论文阅读_Citrus_在医学语言模型中利用专家认知路径以支持高级医疗决策
1 | 英文名称:Citrus: Leveraging Expert Cognitive Pathways in a Medical Language Model for Advanced Medical Decision Support |
1 摘要
- 目标:介绍 Citrus,一个医学语言模型,旨在模拟医疗专家的认知过程,以改善医学推理任务。
- 方法:通过新颖的方法训练模型,使用模拟专家疾病推理数据,捕获临床医生的决策路径,同时发布自定义医学诊断对话数据集以支持研究。
- 结论:在 MedQA 等权威基准评估中,Citrus 表现优于其他同类模型,展现出增强医学决策支持系统的潜力,使临床决策更加准确和高效。
2 读后感
京东出品,目标是提升线上医药服务。效果与当前顶尖模型相当,训练时生成了部分数据,并开源了 SFT 阶段的数据。
3 方法
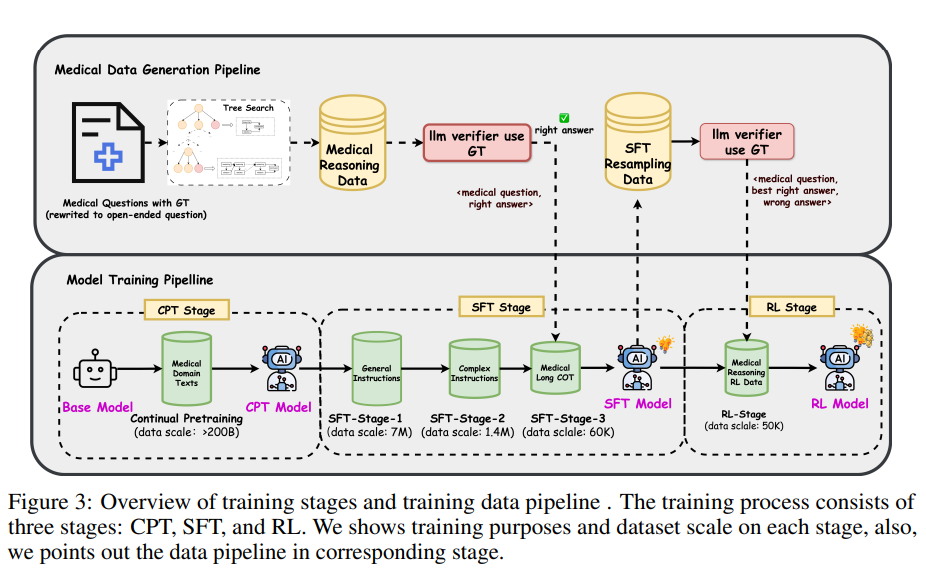
训练过程包括三个主要阶段:持续预训练(Continuous Pre-Training,CPT)、监督微调(Supervised Fine-Tuning,SFT)和强化学习(Reinforcement Learning,RL)。以下是这三个阶段的主要内容提炼:
3.1 持续预训练(CPT)
- 目的:增强模型对医学领域知识的理解,使其能够进行模式识别。
- 数据来源:
- 网络数据(Web Data)。
- 医学教材(Medical Textbooks)。
- 医学指南和文献(Medical guidelines and literature)。
- 数据处理:
- 使用自然语言处理技术(如实体识别、关系提取和文本分类)进行数据清洗和标注。
- 对 PDF 文档使用计算机视觉解决方案进行处理。
- 对医学教材数据应用数据增强技术,以扩充训练数据。
- 训练方法:
- 使用 AutoML 方法动态调整不同数据源的比例,将数据比例问题视为多臂老虎机问题,以训练损失作为奖励信号,动态选择数据源,提高训练效率。
3.2 监督微调(SFT)
