论文阅读_模型鲁棒性的量化指标
读后感
建立一个框架,用于计算和量化模型鲁棒性。使用者应根据情境,风险偏好,以及分布等角度选择不同的衡量方法。更抽象地讲,它是对不确定性的决策原则。选择不同鲁棒性评价方法会影响决策,尽量使用多个指标结合的方式。
介绍
根据经济学中的不确定型决策原则。在深度不确定性下,存在多种不确定因素共同影响决策的后果。在这样的系统中,系统性能通常使用鲁棒性指标来衡量。
具体方法介绍
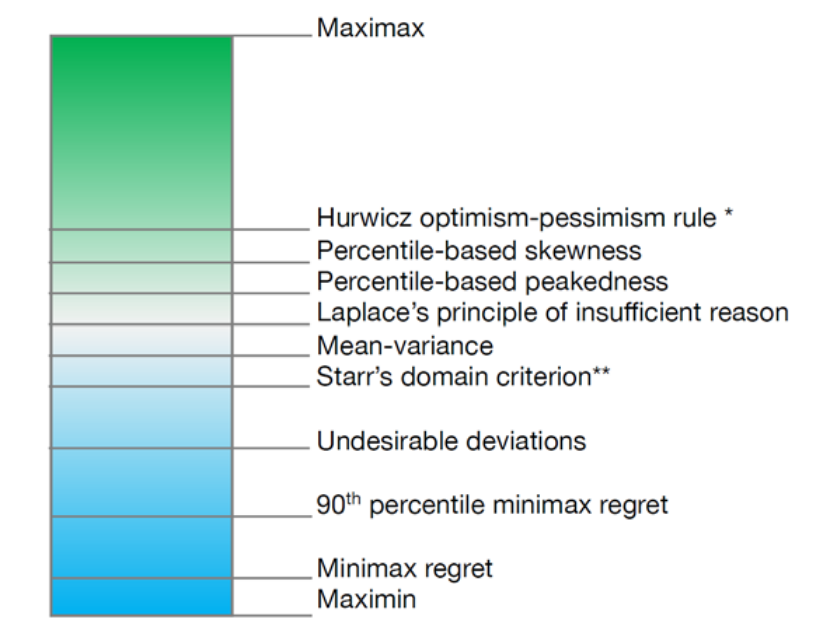
Maximin
悲观原则:有若干种结果,选择每个系列中最坏结果中的最好结果
\[ Maximin = max(min_1, min_2, ..., min_n) \] ### Maximax
乐观原则:有若干种结果,选择每个系列中最好结果中的最好结果
\[ Maximax = max(max_1, max_2, ..., max_n) \]
Hurwicz optimism-pessimism rule
折衷原则:按比例结合乐观和悲观原则
\[ HOR = αMaxmin + (1 − α)Maximax \] ### Laplace's principle of insufficient reason
不充分理由原则:对所有结果取平均
\[ LPIR=1 / n\sum_{i}^{n} real \]
Minimax regret
后悔最小原则:最优 - 实际,也是一种相对悲观的方法
\[ regret_i = max − real_i \] \[ MinimaxRegret = min(regret_1, regret_2, ..., regret_n) \]
