论文阅读_Self_instruct
1 | name_ch: 自引导:用自我生成的指令调整语言模型 |
读后感
文中提出了自引导框架,之前引导精调主要使用人工处理的数据,数据量和范围都有限,本文通过示范少量引导示例,让模型自己生成引导数据对模型进行优化。
摘要
用引导数据精调模型提升了模型适应新任务的能力,它依赖于人工的引导数据,在数量、多样性和创造力方面受到限制,因此阻碍了精调模型的通用性。文中提出了自引导框架,通过自引导来提高预训练语言模型的指令遵循能力。经过自引导可使基础模型的 GPT-3 提升 33%,与 InstructGPT001 差不多的效果。
介绍
2022 年以后的大模型一般都使用了预训练和引导使用人工标注引导的技术。PROMPT SOURCE, SUPER NATURAL INSTRUCTIONS 是两个著名的引导数据集。
自引导过程是一个迭代自举算法。在第一阶段,模型被提示为新任务生成指令。此步骤利用现有的指令集合来创建更广泛的指令定义任务;然后,在将低质量和重复的指令添加到任务池之前,使用各种措施对其进行修剪。可以针对许多交互重复此过程,直到生成大量任务。
该模型的迭代 SELF INSTRUCT 过程产生大约 52k 条指令,与大约 82k 实例输入和目标输出配对。
文章贡献:
- 提出 SELF-INSTRUCT,一种用最少的人工标记数据诱导指令能力的方法;
- 通过广泛的指令调整实验证明了它的有效性;
