论文阅读_GLM
中文名称: GLM:使用自回归空白填充的通用语言模型预训练
英文名称: GLM:General Language Model Pretraining with Autoregressive Blank Infilling
论文地址: https://aclanthology.org/2022.acl-long.26
出处: Proceedings of the 60th Annual Meeting of the Association for Computational
Linguistics (Volume 1:Long Papers)
时间: 2022-01-01
读后感
通过在结构上的调整,结合了 GPT 和 BERT 类模型的优点,且模型规模和复杂度没有提升。将 NLU 任务转换成生成任务训练模型,使上下游任务训练方式保持一致。
摘要
没有一个预训练框架对自然语言理解 (NLU)、无条件生成和条件生成这三个主要类别的所有任务表现都好。文中提出了通用语言模型:General Language Model (GLM),它基于自回归空白填充来解决这一挑战。
在 NLU 任务上的性能优于 BERT 和 T5。可以通过改变空白的数量(屏蔽几块)和长度(每块有几个 token)来针对不同类型的任务对 GLM 进行预训练。且它只有 BERT large 的 1.25 倍参数量。
介绍
GLM 基于自回归的空白填充。从输入文本中随机删除连续的 token(自编码),并训练模型以顺序重建删除的 token(自回归)。使用了二维的位置编码,相对于 T5 模型有更少的参数,差不多的效果。
在处理 NLU 任务时,将其转换成完形填空问题;通过改变缺失跨度的数量和长度,自回归空白填充目标可以为有条件和无条件生成预训练语言模型。
方法
预测训练目标
自回归的目标填充
输入 x 由多个 token 组成,采样一些 span(绿色和黄色的块)用 s 表示,每个 span 包含一个或多个 token,用 Mask 遮蔽每个 span,模型以自回归的方式预测损坏文本中缺失的 token,预测时可以使用其它 span 以及当前 span 中,当前位置之前的 token。
用 z 表示每个 span 中的具体位置,假设一共 m 个 token,将目标定义为:
\[ \max _{\theta} \mathbb{E}_{\boldsymbol{z} \sim Z_{m}}\left[\sum_{i=1}^{m} \log p_{\theta}\left(\boldsymbol{s}_{z_{i}} \mid \boldsymbol{x}_{\text {corrupt }}, \boldsymbol{s}_{\boldsymbol{z}_{<i}}\right)\right] \]
也就是说,使用被损坏的文本 x,以及之前预测的 Sz<i 来预测 Szi 处的 token。

