论文阅读_KnowPrompt知识抽取
读后感
- 针对问题:few-shot 场景下从文本中抽取关系(知识检索、对话、问答)。
- 结果:在 5 个数据集,及少量标注情况下,测试效果优于之前模型
- 核心方法:希望在 pretrain 后不再 fine-tuning,于是引入了提示 prompt,通过构建提问(提问方法/答案范围)来实现类似 tuning 的效果。
- 难点:之前对知识抽取和提示学习都不太了解;后来读了代码才了解,文中指的知识不是来自外界引入,而是将词嵌入作为知识。
- 泛读后理解程度:60%
(看完题目、摘要、结论、图表及小标题)
围绕句子的逻辑,利用之前定义好的模板提问,回答
基于知识的提示学习 KnowPrompt
1 | 英文题目:KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimizationfor Relation Extraction |
精读
摘要
最近,提示调优(Prompt-tuning) 在一些 few-shot 分类任务中取得了令人满意的结果。它的核心思想是通过插入文本,将分类任务转化为 MASK 语言模型(MASK 原理详见 BERT)。对于关系抽取问题,选择提示模板需要较多的领域知识和较大工作量,且在实体和边之间蕴藏的大量知识也不应该被忽略。文中提出了一种基于知识协同优化的调优方法 (KnowPrompt)。通过学习模板词和答案词,将实体和关系的知识注入模型,并在知识约束下协同优化它们的表示。
1. 介绍
关系抽取 (RE) 是文件抽取中的一个重要任务,抽取后的信息可供更多下游 NLP 任务使用,比如:信息检索、对话生成和问答。
之前自监督的自然语言模型(PLM)如 BERT,它可以学习到带有上下文的表征,在很多 RE 任务中表现很好,而精调 (fine-tuning) 需要在模型顶部加层并需要额外的训练。它的效果依赖于耗时费力的大量标注,且不容易泛化到其它任务中。为解决此问题,出现了 prompt-tuning:使用预训练的语言模型作为预测器实现完型填空任务。它在 few-shot 任务中表现良好。如图 -1 所示:
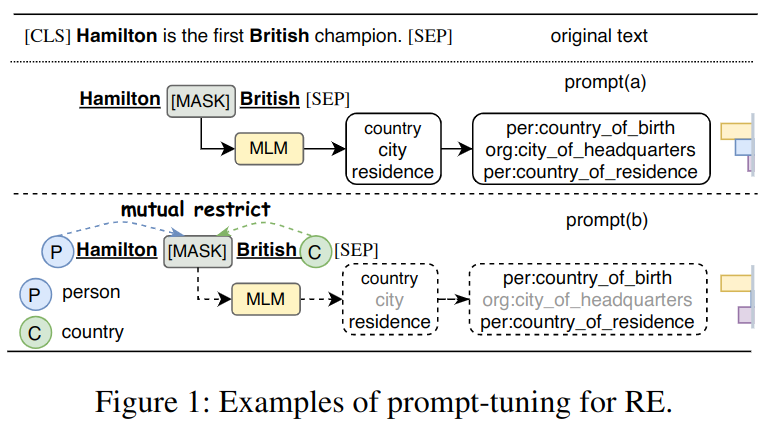
- 模型的原始输入是“Hamilton is the first British champion”
- 模型在原始输入后,加了一个模板 "Mamilton [MASK] British",同时给定了一组标签词“country,city,residenct...”作为 MASK 的可选项
(Hamilton 可能是人名,也可能是品牌)
- 模型将原始输入和模板作为条件,预测 MASK 为某选项的概率,从而抽取模板中主语 Hamilton 和宾语 British 的关系。