- 发布了一个包含52K 指令的大型综合数据集和一组手动编写的新任务,用于构建和评估未来的指令优化模型。
方法
图 -1 中展示了其核心技术。
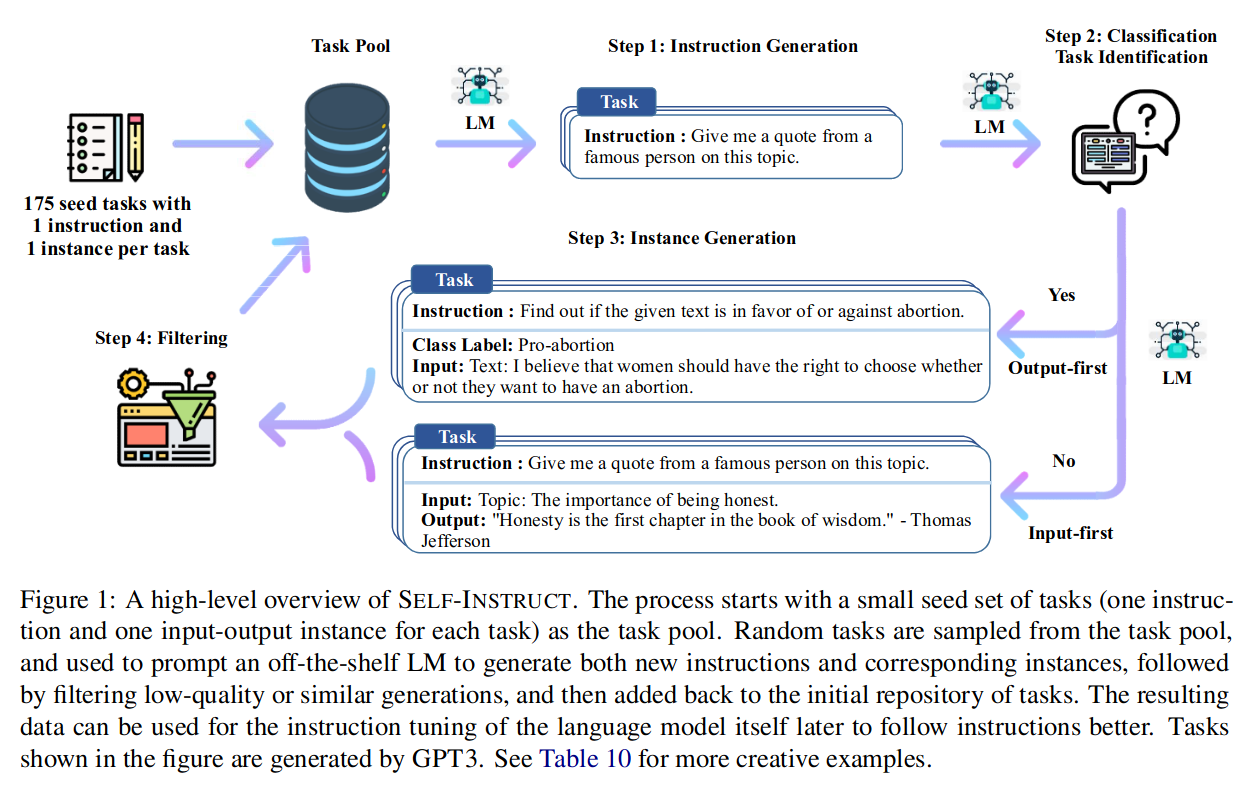
定义引导数据
首先,(图左上)定义了 175 个种子任务,目标是生成一个引导数据集{I},其中每条定义一个自然语言任务 t,每个任务都有一个或多个输入输出实例 (Xt, Yt),预计模型 M 产生输出 y。为了鼓励数据格式的多样性,允许不需要额外输入的指令(即,x 为空)。
生成自引导数据
生成自引导:
将 175 个任务(每个任务 1 个指令和 1 个实例)作为初始任务池。每一步,从池中抽取 8 个任务指令作为上下文示例。其中 6 条来自人工编写的任务,2 条来自前面步骤中模型生成的任务,以促进多样性。
判断自引导是否为分类
示例见图
按不同方式生成数据
为每条引导生成实例,针对于分类与非分类任务使用不同方法,对于分类任务一般先生成类别标签,然后生成问题;而非分类问题先生成问题,再生成答案。
过滤掉低质量数据
为了鼓励多样性,只有当一条新指令与任何现有指令的 ROUGE-L 重叠小于 0.7 时,它才会被添加到任务池中。还排除了包含一些通常无法被语言模型处理的特定关键字的指令;另外,过滤掉完全相同或输入相同但输出不同的实例。
使用生成的指令精调模型
连接指令和实例输入作为提示,训练模型产生实例输出。
