论文阅读_反思模型_Reflexion
1 | 英文名称: Reflexion: Language Agents with Verbal Reinforcement Learning |
1 读后感
论文提出了一种强化学习方法。传统的调优主要是通过训练调整网络参数,而文中提出的方法则是“分析”错误,形成反思的“文字”并保存,在之后的决策中,将其作为上下文以帮助决策。
它利用大模型及其周边方法构造了角色的行为、对结果的评价、当不能达成目标时,利用大模型来反思执行过程中具体哪一步出了问题,并将其作为反思存储。这样就构造了基于当前环境的短期存储,和基于反思的长期存储,结合二者使模型在未来做出更好的决策。
可将其视为把之前在棋类游戏中的强化学习扩展到了角色扮演游戏之中。之前的虚拟世界是棋盘,而现在的智能体置身于一个游戏世界;之前的行为是多步棋的组合,现在是多个行为的组合;之前是根据最终输赢为每一步计算奖励值,现在是利用大模型反思出每一步的对错……
这个方法很巧妙,当然也是因为现在有了各种大模型,链式思维的方法,才能支持该方法的实现。
2 摘要
对于语言代理来说,通过传统的强化学习方法进行试错学习需要大量的训练样本和昂贵的模型微调。论文提出了 Reflexion 框架,通过语言反馈而不是更新权重来强化语言代理。Reflexion 足够灵活,可以整合各种类型和来源的反馈信号,实验证明,它在各种任务中取得显著改进。
3 引言
Reflexion 将环境中的反馈转化为文本摘要,然后将其作为附加上下文添加到下一轮的 LLM 代理中,从以前的错误中学习,以在未来任务中表现更好。这类似于人类如何通过反思以往的失败来形成改进,以便以少量尝试的方式完成复杂任务。
与传统方法相比,Reflexion 具有以下优点:
- 更为轻量,不需要对 LLM 进行微调
- 相比于难以进行准确信用分配的标量或向量奖励,它允许更细致的反馈
- 允许更明确和可解释的情节性记忆形式
- 为未来的决策提供了更明确的行动提示
其缺点是:
- 依赖于 LLM 的自我评估能力(或启发式方法)
- 无法保证成功
文章贡献如下:
