大模型+强化学习_利用AI反馈扩展强化学习_RLAIF
1 | 英文名称: RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback |
1 读后感
研究使用机器反馈的强化学习(RLAIF)来替代人工反馈的强化学习。该研究主要集中在大模型领域,并通过一系列实验证明了 RLAIF 的适用范围,还介绍了一些具体的方法,是一篇偏实用性的论文。
另外,从另一个角度考虑,许多大型模型(如 Claude3)似乎已经与人类判断相当一致。那么,我们是否可以利用这些模型生成标注数据,训练其他模型?这是否也可以视为一种知识蒸馏?
2 摘要
目标:研究目的是探索使用 RLAIF (RL from AI Feedback (RLAIF) 方法替代 RLHF 方法,以提高大型语言模型与人类偏好的一致性。
方法:方法包括使用 RLAIF 方法,利用现成的大型语言模型生成偏好,比较不同任务下 RLAIF 与 RLHF 的性能,以及直接提示语言模型得分的实验。
结论:实验结果表明,在摘要、有用对话生成和无害对话生成任务中,RLAIF 与 RLHF 相比表现出相当或更好的性能。
3 引言
大规模使用 RLHF 的一个障碍是它依赖于高质量的人类偏好,而一些高质量的 LLMs 已显示出与人类判断高度一致性。
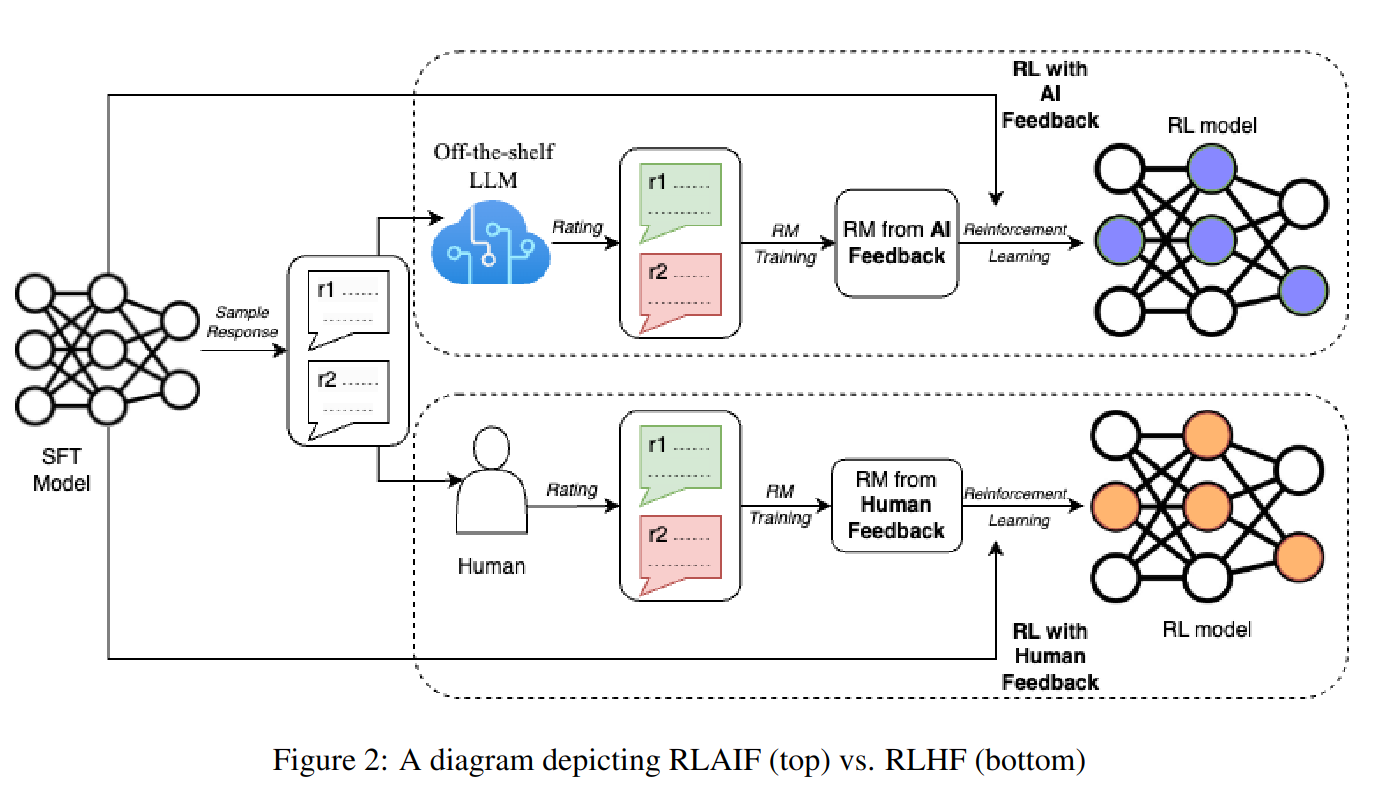
在这项工作中,我们研究了 RLAIF 和 RLHF(见图 2)对三个文本生成任务的影响:摘要、有用的对话生成和无害的对话生成。实验表明,RLAIF 和 RLHF 比 SFT 基线更受人类青睐。这些结果表明,RLAIF 是 RLHF 的可行替代品,它不依赖于人工注释。
大规模使用 RLHF 的一个障碍是它依赖于高质量的人类偏好,而一些高质量的 LLMs 已显示出与人类判断高度一致性。
在这项工作中,我们研究了 RLAIF 和 RLHF(见图 2)对三个文本生成任务的影响:摘要、有用的对话生成和无害的对话生成。实验表明,RLAIF 和 RLHF 比 SFT 基线更受人类青睐。这些结果表明,RLAIF 是 RLHF 的可行替代品,它不依赖于人工注释。
文章主要贡献如下:
- 在进行摘要、生成有帮助的对话和无害的对话的任务上,RLAIF(强化学习的自适应反馈)达到了与 RLHF(强化学习的人类反馈)相当或更优的性能。
- 证明,即使 LLM(大型语言模型)标签器的大小与策略相同,RLAIF 也能改进 SFT(安全性精细调整)策略。
- 发现,在强化学习过程中,直接提示 LLM 进行奖励评分可以优于在 LLM 偏好上训练奖励模型的标准设置。
- 比较了生成 AI 标签的各种技术,并确定了 RLAIF 实践的最佳设置。
4 方法
4.1 用模型生成偏好标签
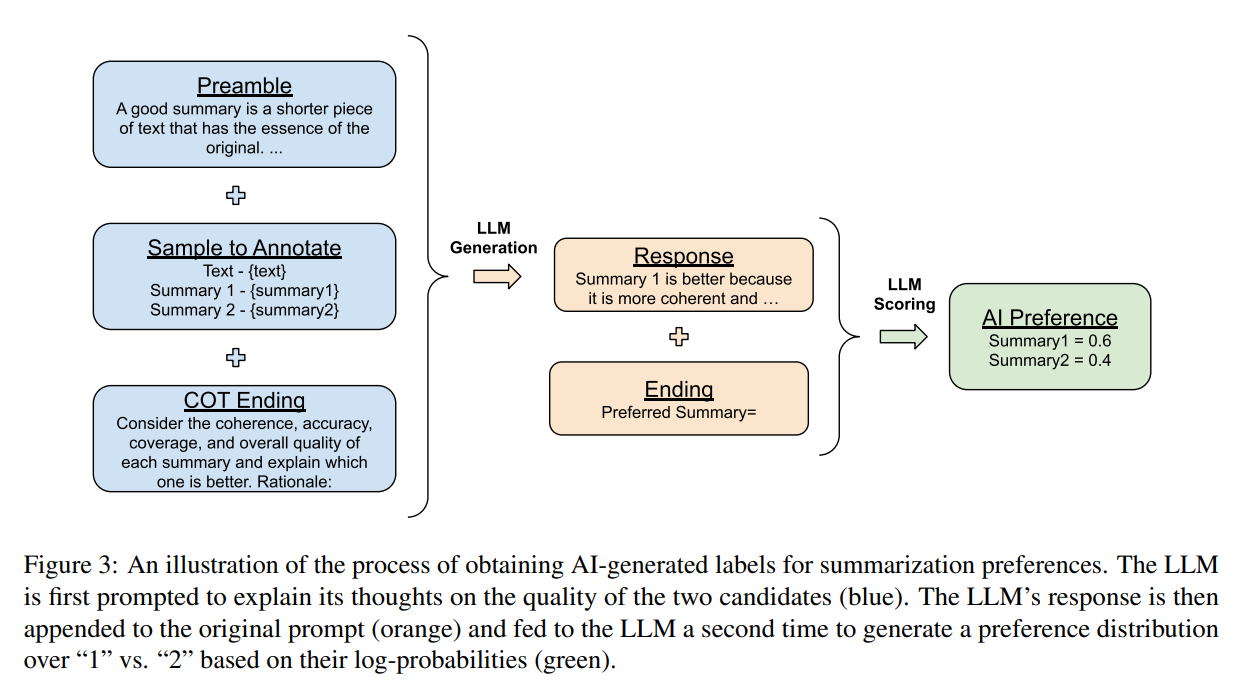
调用模型时提示由以下 4 部分组在:
- 前言 - 介绍说明任务
- Few-show 例子(可选)- 一个输入上下文示例,一对响应,链式思考理由(可选)和一个偏好标签
- 要标注的样本 - 要标记的输入上下文和一对响应
- 结束 - 提示 LLM(例如,“首选应为=”)的结束文本
在将文本输入给 LLM(大型语言模型)后,我们提取生成“1”和“2”这两个标记的对数概率,并计算 softmax 以获得一个偏好分布(读者注:这里的问题是只能得到两者谁更好,没有程度)。
具体实现时,还考虑到选项的位置可能引起位置偏差,于是交换了选项的前后顺序,并让模型进行两次预测取平均值;另外,通过两步推理过程引入了链式思考。
