论文阅读_模型结构_ControlNet
英文名称: Adding Conditional Control to Text-to-Image Diffusion Models
中文名称: 向文本到图像的扩散模型添加条件控制
论文地址: http://arxiv.org/abs/2302.05543
代码: https://github.com/lllyasviel/ControlNet
时间: 2023-02-10
作者: Lvmin Zhang

1 读后感
ControlNet 几乎是 Stable Diffusion 中最重要的功能插件,利用它可对画面内容进入精准控制。本文介绍了 ControlNet 的原理和具体功能。
ControlNet 是一种对文本生成图像的优化方法。比如:生成 AI 画作时,画面中人体的形态,面部表情都难以精准控制,ControlNet 基于图生图的操作方式,从另一图中提取对应元素,用于新图像的生成,大幅提升了人对大模型的控制力。
具体方法是调整网络结构,基于预训练的扩散模型,根据新输入的描述和指定任务对应的条件进一步训练模型。使模型既可以在小数据量(<50K)时在个人设备上训练,也可以在大数据量时在集群中训练。
其核心技术是在原大网络参数不变的情况下,叠加一个小型网络,以实现最终的调参。
1.1 背景知识
对于文本生成图片的大模型,往往需要考虑以下因素:
- 数据问题:在训练数据量不够大的情况下,解决过拟合/泛化问题。
- 资源问题:解决训练时间和内存问题,使模型在个人电脑上也能训练。
- 形式问题:支持各种图像处理问题具有不同形式的问题定义、用户控件或图像注释。
2 方法
ControlNet 是一种网络结构。如图所示:
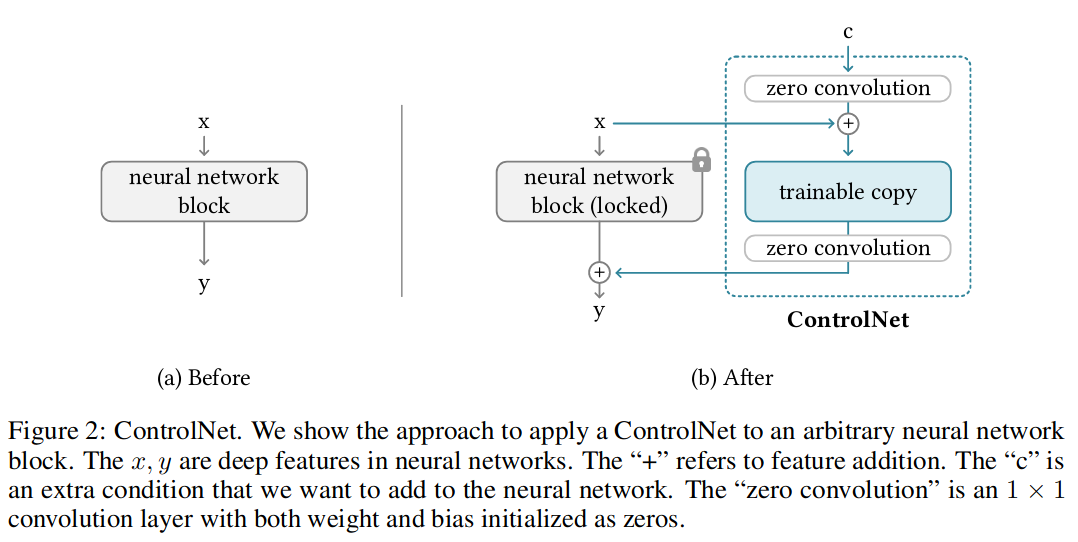
原始网络结构如图 2-a 所示,输入为 x,输出为 y,theta 为网络参数;
\[ y=F(x;\theta) \]
加入了 ControlNet 的网络如图 2-b 所示,它将大模型的权重复制为“可训练副本”和“锁定副本”:锁定副本用于保留原网络能力,被锁定不参与调参;可训练副本在特定任务的数据集上根据条件 c 进行训练,以学习有条件控制;网络输出 y 为“可训练副本”和“锁定副本”两部分叠加的结果。
其中还加入了两个 " 零卷积 " 层 zero convolution(公式中的 Z),它是 1x1 且初始值为 0 的卷积层。
\[ y_c = F(x;\theta)+Z(F(x + Z(c;\theta_{z1});\theta_c);\theta_{z2}) \]
可想见,开始调参时,由于 Z 网络初值是 0,y 值只有等式左边部分,即保留了原始网络;后面逐步调参后,等式右边部分开始变化。
将该结构应用到扩散模型,如图 -3 所示:
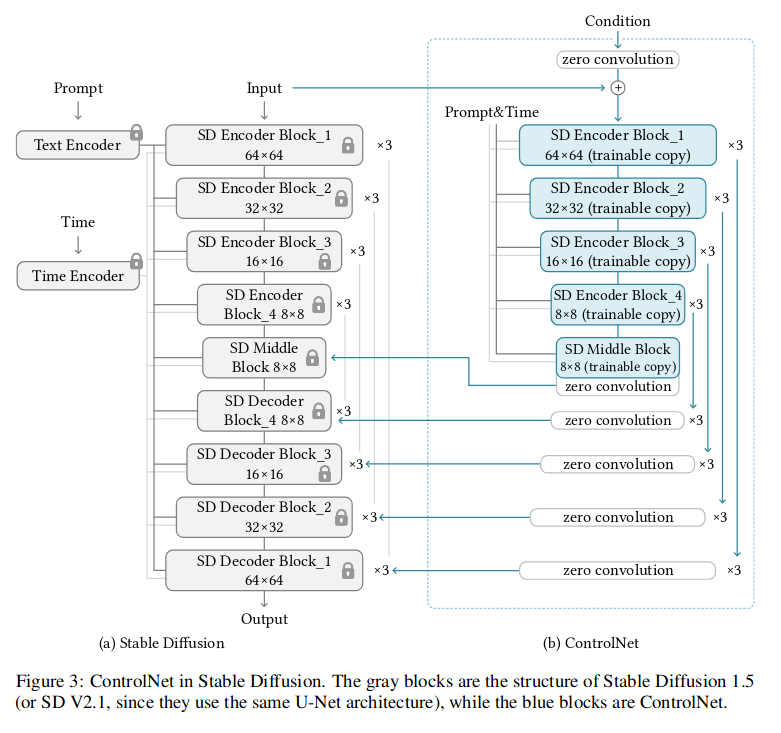
左侧是基础网络,权重被锁定,右侧为 ControlNet 部分,只对其 Encoder 部分进行了调整,使模型训练仅需要增加约 23% 的 GPU 内存和 34% 的时间;同时由于左侧的原始网络参数不变,又使用了零卷积的方法,有效避免了直接在网络上调参带偏网络的问题,同时还可以使 ControlNet 的影响可调节。
3 其它
文章的 3.5 节及附录部分列出了几种常见的 ControlNet 控制方法,包含:控制人物表情和动作,控制场景深度,控制画面中的线条等,并展示了相应的效果图。可视作功能介绍和效果展示。