- 提出了 Reflexion,一种新的基于语言的强化学习范式,结合了智能体的记忆与 LLM 参数的选择,以优化策略。
- 探索了 LLM 中自我反思的性质,证明自我反思对于少量数据的复杂任务非常有用。
- 引入了包含 40 个具有挑战性的 Leetcode 问题(“困难级别”)的代码生成,涵盖了 19 种编程语言。
- 展示了 Reflexion 在多个任务上相对于强基线方法的改进。
4 相关工作
略...
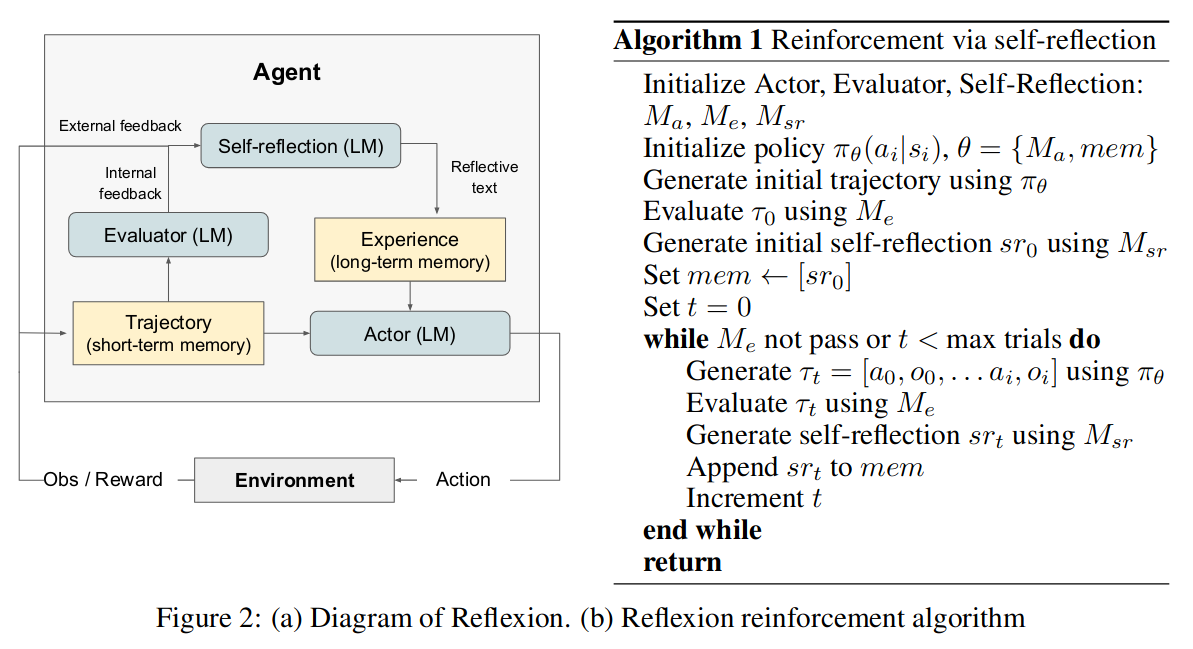
5 方法
5.1 Actor
角色,使用 LLM 实现,它基于可观察的状态,利用提示生成文本和动作。类似强化学习中的基于策略的方法,在时间步 t,从策略 πθ 中采样一个动作 at,它探索了各种 Actor 模型,包括 COT 和 ReAct,从而丰富了探索空间。
5.2 Evaluator
评估器,用于评估 Actor 输出的质量。将生成的轨迹作为输入,计算在给定任务上下文中的奖励分数。对于推理任务,探索基于精确匹配(EM)评分的奖励函数;对于决策任务,采用根据特定评估标准的预定义启发式函数;还使用 LLM 的不同实例作为评估器,为决策和编程任务生成奖励。
5.3 Self-reflection
自我反思,使用 LLM 实现,用于生成基于语言的反思。在给出稀疏奖励信号,如二元状态(成功/失败),当前轨迹及其持久记忆内存。自我反思模型会生成细致入微且具体的反馈,这种反馈相比标量奖励提供更多信息,然后被存储在代理的内存 (mem) 中。如在多步决策任务中,当智能体收到失败信号时,它可以推断出特定动作 ai 导致了后续错误动作 ai+1 和 ai+2。然后,智能体可以用语言声明它应该采取不同的动作 a' i,这将导致 a' i+1 和 a' i+2,并将该经验存储在其记忆中。在随后的试验中,智能体可以利用其过去的经验,通过选择动作 a' i 来调整其在时间 t 的决策方法。这种尝试、错误、自我反思和持久记忆的迭代过程使智能体能够利用信息反馈信号快速提高其在各种环境中的决策能力。
5.4 Memory