90th percentile minimax regret
与 Minimax regret 相似,只是取后悔的 90 分位数
Mean-vaiance
均值方差模型:类似不充分理由模型,通过频率采样,计算分布,估计打分
Undesirable deviations
不良偏差:将偏差的中位数作为打分
Percentile-base skewness
正态分布偏度:描述不对称程度,有左偏和右偏两种,它是对分布的评价(pandas 可提供该统计值)
Percentile-base skewness
正态分布峰度:描述某个分布相⽐于正态分布的峰值⾼低的程度,它是对分布的评价
Starr's domain criterion
斯塔尔阈准则:计算性能与决策者选择的基准进⾏⽐较,并打分, 1 为通过,0 为不通过,计算打分的平均值,得分最高的鲁棒性高。
乐观程度排名如下图所示:
框架
框架由三部分组成:方案 (Decision alternatives),条件(Plausible future conditions),度量方法(Performance metric)。代入机器学习的场景中,如下:
- 方案 ->模型算法,解决一个问题可能有多个算法,x1,x2...xm,每次评价其中一种的鲁棒性
- 条件 ->数据,不同情况下的数据,可视为不同场景,S={s1,s1...sn},比如不同环境下产生的数据,每个算法 xi 需要代入不同场景的数据
- 度量方法 ->评价方法,将各个场景数据 S 代入模型 xi,f(xi,S) 评价模型在各场景下的效果。