总之,Prompt-tuning 的目标是找到合适的模板和答案空间。而此工作常需要领域知识,以及复杂而大量的计算。而且关系标签不一定能在词典中找到合适的词。另外,实体、关系、三元组中包含的词义也不应被忽略,如图 -1 的例子中,如果主语和宾语都是人,则 "org:city_of_headquters" 就不太可能成立。相对的,关系也可以约束主语和宾语的类型。
文中提出的解决方法是:先将知识注入提示,然后用提示调优模型实现知识抽取。具体方法是使用学习“虚拟模板词”和“虚拟答案词”。具体的方法是:使用集合实体嵌入初始化的实体周围的类型标记,作为可学习的虚拟模板词来注入实体类型知识。同时使用标签计算平均嵌入作为虚拟答案来注入关系知识。在这个结构中,实体和关系相互约束,虚拟词需要与上下文保持一致性,文中引入了协同优化来校正模板和答案词。
文章主要贡献如下:
- 提出了知识提示(KnowPrompt)方法,将知识注中提示模板的设计和答案构建,以解决关系抽取问题。
- 使用知识约束,联合优化提示模板和带有答案的表示。第一次提出在连续空间内,联合优化提示模板和答案。
- 在五个 RE 基准数据集上实验表明,KnowPrompt 在标准和低资源环境下都是有效的。
2. 相关工作
2.1 知识抽取
知识抽取,早期使用基于模式的方法,基于 CNN/RNN 的方法,以及基于图的方法,后来,将预训练语言模型作为基础的知识提取成为主流,尤其是基于 BERT 的模型显示出比之前模型更好的效果。最近 Xue 等提出的基出 BERT 的多视图方法达到了目前最高水平。由于标注的限制,few-shot 任务受到关注。
2.2 提示学习
提示学习方法源于 GPT-3(2020 年),其在很多 NLP 任务中达到更好的效果。有些研究基于人工构建提示;2021 年 Hu 提出引入外部知识;2021 年 Ding 使用实体类型学习,来构建面向实体的词生成器和模板;为避免大量的人工构建提示,2020 年 Gao 等首次提出了自动构建模板和答案词,Shin 又进一步提出了梯度自动搜索,来自动生成模板和打标签。最近,有人直接利用可学习的连续嵌入作为提示模板。
在知识抽取方面,2021 年 Han 提出 PTR,使用逻辑规则构建子提示。本文中方法的先进性在于:使用知识注入方法,学习虚拟模板和模拟答案来代替人工定义规则,可以泛化到多种任务之中。另外,使用知识约束协同优化模板和答案词,使嵌入相互关联。
3. 背景知识
定义 D={X,Y},X 是实例(句子),Y 是关系标签,每个实例由词组成:x={w1,w2,ws...wo...wn},RE 的目标是预测主语 ws 与宾语 wo 之间的关系 y ∈ Y。
3.1 精调语言模型
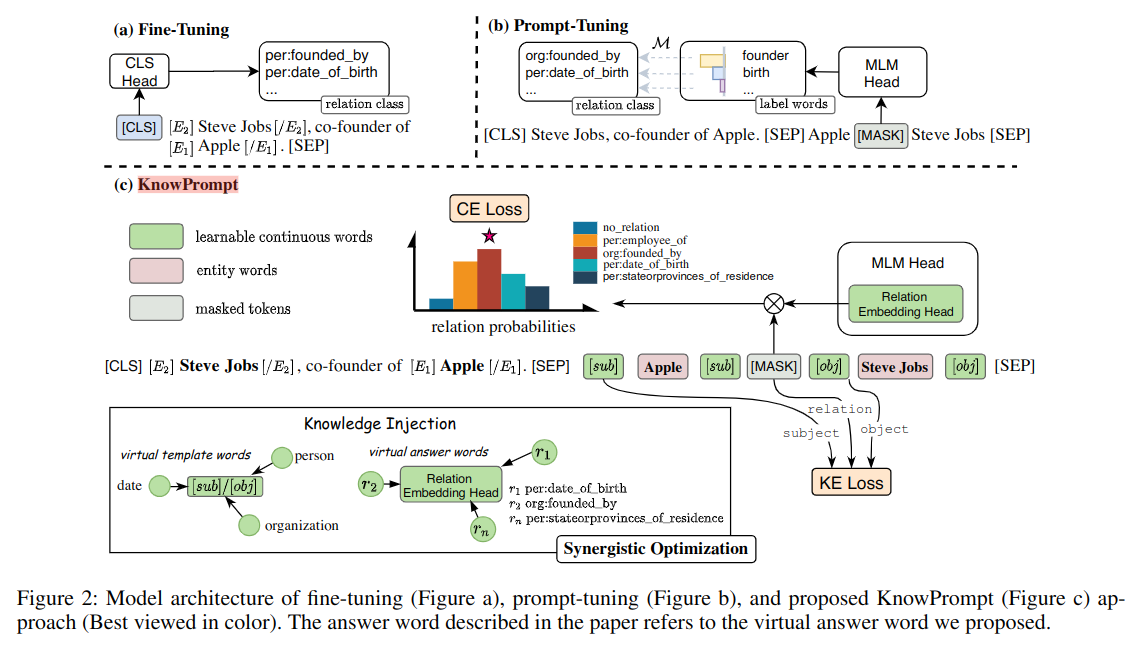
预训练的自然语言模型是 L,之前的 fine-tuning 模型将 x 作为模型的输入,加入类别[CLS] 和分隔符[SEP],见图 -2(a),其输出是隐藏层 h,最后用 h 预测该实例属于各个类别 CLS 的概率,使用交叉熵作为多分类的损失函数,在训练过程中自然语言模型参数 L 和用于最终分类的参数 W 被训练。
