,并始终优于普通的检索增强代码补全方法。
作者团队还为存储库级代码完成任务提供了一个新的基准 RepoEval,它由涵盖行、API 调用和函数体完成场景的最新和高质量的真实存储库组成。它相对于 In-File 和 RAG,更进一步。
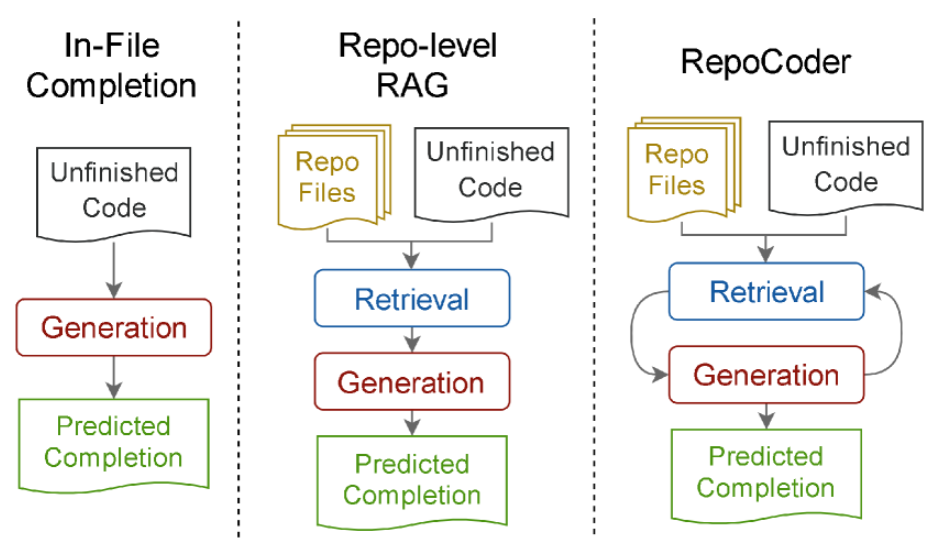
方法
总体框架
RepoCoder 是是一个迭代检索生成管道,对于 i 第 -th 次检索生成( i>1 )迭代,RepoCoder 利用前面的模型预测 y^i−1 来为检索过程构造一个新查询。这导致生成另一组相关代码片段 C 。随后,使用 C 构造一个新的提示,从而生成一个新的预测 Y 。新生成的代码完成既可以用作 RepoCoder 的输出,也可以用于后续的检索生成迭代。
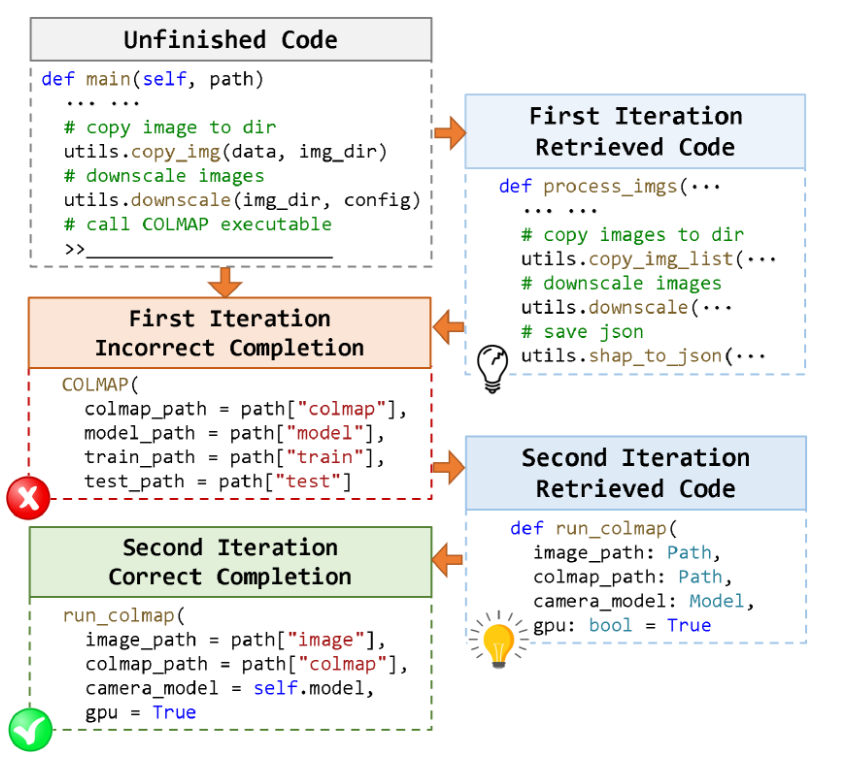
代码检索
采用了滑动窗口方法。滑动窗口遍历存储库中的文件,并提取适合窗口大小的连续代码行,表示为 Sw 。滑动窗口在每次迭代中移动固定数量的行,这称为滑动大小,表示为 Ss。
在初始检索过程中,当没有可用的模型预测时,将使用未完成代码 X 的最后一 Sw 行来制定查询(再纳入之后的一些行); 在第 i - 次迭代( i>1 )期间使用先前生成的代码 Y^i−1 扩充了检索查询。
代码生成
RepoCoder 框架中使用的生成器可以是任何预训练的语言模型,能够在给定特定提示的情况下预测后续标记。
在 RepoCoder 框架中,我们从存储库中检索最相关的代码示例 C,并将它们与未完成的代码 X 连接起来。为了确保可读性和理解性,我们创建了一个无缝集成 X 和 C 的提示模板。检索到的代码片段根据其与查询的相似性分数按升序排列。每个代码段都附带其原始文件路径,提示中包含的最大代码段数(表示为 K )取决于可用的提示长度。最终,提示包含尽可能多的相关信息,以促进代码完成。