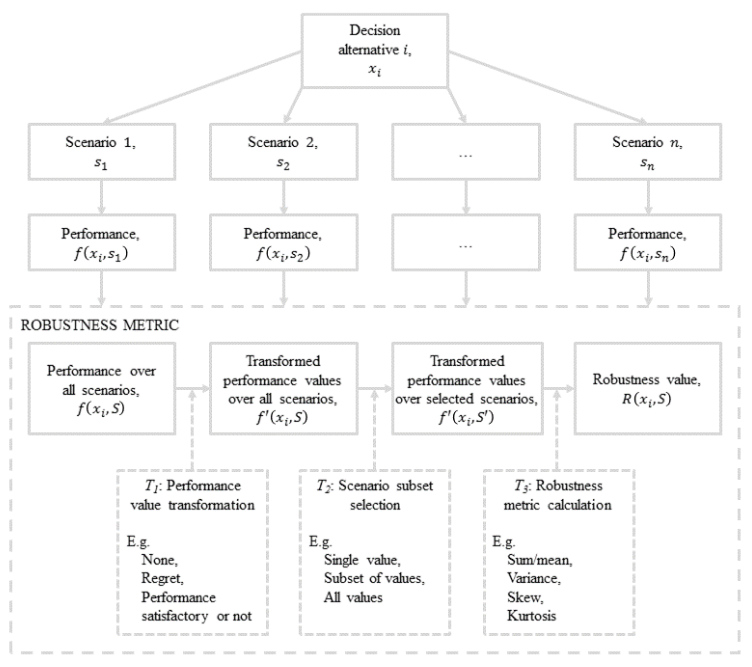
计算其整体鲁棒性可分为以下三步:
- T1:将对模型的评价方法 f 改为 f',比如在后悔最小模型中,把对模型的打分改为最好值与实际值的差。
- T2:选择场景子集,有的方法不需要所有子集参与,比如乐观原则只需要选择效果最好的场景子集。
- T3:融合各个场景子集的结果,比如不充分理由原则会对所有子集的结果取均值。
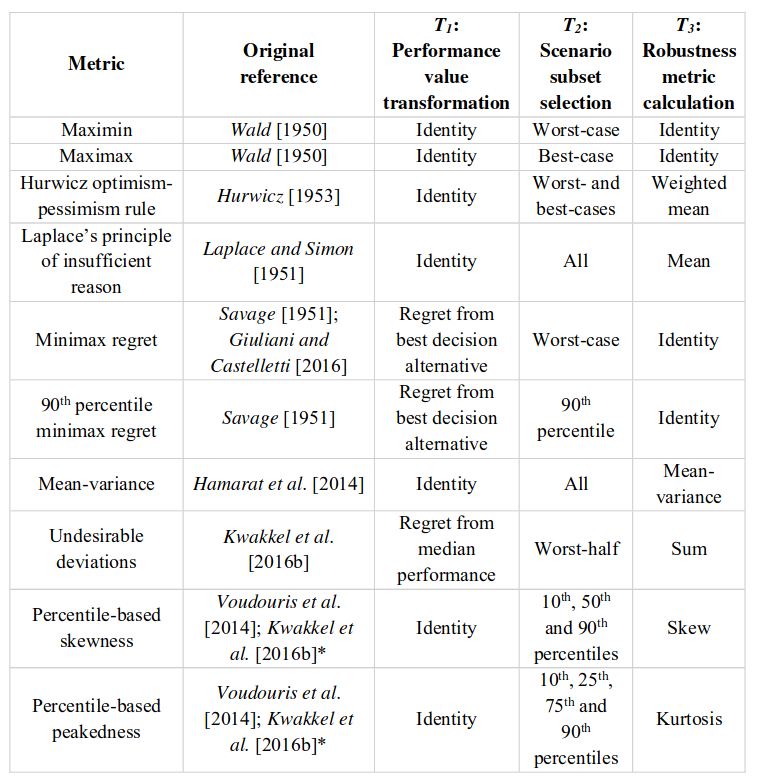
具体方法对应的步骤如下:
如何选择鲁棒性度量方法
- 在 T1 步中,可选择使用相对指标还是绝对指标,以及考虑客户满意度
- 在 T2 步中,可选择使用单个场景,多个场景,所有场景,以及风险偏好
- 在 T3 步中,需要考虑使用什么方法结合多场景的结果,如均值,方差,峰度等。
下表列出了不同方法 T1,T2,T3 步骤的差异以及风险偏好。
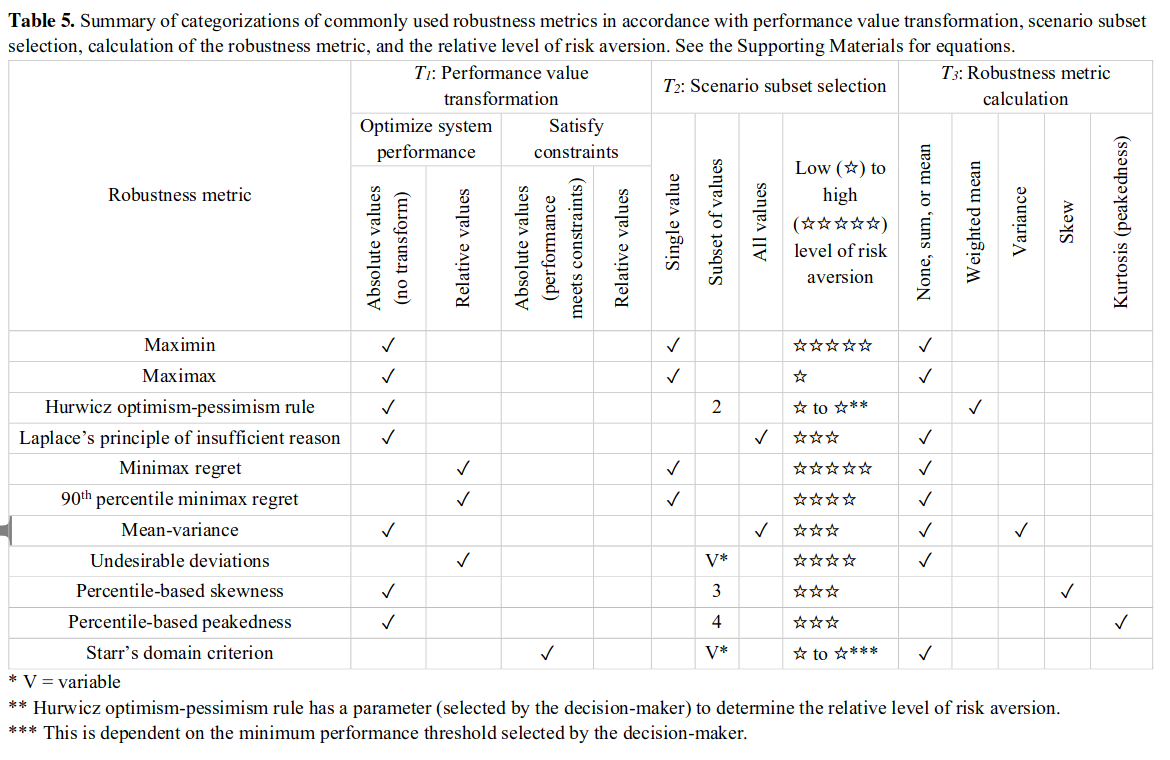
不同鲁棒性度量方法可能产生不一致结果。
扩展
对抗鲁棒性
具体应用时,如果没有多场景的数据,可以使用对抗攻击方式产生不同场景数据,然后用其评测模型鲁棒性。
工具介绍
对抗攻击工具箱
adversarial-robustness-toolbox
其 readme.md 中的 Classifies 展示了对分类器的攻击,其中包含针对不同种类模型攻击的工具。
具体使用逻辑是:先用数据训练一个模型(任意黑盒模型),然后用将模型和数据代入 API,生成具有攻击性的数据,并用其评测模型被攻击后的效果。
Zotero 地址
zotero id: KNSA7X5H