3.2 提示调优语言模型
提示调优的目标是在预测模型和下游任务间建立桥梁,主要挑战是如何建立问题模板 T(.) 和可选答案标签 V,将它们统称为提示 P。对于每个实例 x,模型构建它新的输入:xprompt=T(x)。它一般包含原始文本和附加文本;V 使用自然语言模型 L 词表中词作为标签,定义 M:Y->V 作为注入映射表,连接任务标签 Y(最终抽取的关系)和标签词 V(用于回答提示问题)。
在保留了原有文本 x 的基础上,遮蔽 (MASK) 了 xprompt 中的一个或几个词,并用标签词替换,用模型 L 预测遮蔽位置的词,p 用于描述 V 在 MASK 处的分布:
\[ p(y|x)=p([MASK]=M(y)|x_{prompt}) \]
如图 -2(b) 所示,在原始文本后又加了一段带有 MASK 的文本,此时,可以通过模型 L 计算 MASK 对应的向量,并计算概率分布 p,用于描述 V 中各个可选项对于 MASK 位置的匹配程度,M 映射对于两个可选项分别有:M(y = “per:data_of_birth”) → “birth”(当 y 分类 per:data_of_birth,V 是 birth),M(y = “org:founded_by”) →“founder”(当 y 为 org:founded_by,V 为 founder),然后判定哪个选项更合适。
4. 方法
此部分主要介绍 KnowPrompt 协同优化方法的实现,将实体类型和关系标签中的知识用于关系提取。4.1 阐述构建方法,4.2 阐述优化方法。
4.1 利用知识注入构建提示
典型的提示包括两部分:构建模板和答案集。本文目标是利用知识注入构建虚拟模板词和模拟答案词,以实现知识抽取任务。
实体知识注入
2021 年 Zhou 提出了实体类型标注,他在实体前后加入了特征的标记[E] 和[/E],详见图 -2(a),这一技术在关系抽取中得到广泛使用。它用实体的类别信息提升模型效果,但是需要对类型进行额外的标注。然而,我们可以利用关系对实体的限制得到主语和宾语的大概范围,比如:当关系是““per:country_of_birth”时,主语是人,宾语是国家。此时可以得到主语和宾语候选集合 Csub={"person","organization",...}和 Cobj={"organization","data",...},及其中元素的分布φsub 和φobj。
如图 -2 所示,用可学习的连续数据来描述实体类别,具体来说,是利用加权平均实体类型作为嵌入来初始化虚拟模板词:
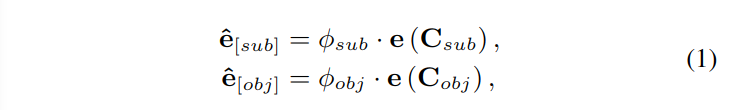
