论文阅读_基本于文本嵌入的信息提取
1 | 英文名:Embedding-based Retrieval with LLM for Effective Agriculture Information Extracting from Unstructured Data |
1 读后感
本文讨论了在将文本文件结构化过程中遇到的一类问题:如何规范化具有一定规律但又不完全符合定式的文档。这篇文章偏重应用,包含了大量具体的实验和设计过程,而不是纸上谈兵。文章内容巧妙结合了一些知识,同时保持了通用性。
作者对相对通用的技术进行了限制优化,并应用于一个小的领域。此前需要复杂设计和编码才能完成的任务,现在全部由 LLM 实现。具体方法包括编写一些行业相关的提示词和后处理步骤,然后调用 LLM 将结构化文本转换为结构化文件。在这一过程中,嵌入技术起到了存储数据和通过含义提取特征(而非关键字硬匹配)的作用。
其中比较有趣的一点是:对于一些难以设定的阈值,作者设计了与用户进行几轮交互以确定阈值。尽管这种方法看起来不高级,但确实实用。
2 摘要
目标: 解决农民难以准确识别害虫的问题。探索使用领域无关的通用预训练大型语言模型(LLM)从农业文档中提取结构化数据,以实现无人或最小干预。
方法: 提出了 FINDER 系统,方法包括使用基于嵌入的检索进行文本检索和过滤,然后使用 LLM 问答自动从文档中提取实体和属性,并将它们转换为结构化数据。
结果: 与现有方法相比,该方法在基准测试中实现了更好的准确性,并保持了效率。
3 引言
信息提取(IE)是从非结构化文本中提取信息并将其转换为结构化数据的过程。文档在原始形式下无法轻松分析或查询,因此需要进行信息提取才能在应用程序中使用。传统的 IE 通常需要针对特定领域进行训练,并依赖手工规则进行提取。
4 FINDER
IE 任务被分解成一个四阶段、多轮的问答过程,穿插 EBR 来提取相关文本。这样可以避免 token 限制,降低成本。
- 第一阶段:系统搜索用于描述文本中实体的单词。
- 第二阶段:系统标识所有已描述的实体。
- 第三阶段:系统提取描述性词所表示的属性。
- 第四阶段:系统在文本中搜索描述这些属性的词,并将它们绑定到实体,形成结构化数据。
最终,系统输出包含所有实体及其属性和描述的 JSON 文件集合。
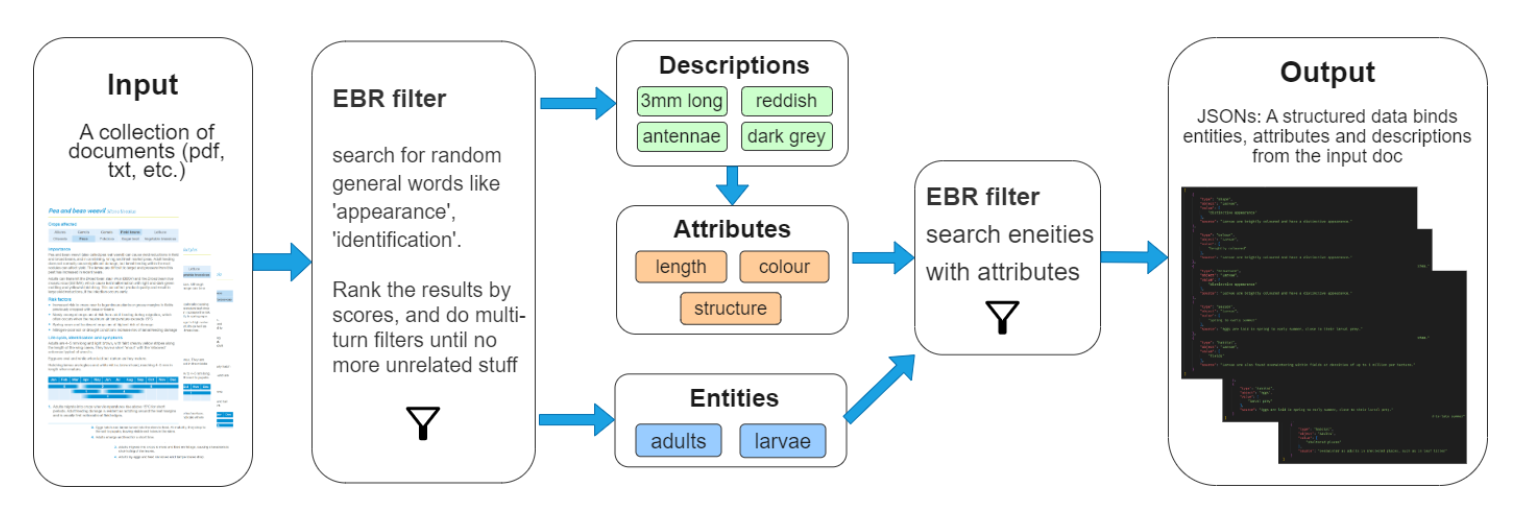
4.1 EBR 过滤器
