论文阅读_BERT-wwm
1 介绍
英文题目:Pre-Training with Whole Word Masking for Chinese BERT
中文题目:中文 BERT 的全词掩码预训练
论文地址:https://arxiv.org/pdf/1906.08101.pdf
领域:自然语言处理
发表时间:2019
作者:Yiming Cui,社会计算和信息检索研究中心,哈工大,讯飞
出处:第二届“讯飞杯”中文机器阅读理解评测,CMRC 2018
被引量:255
代码和数据:https://github.com/ymcui/Chinese-BERT-wwm
阅读时间:2022.05.10
2 读后感
中文和英文不同,一般通过词而非字来表意,而分词也有难度,BERT 以字单位建模,这样损失了词义。文中将之前用于英文的全词 MASK 方法应用于中文,文中没什么公式,原理也简单,但对中文确实是一个重要的方法,该模型也被广泛使用。
3 介绍
BERT(2019) 利用 Transformer,未标注的数据,综合上下文信息,使模型达到很好效果,之后,BERT 的作者又提出升级版 WWM,它利用全词 MASK 进一步提升 BERT 效果,本文将 WWM 方法应用于中文。用中文词作 MASK 以替代字为单位。如图 -1 所示,它同时遮蔽了来源于一个词的所有字:

文中模型利用简体和繁体语料训练,在多种任务及不同规模模型实验中表现出很好效果。
文章贡献如下:
- 提出了中文全词遮蔽的预训练模型
- 实验证明了模型的先进性
- 提出了一些使用该模型的技巧
4 方法
使用与之前方法相同的数据和参数训练模型。
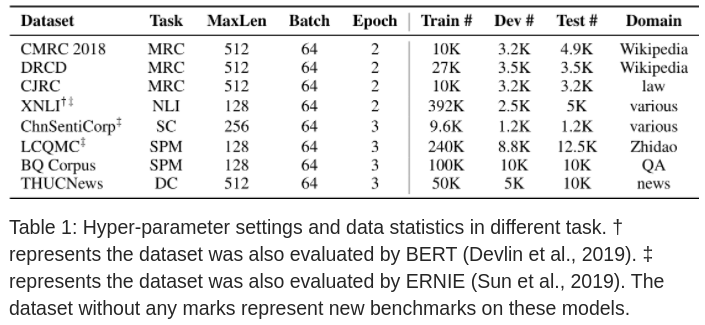
下载最新的Wikipedia,清洗(去掉 HTML 标记)后,约 13.6M 行,在分词方面,使用LPT(哈工大分词模型)实现中文分词(Chinese Word Segmentation:CWS),在训练时长度分别设为 128 和 512,以支持长文。
模型基于中文的 BERT 模型训练,使用 TensorFlow 框架,在 Google Cloud TPU v3 with 128G HBM 上训练(模型参数见论文 2.3 节)。
对于下游任务也没做改动,只把基本模型换成了文中模型。下游任务包括:阅读理解(MRC),自然语言推理(NLI),句子分类(SC),句子对匹配(SPM),文档分类(DC)。
5 实验
实验数据集如下:
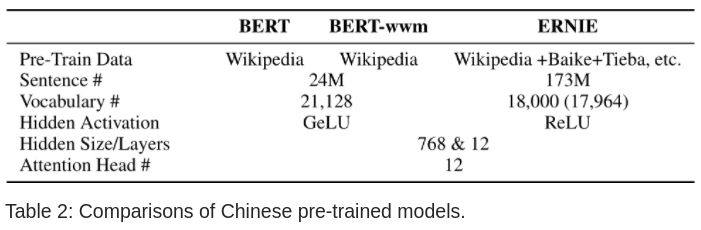
将文中模型与 BERT,ERNIE 对比:
实验效果表太多,简单贴一个看看:
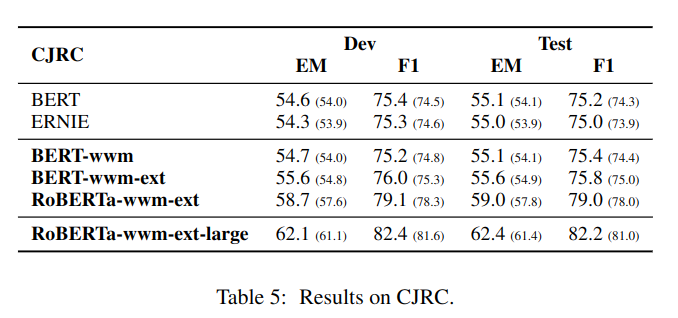
BERT-wwm-ext 相对 BERT-wwm 主要有两点改进:
增加预训练数据集,达到 5.4B;
训练步数增大,第一阶段 1M 步,第二阶段 400K 步。
6 技巧
- 初始化学习率是最重要的超参数。
- BERT 和 BERT-WWM 共享几乎相同的最佳初始学习率,但与 ERNIE 不同。
- BERT 和 BERT-wwm 使用维基百科训练,它对正式文本效果更好;而 ERNIE 使用更大规模数据训练,它对较随意的文本效果也好。
- 在长文本任务中(如阅读理解,文档分类)建议使用 BERT 或 BERT-wwm。
- 如果任务与预训练数据差异大,建议使用其它预训练模型。
- 如果希望在性能上有进一步的提升,建议训练自己的模型,如果无法训练,则可选择使用下游任务精调。
- 对于繁体中文,建立使用 BERT 或 BERT-wwm(ERNIE 在训练时去掉了繁体数据)。