式中的 e^sub 和 e^obj 也是嵌入,用于描述主语和宾语的类型(它不是一种具体的类型,而是一种综合类型,因此是虚拟的),它被插入到主语和宾语的前后(图 -2 中绿色框),而 e() 从语言模型的词嵌入层提取词嵌入。使用上述方法可以从知识中自动学习更丰富的实体类型,其效果与之前方法差不多,但不需要额外标注。
简言之,这里的模板,就是后加的那半句话,需要分别确定其 主语 和 谓语 的类型,而通过 谓语 可以大概估计出主语和宾语是什么类型。
关系知识注入
之前提示调优的研究主要是构建标签词和任务标签的一对一映射表,它不能表达关系标签中丰富的语义知识。我们设置虚拟答案词 v′∈V′,它能表达关系的语义,在模型 L 之后再加一层,用于学习关系嵌入,用虚拟答案集 V' 完全表示关系标签 Y。用 p(y|x) 来表示 V' 在 MASK 位置的分布。
和实体类型嵌入类似,使用 Crel 来表示可能的关系集合,φrel 表示其中各项的概率分布。通过对关系类型的分解,在关系语义词的候选集 Crel 上设置了概率分布φRel。具体方法是,计算关系中每个 token 的加权平均作为初始化嵌入,以此注入语义信息。比如:y1 =per: countries_of_residence,集合 Crel1 = {“person”,“countries”, “residence” },具体方法如下:。
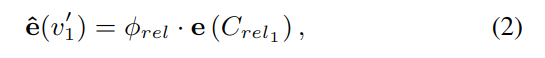
4.2 使用知识约束实现协同优化
实体类型和关系标签之间存在着丰富的交互和联系,且这些虚拟模板词和答案词应该与周围的上下文相关联。因此进一步协同优化虚拟模板词和虚拟答案词的参数集:
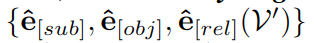
根据上下文校准提示
尽管模拟模型和答案都基于语义信息初始化,但是它们可能不是最优的,且与上下文相关。因此,可用上下文进一步优化其表征。通过计算真实关系 y 和 p(y|x) 之间的交叉熵的损失函数来优化虚拟模板词和答案词,如下所示:
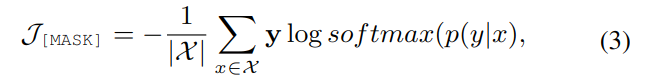
此处的|X|是训练集中的实例个数,可学习的连续表征可以通过模板和答案的协同优化,自适应地学习最优表征。
简言之,就是通过预测的关系和真实的关系计算损失优化模型。
隐含的结构约束
为注入结构信息,我们采用了知识嵌入 (KE) 目标函数作为约束。使用三元组 (s,r,o) 描述关系,s,o 描述主和宾的类别,r 是预定义的答案 V‘的关系标签。我们直接用虚拟模板和虚拟答案输出的嵌入通过语言模型参与计算。损失函数定义如下:
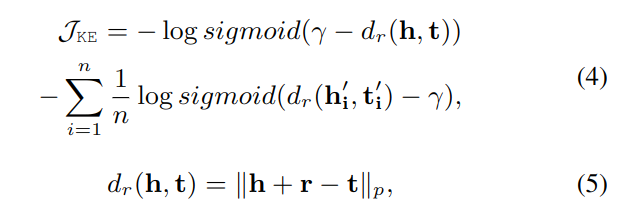
带 ' 的是负例;γ是边界;dr 用于衡量头实体尾实体及关系(算法同 TransE),三元组成立时其值趋于 0,不成立时其值较大;n 表示所有负采样。负采样时,使用正确的答案填充 MASK 位置,随机取主语和宾语,替换为不相关的类型以构造损坏的三元组。(这里更多细节请见代码)