4.2 利用 AI 反馈强化学习
4.2.1 蒸馏 RLAIF
在这种方法中,首先使用大型语言模型(LLM)为任务标记偏好。然后,这些标记被用来训练一个奖励模型(RM),并将其生成的奖励分数的 softmax 应用交叉熵损失。这种方法生成了软标签(例如 0.6, 0.4),并将 RM 分数转换为概率分布,这可以被视为一种模型蒸馏的形式。以此作为奖励训练策略模型。
4.2.2 直接 RLAIF
另一种方法是直接使用 LLM 反馈作为 RL 中的奖励信号。这使得可以绕过训练 RM 的中间阶段,RM 是用来近似 LLM 的偏好的。LLM 被提示在 1 到 10 之间评价生成的质量。然后,计算每个分数标记在 1 到 10 之间的可能性,可能性被归一化为概率分布,计算加权分数,然后将分数再次归一化到 -1,1 的范围。(读者注:有效解决上面提到的问题)
4.3 评价
使用三个指标评估我们的结果:对齐度、胜率和无害率。
对齐度衡量 AI 标记偏好与人类偏好的一致性;胜率评估是给定一个输入和两个生成,人类注释者选择他们更喜欢的生成,政策 A 优于政策 B 的实例的百分比被称为“A 对 B 的胜率”。50% 的胜率表明 A 和 B 同样受欢迎;无害率衡量被人类评估者认为无害的响应的百分比。
5 实验
5.1 数据
实验数据包含:
- Reddit TL;DR:包含 Reddit 帖子及其摘要。
- OpenAI 的人类偏好,每个示例包括一篇帖子,两个候选摘要,以及一个人类注释者的评级,指示哪个摘要更受欢迎。
- Anthropic 有用和无害的人类偏好:人类与 AI 助手之间的对话,每次对话都有两种可能的 AI 助手回应 - 根据人类注释者的判断,一种是首选,另一种是非首选。偏好基于哪种回应对有用的任务更具信息量和诚实,以及哪种回应对无害的任务更安全。
