论文阅读_FinRL-DeepSeek:大语言模型赋能的风险敏感强化学习交易代理
1 | 英文名称:FinRL-DeepSeek: LLM-Infused Risk-Sensitive Reinforcement Learning for Trading Agents |
1 读后感
最近市场波动较大,不少人感到压力,如何降低资产波动性、实现平稳增长显得尤为重要。这篇论文介绍了一种将强化学习与大模型结合的方法,通过整合新闻等文本信息,优化交易推荐和风险评估。与传统强化学习方法相比,论文通过修改PPO公式,引入模型输出的微调动作和惩罚项,虽收益未显著提升,但回撤更小,表现更稳定。
2 摘要
目标:利用大语言模型从新闻中提取的风险与交易信号,构建一个更稳健、能控制极端风险的强化学习交易代理。 方法:在 CPPO(风险敏感版 PPO)的基础上,注入 LLM 生成的风险评估与交易建议因子,使其直接影响奖励函数与动作决策;并在 Nasdaq-100 上使用 FNSPID 新闻数据、搭配 DeepSeek V3、Qwen 2.5、Llama 3.3 进行回测验证。 结论:加入 LLM 信号后,策略整体收益未必更高,但风险暴露显著下降,回撤更小,表现更稳定,说明文本驱动的风险因子对强化学习交易策略具有实际价值。
3 具体方法
该方法使用 FNSPID 数据集(包含 1999-2023 年的 1570 万条时间对齐的金融新闻记录)。为降低 LLM API 的成本,每天随机为每只股票选择一篇代表性新闻文章,将数据集缩减至 200 万条记录。然后使用 LLMs(DeepSeek V3、Qwen2.5 72B、Llama3.3 70B),通过下列提示词提取股票推荐和风险评估。
论文中使用了改进后的 PPO 策略:条件风险价值 - 近端策略优化(CVaR-PPO),并在这个策略中加入了大模型提取的因子。
3.1 提示词
让大模型直接给新闻打分,将文本描述转化为可量化的因子。
推荐提示词:
"You are a financial expert with stock recommendation experience. Based on a specific stock, score for range from 1 to 5, where 1 is negative, 2 is somewhat negative, 3 is neutral, 4 is somewhat positive, 5 is positive."
风险提示词:
"You are a financial expert specializing in risk assessment for stock recommendations. Based on a specific stock, provide a risk score from 1 to 5, where: 1 indicates very low risk, 2 indicates low risk, 3 indicates moderate risk (default if the news lacks any clear indication of risk), 4 indicates high risk, and 5 indicates very high risk."
3.2 CVaR-PPO
CVaR-PPO 即 CPPO,来自 2022 年的论文:doi: 10.24963/ijcai.2022/510。它在标准 PPO 的目标上 加了对尾部大亏损的惩罚项(基于 CVaR)
\[ LCVaR-PPO(θ,η,λ)=LPPO(θ)+λ(1−α1E[(η−D(πθ))+]−η+β) \]
D(πθ) 是轨迹回报;\((η−D)+=max(0,η−D)\) 表示超过阈值 η 之下的亏损(即尾部损失);α 是置信水平(例如 0.05 表示最坏 5%);λ 是拉格朗日乘子(控制惩罚强度),β 为辅助惩罚项。也就是说,它在不修改 PPO 的剪切机制的同时,把“避免极端亏损”作为额外优化目标强制引入。
3.3 将模型打分注入 CPPO
将 LLM 从新闻中提取的风险等级转化为一个缩放系数,用来调整轨迹回报(D)。
\[
D_{R_f}(\pi)=R_f\cdot D(\pi)
\] - 如果新闻判断风险高 → (R_f < 1 ) → 削弱回报 → 更容易落入
CVaR 罚项 → 策略更保守
- 如果新闻判断风险低 → (R_f > 1 ) → 放大回报 → 鼓励策略多冒险
将 LLM 从新闻中提取的推荐信号作用在“动作上” \[ a′=S_f⋅a \] - (S_f > 1 ) → 强化买入动作(如果 LLM 推荐“看多”) - (S_f < 1 ) → 压制买入 / 放大卖出 动作(如果 LLM 推荐“看空”) - (S_f ≈ 1 ) → LLM 的影响极弱(稳定训练)
总结:
| 因子 | 注入位置 | 数学作用 | 行为作用 |
|---|---|---|---|
| R(风险因子) | 轨迹回报 (D) | (D' = R_f D) | 改变奖励结构,影响 CVaR 罚项,属于 “风险认知层” |
| S(推荐因子) | 策略输出动作 (a) | (a' = S_f a) | 调节动作强弱,属于 “策略偏置层” |
3.4 实验结果
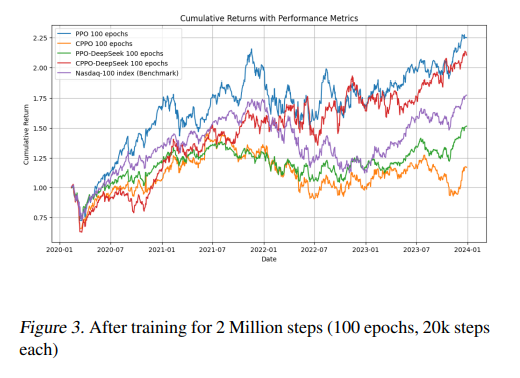
训练到 2 百万步(100 epochs) 后,各策略(PPO、CPPO 及其各自注入 LLM 信号的版本)累积收益对比图。在这个图中,整体收益最好的是直接使用 PPO 策略的,但它也有最大的抖动。大家持有体检更好的可能是红色线,因为收益差不多的情况下,回撤更小。
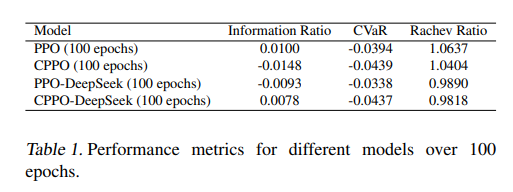
表 -1 中评价了:
- IR:跑赢基准的稳定性
- CVaR:极端亏损的严重程度
- Rachev Ratio:尾部收益与尾部亏损的对比
4 思考
如果直接将 S/R 因子加入特征集 {X},也可以用,但本质上只是“弱耦合”:把信息丢给 PPO,让它自己慢慢体会,想用就用,不想用就当成噪音。论文的做法则是“强耦合”:直接将因子写进奖励和动作里,改动策略梯度本身,实际上是对模型的决策方向进行干预。