y=-log(sigmoid(x)) 如下图所示:
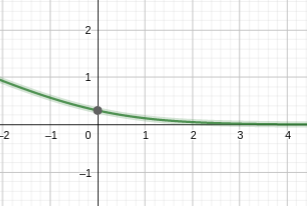
括号里的值越大,最终损失函数越小;对于正例,d 相对边界值γ越小越好,对于负例,d 相对γ越大越好。
4.3 训练细节
训练分为两个阶段,第一阶段使用大学习率协同优化虚拟模板词和模拟答案词:
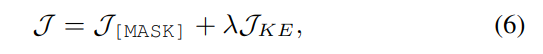
其中 λ是用于权衡两个损失函数的超参数。
第二阶段基于被优化的虚拟模板词和模拟答案词,仅利用 J[MASK] 损失函数为语言模型调参,用较小的学习率优化所有参数。
5. 实验
5.1 数据集
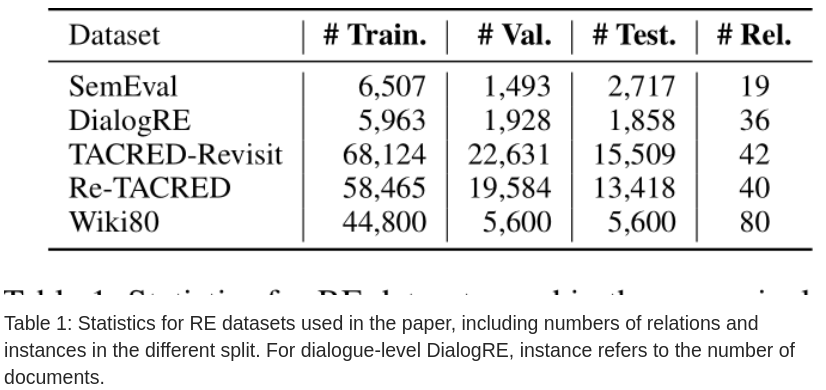
为全面测试,使用了表 -1 中列出的 5 个数据集
5.2 实验设置
使用 BERT_LARGE 作为基础模型。
基本配置
使用全部训练数据训练,与之前的四个模型对比。
低资源配置
使用 LM-BFF 提出的 8-, 16-, 32- (n 为每种类别的样例个数) 方法采样,从初始训练和验证集中抽取每个类的 k 个实例,以形成 few-shot 的训练和验证集。
5.3 实验结果
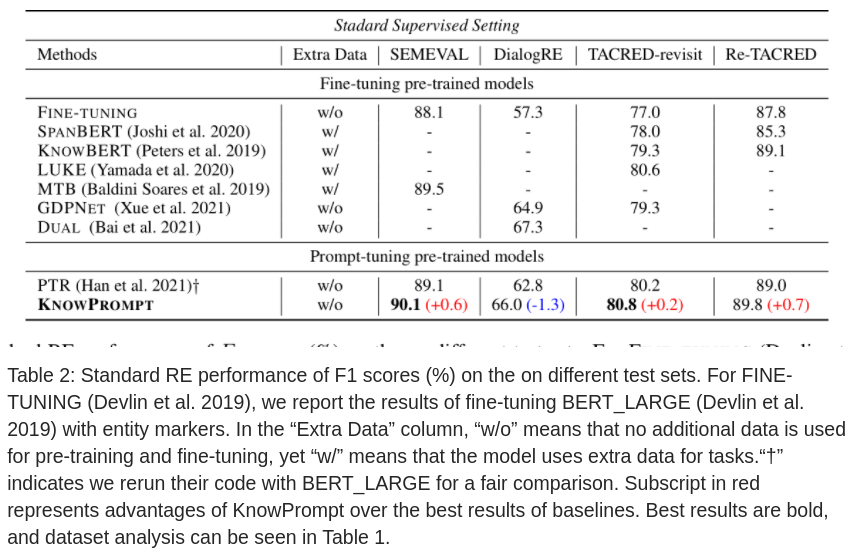
基本配置
低资源配置
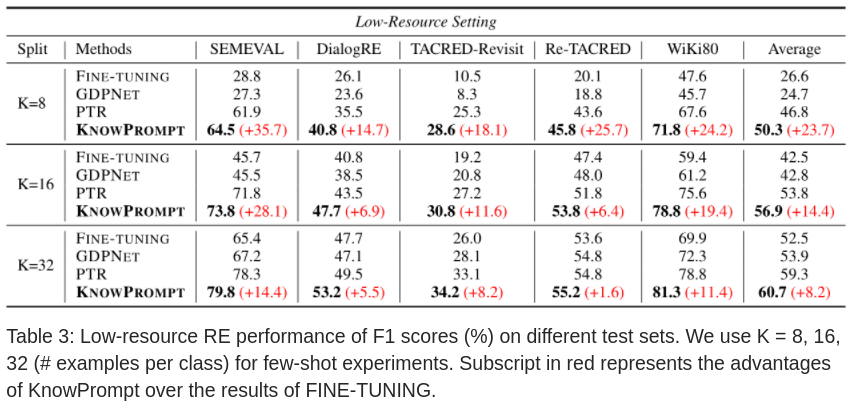
可以看到,样例越少,KnowPrompt 相对其它模型效果越好。
5.4 消融研究
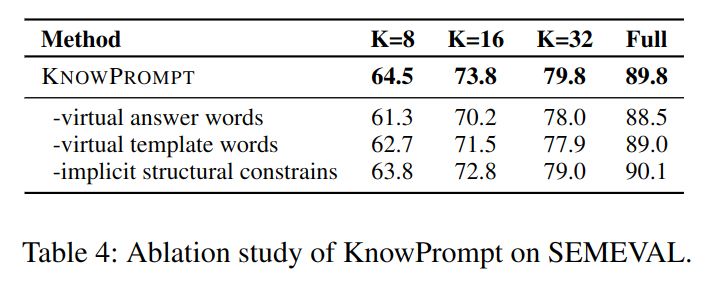
代码解析
数据
dataset/*
- 代码中包含五个数据集的数据,分为两种格式,dialogue 为对话数据;其它数据格式均为同一种
- 数据集包含几千到几万条训练数据不等,除 dialogure 外的其它数据模式为:每条数据包含一个原始字符串,和一个头实体、尾实体、关系的三元组,用于训练和评测模型。
- 每个数据目标下都包含 rel2id.json 文件,它定义了可被抽取的关系及其对应 id,可以看到,“答案”(或称标签) 是有限的。
代码
- data/* 用于解析数据
- dataset/* 供训练和测试的数据
- scripts/* 训练各种模型使用的示例脚本
- models/* 各种底层的预训练模型
- lit_models/* 核心函数
- lit_models/transformer.py 文中模型的具体实现
- _init_label_word(), 140 行,初始化各种权重
- training_step(),185 行,主要流程
- ke_loss(),262 行
- lit_models/transformer.py 文中模型的具体实现