内存组件,为 Agent 提供额外的上下文。它提供短期记忆和长期记忆。在推理时,Actor 根据短期和长期记忆做出决定,在强化学习设置中,轨迹历史充当短期记忆,而自我反思模型的输出则存储在长期记忆中。这是反思 Agent 相对于其他 LLM 的关键优势。类似于人类记住近期细节的方式,同时也回忆从长期记忆中提炼出的重要经验。
5.5 The Reflexion process
反思过程,如算法 -1 所示的迭代优化过程。在第一次试验中,Actor 通过与环境交互产生轨迹 τ0。然后评估器产生一个分数 r0;rt 是标量奖励;为了放大 r0,自我反思模型分析 {τ0, r0} 集合以生成存储在内存 mem 中的摘要 sr0。srt 是对试验 t 的语言反馈。Actor、Evaluator 和 Self-Reflection 模型通过循环试验协同工作,直到 Evaluator 认为 τt 是正确的。每次试验后 t、srt 都会附加存入 mem。在实践中,通过存储经验的最大数量 Ω(通常设置为 1-3)来限制 mem,从而不超过 LLM 的上下文限制。
6 实验
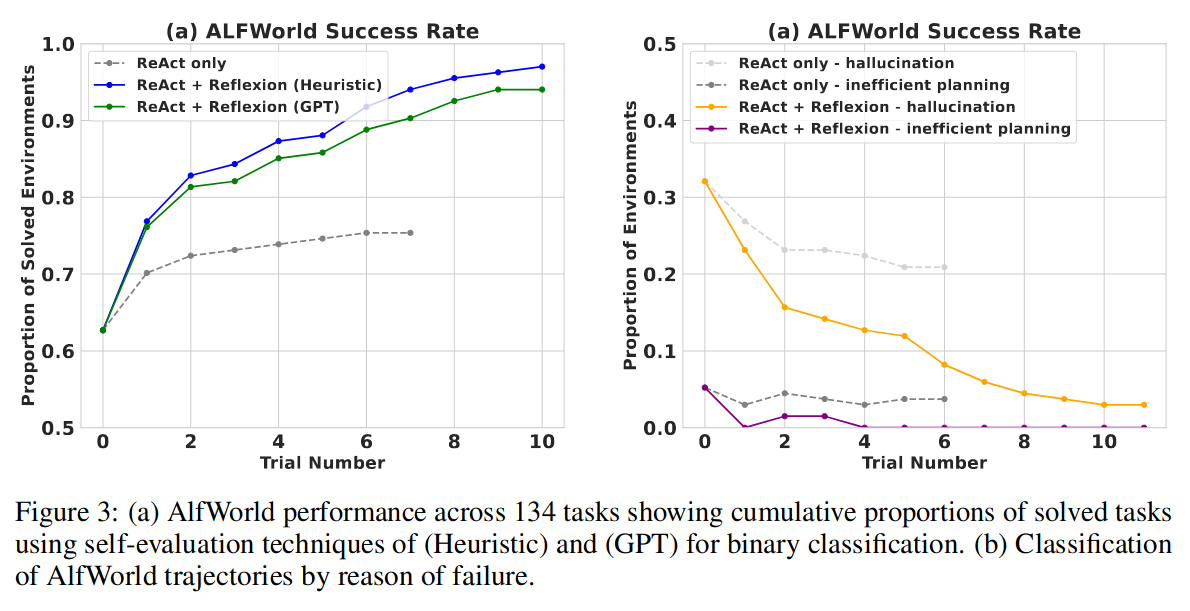
6.1 顺序决策制定:ALFWorld
在 AlfWorld 常见家庭环境中的多步任务中,反思使性能提高了 22%。
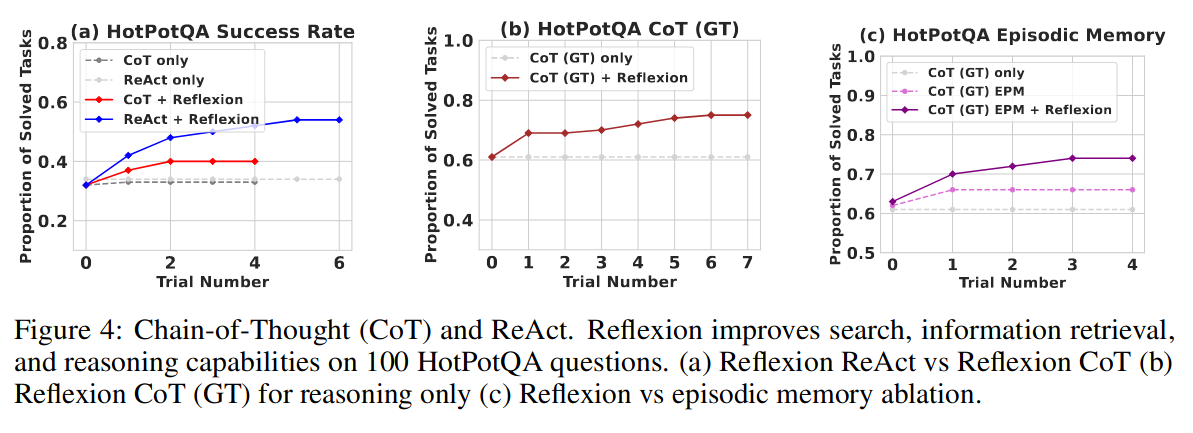
6.2 推理:HotpotQA
HotPotQA 是一个基于维基百科的数据集,包含 113k 个问题和答案对,代理解析内容并在多个支持文档上进行推理。
论文实现了一个反思 + 思维链的 Agent,它可以使用维基百科 API 检索相关上下文,并使用逐步显式思考推断答案。加入反思在该任务中提升了 20%,
6.3 编程
在 MBPP、HumanEval 和 LeetcodeHardGym 上评估了基准和 Reflexion 方法在 Python 和 Rust 代码编写方面的表现。除了 MBPP Python 1,Reflexion 在所有测试中表现优于所有基准准确性。