输入的文档被分成小块,矢量化并存储在矢量数据库中。基于嵌入的检索(EBR)允许相似的文档在向量空间中更接近;可以通过计算文档和搜索内容之间的距离来确定相似性,从而完成检索任务。
使用一些通用词查询数据库,例如:“外观、标识”。此查询应执行 k 最近邻搜索,并返回多个最可能的结果及其与查询词的距离。然而,这些结果可能包含不相关的内容,因为没有标准距离来过滤它们。
按距离从最小到最大进行排名,并应用类似于二进制搜索的过程(折半查找)。该列表根据距离的中位数分为两组:包含较短距离的集合称为集合 A,另一组称为集合 B。提取位于中间位置的结果,与用户交互。如果中位数位置的结果满足条件,则在集合 B 中重复此过程;如果不满足,则在集合 A 中重复此过程。
效果满意度取决于用户,一般重复两三次即可找到合理的阈值。
4.2 第一阶段
将 EBR 返回的过滤文件作为数据传给 LLM,识别文本中的所有描述性单词,并以列表形式返回。
4.3 第二阶段
此阶段的目标是将从阶段 1 收集的描述性单词转换为属性。

LLM 可能会为相似的描述性词汇提供类似但不完全相同的属性。为了解决这个问题,可以汇总所有识别出的属性,并使用 LLM 进行过滤,保留意义相似的最常见属性。这种方法有助于避免冗余,同时尽量减少成本增加。
4.4 第三阶段
利用 LLM 从文本中提取主题,这对应于自然语言处理(NLP)中的命名实体识别(NER)技术。FINDER 在处理与农业和昆虫相关的信息时,只关注物理对象。即使存在许多实体,提取的唯一实体是成虫和幼虫,而其他如触角、腿、头部应被忽略。
4.5 第四阶段
EBR 过滤器再次被使用。根据上述步骤获得的结果,可以识别原始数据中描述的可能属性和实体列表。然后,将包含被调查实体的所有句子以及我们旨在识别的属性提交给 LLM。LLM 的作用是匹配实体和属性。

5 实验
系统的流水线由六部分组成,其中两部分是 EBR 滤波算法,最后一步是结果输出。第二阶段是属性提取,第三阶段是实体提取,第四阶段是最终属性 - 实体匹配,这三个阶段都使用 LLM。实验将分别评估这三个部分的性能。
LLM 使用的是 gpt-3.5-turbo,人工评估员将评估 LLM 输出的“真”或“假”。
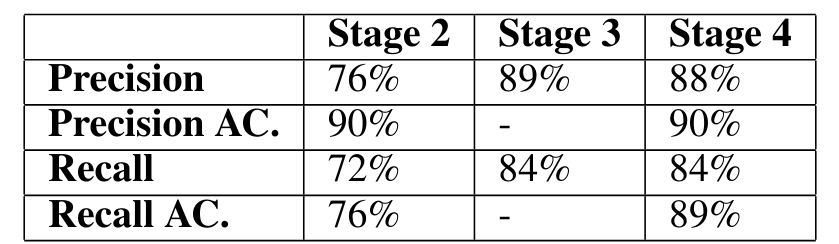
Precision AC. 和 Recall AC. 是具有可接受答案的精度/召回率。答案由人工检查,并与人工注释的答案进行比较