如图 2(a)(b),输入的 x 分为两部分,Part A 是遮蔽后的文本,Part B 只包含遮蔽的文本,Part A 中的数据不能使用 Part B 中的内容;Part B 可以使用 Part A 中的内容和当前位置之前的内容。另外,在遮蔽文本的前后加 START 和 END 标记。从而使模型从 Part A 中学习双向上下文,以 Part B 中学习单向上下文。具体训练时保证至少 15% 的原始标记被屏蔽。
图 (c) 中展示了两维的位置编码分别标记了 token 在整体中的位置和在 span 中的位置,且由 S 标记开头,生成的结果以 E 结束。
图 (d) 中把 Part A 与 Part B 连在一起,其中蓝色表示 Part A 中可用的数据只包含被遮蔽后的 x 串,黄色和绿色分别表示了 Part B 中两个 span 在不同时点可使用的数据范围。
多任务预训练
由于需要用一个模型同时支持 NLU 和文本生成,所以是多任务的训练,有以下两个目标:
- 文档级别:为了有效地生成长文本,长度是从原始长度的 50%–100% 的均匀分布中采样的。
- 句子级别:为了预测 seq2seq 任务中完整句子和段落,限制屏蔽的跨度是完整的句子,屏蔽的 token 为原始文本长度的 15%。
两种方式都使用上述公式,只是屏蔽的 span 数量和长度不同。
模型结构
- 重新排列了层归一化和残差连接的顺序
- 使用单个线性层进行输出标记预测
- 用 GeLU 替换 ReLU 激活函数
- 两维的位置嵌入:如图 -2(c) 所示,这样的位置编码在预测 Part B 时不会泄漏需要预测的长度,以保证适用于文本生成的下游任务。
精调模型
为了保证预训练和精调任务的一致性,将 NLU
中的分类任务改成了生成中的空白填充任务,具体类似完型填空,把答案当成文本中的一个
token
进行屏蔽,形如:{SENTENCE}. It’s really [MASK],候选标签 y
∈ Y 也映射到完形填空的答案,称为 v(y)。
\[ p(y \mid \boldsymbol{x})=\frac{p(v(y) \mid c(\boldsymbol{x}))}{\sum_{y^{\prime} \in \mathcal{Y}} p\left(v\left(y^{\prime}\right) \mid c(\boldsymbol{x})\right)} \]
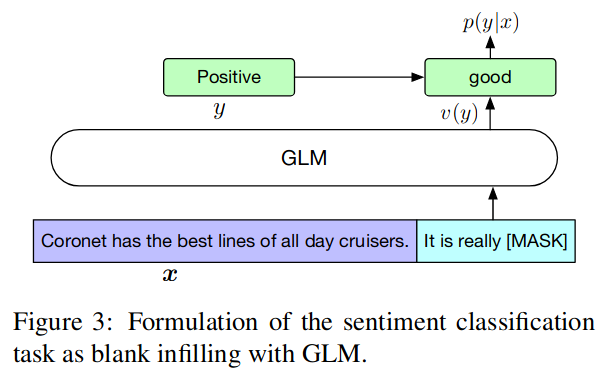
相对于 GLM,BERT 和 XLNet 的问题在于它不能预测未知长度的序列。
实验
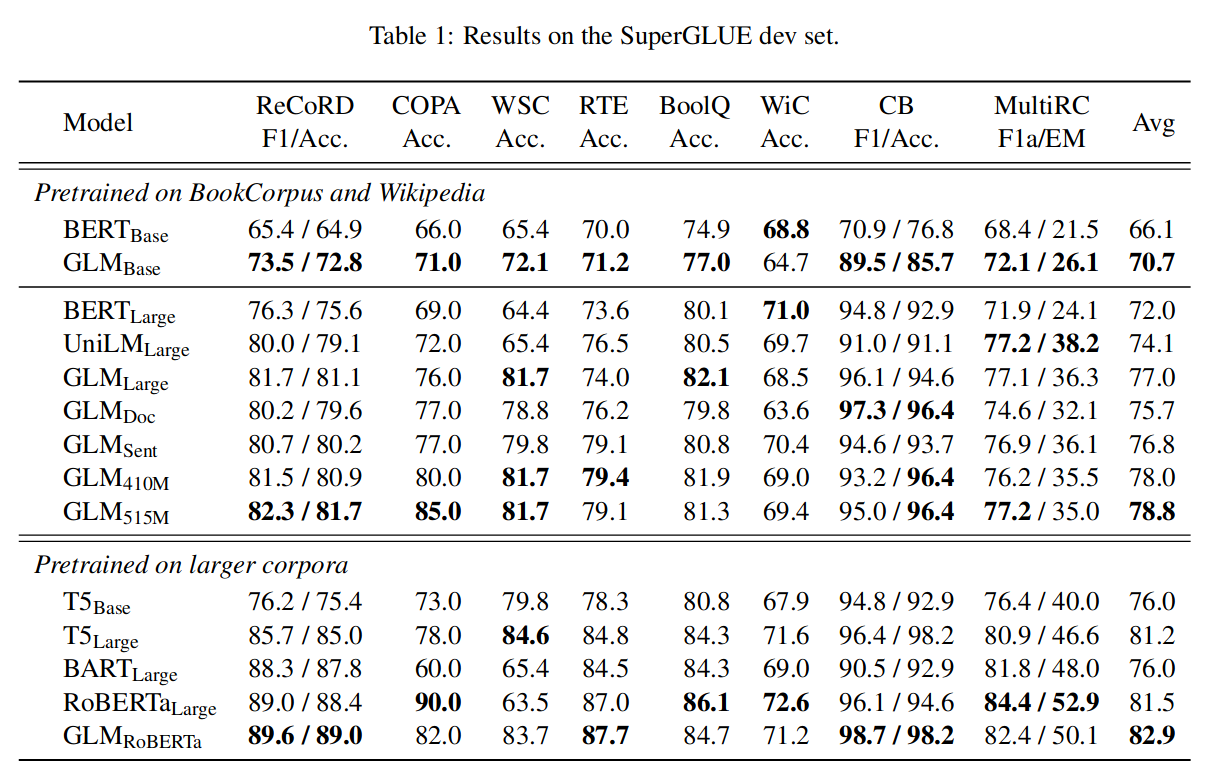
为与 BERT 进行公平比较,使用 BooksCorpus 和英语维基百科作为预训练数据。并使用 BERT 的 30k 词汇量。与 BERTBase 和 BERTLarge 相同的架构训练 GLM_Base 和 GLM_Large,分别包含 110M 和 340M 参数;并训练 GLM_RoBERTa 对标 RoBERT。
用 GLM_Doc 表示文档层次的训练,GLM_Sent 表示句子层次的训练。GLM_410M 和 GLM_515M 分别代表大模型的参数数量。T5 的参数量分别是 T5_Base(220M 参数)和 T5_Large(770M 参数)的结果。
主实验结果如下: