基金交易量预测比赛_3_反思
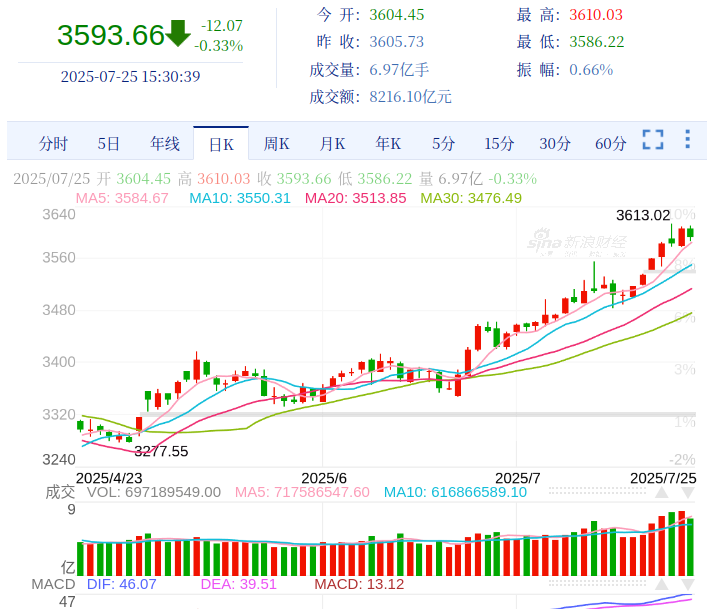
1 模型针对不同时段预测效果不同
比赛时发现自六月初到七月底的时间段,越往后越难以预测。
查看相应时间段的上证指数可以发现:榜单的最佳成绩出现在六月中上旬,此时的趋势较为平稳,成交量也不大。随后,股市出现放量上涨的趋势,对比 6 月 20 日和 7 月 24 日,成交量已翻倍。尤其是 7 月 21 日至 7 月 25 日这一周,几乎是日榜成绩最差的。从沪深 300 的成交量来看,只有 24 年 10 月至 24 年 12 月期间有类似的交易量,但这段时间是急跌后的慢涨,与 7 月底的情况不同。总之,模型无法预测它未见过的数据。
一个奇怪的现象是,当我加入 7 月 23 日以后的数据进行训练时,模型整体出现偏离,导致使用之前的数据(如 6 月)进行验证时效果显著下滑。查看 apply_amt 和 redeem_amt,在这两天发现了大量的赎回操作,但基金净值和大盘都涨得很好,无论偏债还是偏股都是如此(量价背离)。之前出现如此剧烈波动的时间段是在 24 年 10 月前后和 25 年 3 月前后。非常相似。
2 使用编程工具和大模型
我参加比赛的多数代码是由模型生成的。以前我必须掌握如何使用 shap,才能利用它进行特征分析;现在只要有 shap 这个工具就可以。现在知道有这种方法可能比实际编写代码更有用。但是自动编写的程序有时候并不完全准确,最后就可能把人带抗里了。使用大模型进行分析和获取数据也是如此,可以很快得到结果,但结果不一定正确。
还有一个隐性问题是,由于过于依赖编辑工具,再加上操作过于简单,导致我们使整个逻辑变得过于复杂,最后很难定位问题,而且可能出现一些逻辑冲突。
3 关于比赛
这种比赛,要取得一个靠前的排名并不难。虽然看起来有 1000 多人报名,但实际提交结果并且获得正常分数的并不多。
这是一类典型的问题(大模型抽取特征、利用词嵌入、机器学习和时序预测建模),需要从海量数据中提取对建模关重要的特征。
我们也需要思考:提出的问题是否在当前资源条件下可解。比如,预测明天的涨跌相比预测五年后某天的涨跌要容易得多,而且更具实现性。这个赛题还不算太复杂,但如果想预测股票涨跌,如何定义问题,选择时间长度单位,允许纳入的股票范围,允许使用多长时间的历史数据,是否允许组合,某些股票是否更容易被预测,所有这些都是难于选择的。
数据稍有变化,训练出来的模型差异巨大,很难保持稳定。这可能与基金数据比较少,时间区段也较短有关。多数情况下,模型都没有见过类似的数据。
比赛过程中发现有一个预测的上限,尽管大家的预测方法不同,但上限基本是一致的。可能说明在现实中,现在的一些不确定性是无法通过任何方法预测出来的。
无论用什么方法获取数据,我的目标都是预测未来。但是未来是很难被预测的。尤其是在金融交易中,还包含博弈:预测他人的预测、人的情绪非线性变化、从众心理等等。
4 收获
- 尽量不使用绝对值,而使用相对值,从本就有限的数据中提取更多的共性。
- 尽量使用近期的数据,有 1 天的就不用 7 天的;相对而言,短期更容易预测。
- 需要增加一些累积特征(如果最近涨幅很大,很猛,可能导致获利赎回)。
- 通过评测函数查看误差大的实例,分析错误的原因,这种方法也可能帮助挖掘更多特征。
- 处理生成的数据时肉眼查看,并画图审视,比如我每一天提交的数据中,每支基金预测的交易量都是一样的,这肯定不对。
- 模型输出的 feature_importance 和 shap 值低并不意味着特征不重要,尤其是文本特征(它们只对少数实例有效,但能提升模型准确率)。
- 短期遇到的最大问题是无法预测突发事件,而长期预测的难题是能否成功预测未来一段时间的趋势。
- 场内操作和场外操作的风格不同。
- 赎回和申购的变化规律不同。
- 赎回和申购涉及的季节因素不同。
- 投资者对利好和利空信息的反应存在不对称性。
- 情绪能够预测趋势的延续,但无法预测趋势的反转。 ## 5 总结
用算法的语言实现个人对数据的理解(基金涨跌与大盘的关系,趋势的方向和强度,累计涨跌,不同基金的不同交易量,极值出现的概率和情境,净值和交易量的关系,长短期影响,周末假期影响,同一类型基金的类似表现),然后验证每一个假设。在这个过程中,我发现自己很多看似合理的假设实际上并没有什么用处。
数据、网上信息、大模型认知、个人常识相互印证和修正。比如,当我看到了多个趋势图之后,再继续分析时,我开始猜测是偏股还是偏债,以及可能涉及什么行业。
数值数据和从文本中提取的信息有一些重叠。Embedding 和关键词也有一些重复。