- 目的:进一步提升模型的医学推理能力,使其能够进行复杂推理。
- 数据来源:
- 第一阶段(Stage-1):约 700 万条基础指令数据,用于提升模型的简单指令跟随能力。
- 第二阶段(Stage-2):约 140 万条更复杂、高质量的指令数据,用于提升模型的多轮对话处理和复杂指令跟随能力。
- 第三阶段(Stage-3):约 6 万条医学推理数据,通过“双专家推理方法”合成,用于提升模型的长链推理(Long Chain-of-Thought,COT)能力。
- 训练方法:
- 第一阶段和第二阶段主要提升模型的通用推理能力。
- 第三阶段使用合成的医学推理数据,训练模型在医学领域进行长链推理。数据格式为
<sft-input, sft-target>,其中sft-input是开放性问题,sft-target包含推理过程(<think>)和最终结论(<answer>)。
3.3 强化学习(RL)
- 目的:进一步提升模型的推理能力和输出质量。
- 数据来源:
- 使用经过 SFT 训练后的模型进行拒绝采样(Rejection Sampling),生成约 5 万对偏好数据。
- 训练方法:
- 使用 SimPO(Simple Preference Optimization)和 CPO(Conservative Policy Optimization)方法进行离线强化学习。
- SimPO 通过模型生成的平均对数概率作为隐式奖励,避免了对参考模型的依赖,并通过长度归一化防止模型偏向生成过长但质量低的回答。
- CPO 通过引入 NLL 损失提高训练稳定性。
- 数据格式为
<RL-input, chosen, rejected>,其中RL-input与sft-input格式相同,chosen和rejected分别对应模型生成的优质回答和劣质回答。
4 模型效果
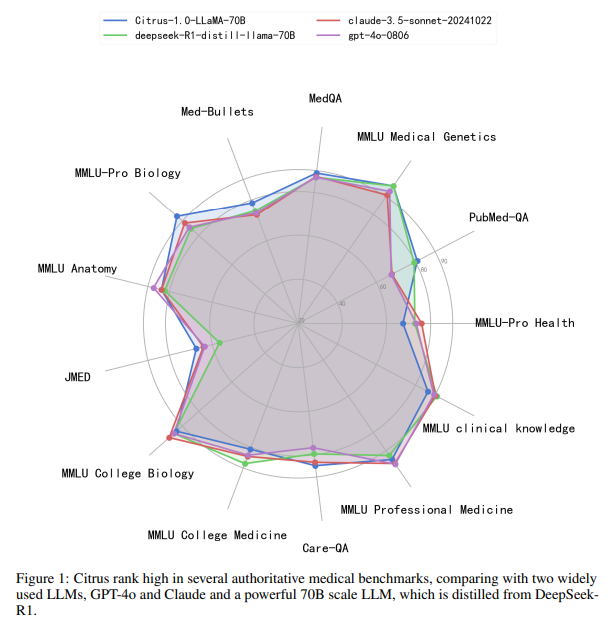
4.1 与其它模型相比
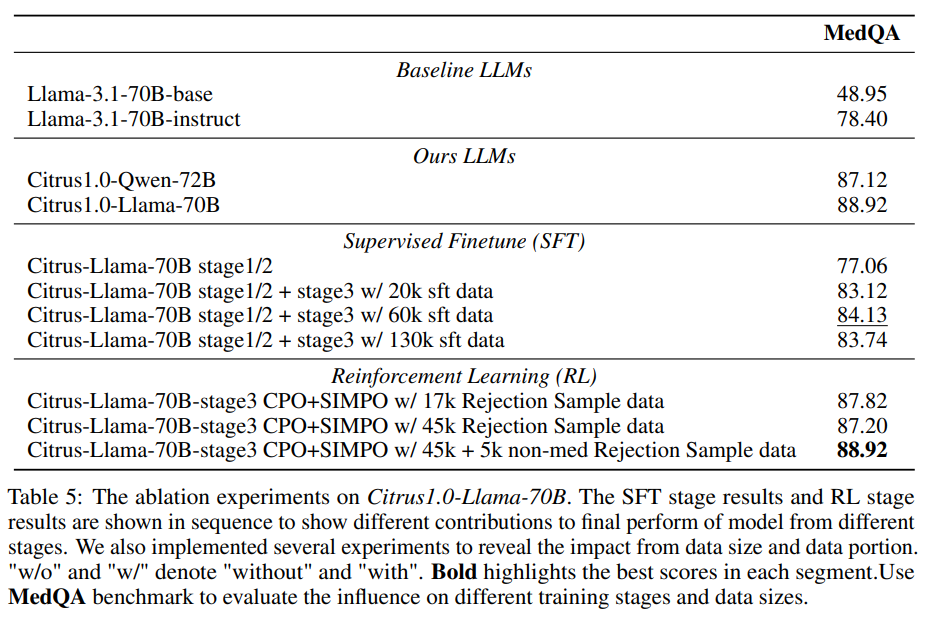
4.2 训练前后比较
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.