来自 GPT3 的自引导数据
生成的数据包含 52K 引导,82K 实例。
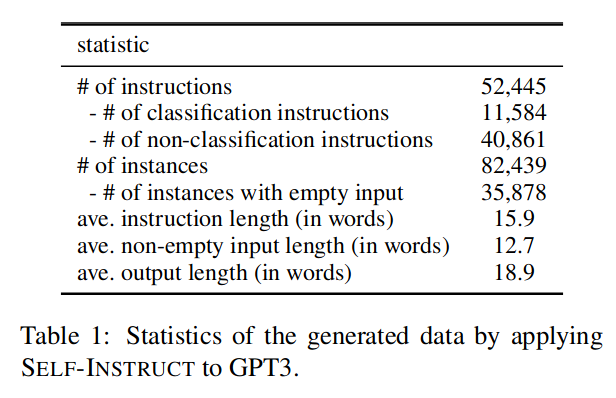
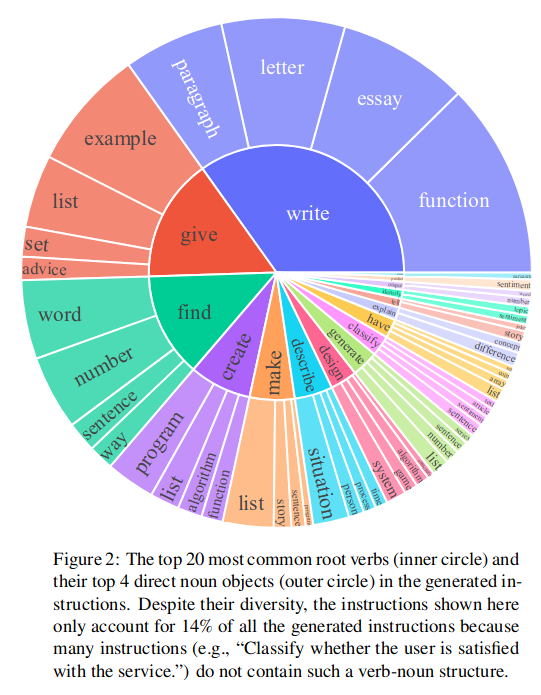
图 -2 展示了生成的最常见的动词及其直接宾语:
实验
使用 GPT-3 生成的引导,利用 GPT-3 提供的 fine-tune API 对 GPT-3 调优。
实验一:Zero-shot 任务
SUPERN1 评测包含 119 项任务,每个任务 100 个实例。
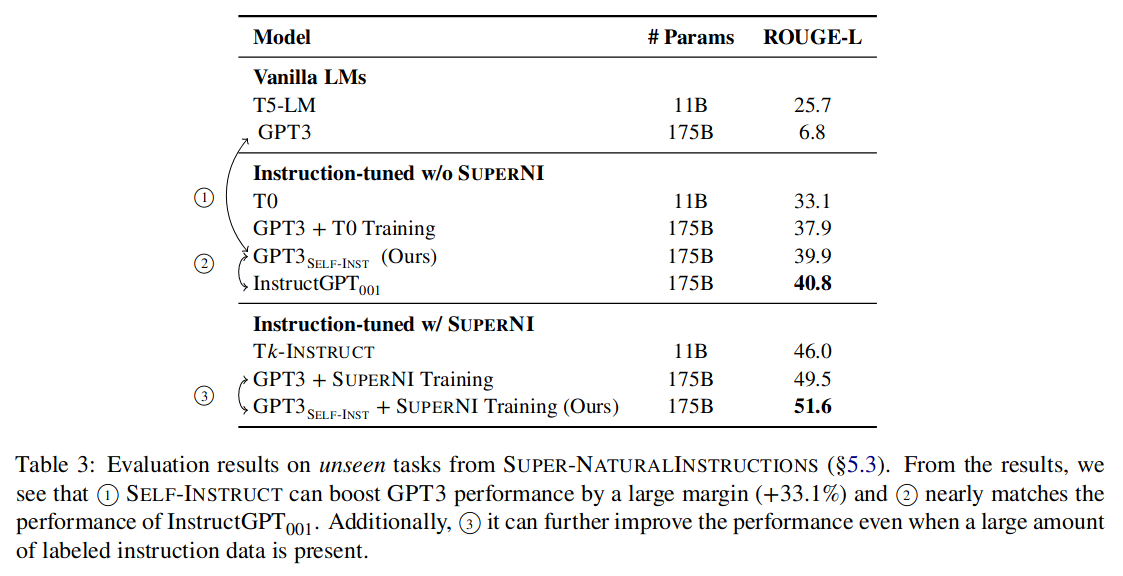
可以看到 Instruct-GPT 相对于 GPT-3 基本版有较大提升,与 InstructGPT001 效果差不多。
推广到面向用户的新任务
创建了 252 条指令,每条指令 1 个实例。用它可以作为一个测试平台,用于评估基于指令的模型如何处理多样化和不熟悉的指令。人为评估分为从 A-D 四个等级,效果如下:
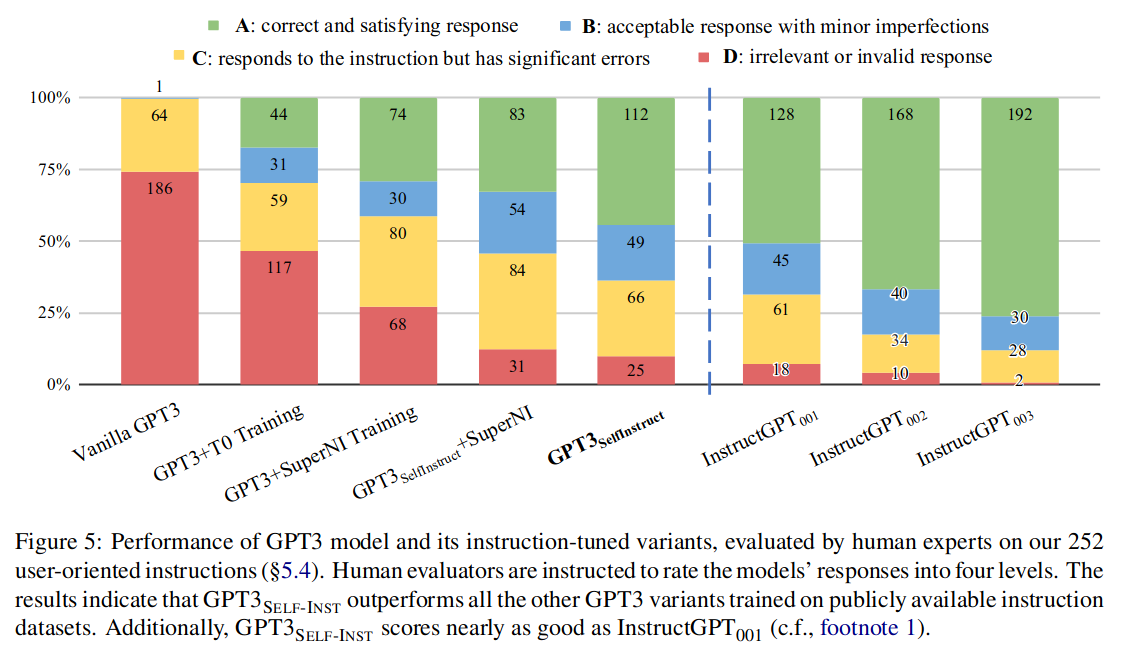
可以看到 Self-instruct 与 instructGPT001 差不多,相对于 002,003 差距较大。
instructGPT001、002、003:001 是比较早期的版本,002 深度融合了代码训练和指令微调,003 加入了 PPO 强化学习。