在下采样和过滤后,每个任务大约有 3-4k 个示例。AI 标签器对齐度指标是在这些下采样的数据集上计算的。
5.2 标注
使用 PaLM 2(Google 等人,2023)作为 LLM 进行偏好标签。使用的版本进行了指令调优,但之前没有经过 RL 训练。
5.3 训练
所有的 SFT 模型和 RM 都从 PaLM 2 ExtraSmall (XS) 初始化。SFT 模型通过在 Reddit TL;DR 数据集上微调得到,而 RM 在对应的偏好数据集上微调。在 RL 阶段,策略采用修改版的 REINFORCE 进行训练,策略和价值模型从 SFT 模型初始化。对于摘要和其他任务,RL 的初始状态分别来自 Reddit TL;DR 数据集和偏好数据集。
5.4 人工评价
在实验中,评估员会看到输入上下文和不同策略(如 RLAIF、RLHF 和 SFT)生成的多个回应,然后按质量对回应进行排名。
6 结果
6.1 RLAIF vs. RLHF
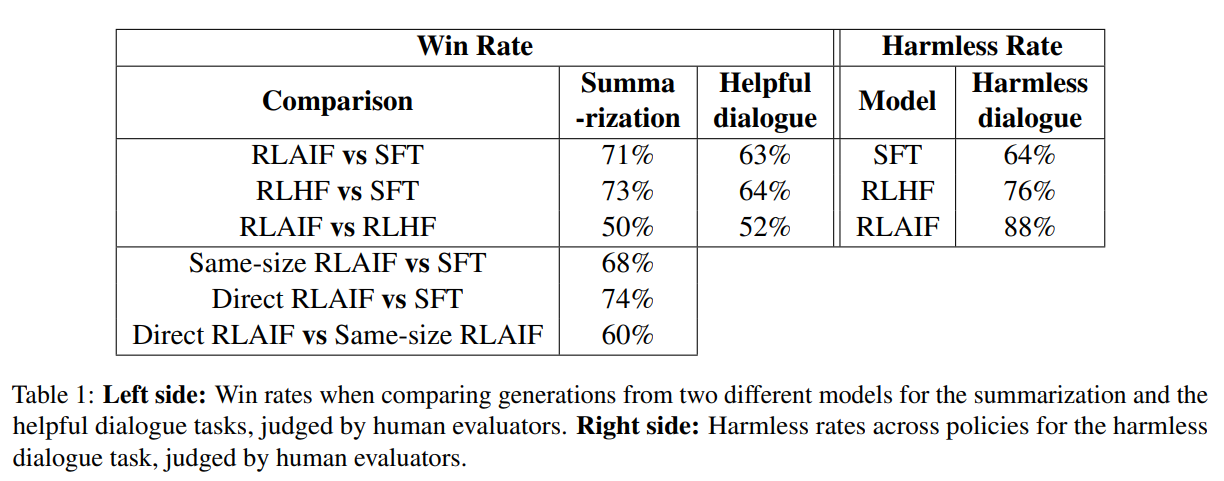
尝试将人类和人工智能的反馈结合起来,但除了单独使用人类反馈之外,没有看到任何改进。如果使用一些技巧,可以稍微改善。机器有与人工反馈类似的效果,并且更节约成本。此外,可以观察到直接使用 RLAIF 效果更好。
6.2 提示的影响
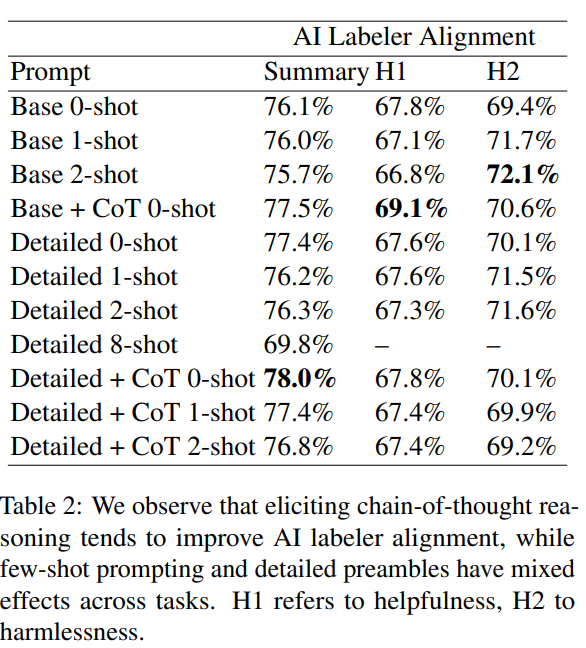
6.3 模型大小对效果的影响

7 定性观察
RLAIF 在 RLHF 没产生幻觉时可能产生幻觉,而 RLHF 产生的幻觉看起来更合理。另外,RLAIF 有时会产生比 RLHF 更不连贯或不符合语法的摘要。