大型语言模型作为优化器
1 | 英文名称: LARGE LANGUAGE MODELS AS OPTIMIZERS |
摘要
- 目标:提出一种名为 OPRO 的优化方法,利用大型语言模型作为优化器,通过自然语言描述优化任务。
- 方法:在每个优化步骤中,LLM 从包含先前生成的解及其值的提示中生成新解,然后评估并将新解添加到下一个优化步骤的提示中。
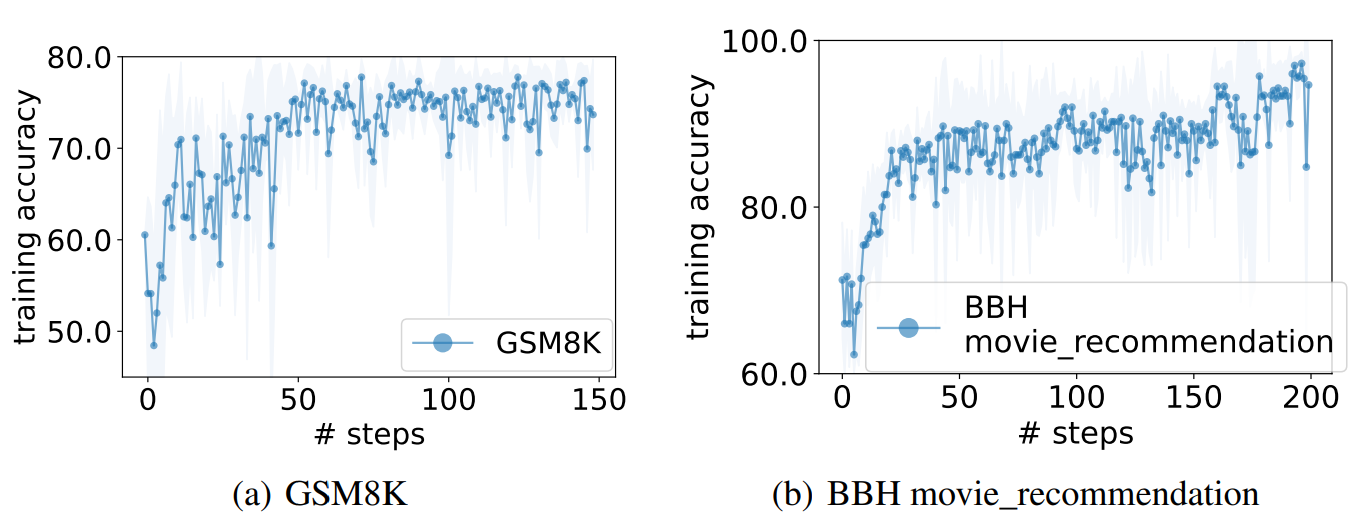
- 结论:OPRO 在线性回归和旅行推销员问题上展示了其效果,最终在任务准确性最大化方面优于人工设计的提示。在 GSM8K 上,OPRO 优化的最佳提示比人工设计的提示提高了高达 8%,在 Big-Bench Hard 任务上提高了高达 50%。
读后感
随着大模型的兴起,越来越多的从事提示工程,即如何提问以使大模型的输出效果更佳。有实证研究表明,对于 GPT-4 等高级模型而言,良好的提示可以使其几乎完美地完成任务。由此提示变得越来越精细和复杂。继而,人们开始研究如何自动优化提示和提问,这有点像对用户提问的规范化,即让机器帮助我们改进问题的提问方式。
经过迭代优化,将提示和问题设计得足够好,然后提炼出一些方法论和提示集合。当这些提示变得足够简洁和广泛使用时,就可以直接使用,更快地解决问题。
方法
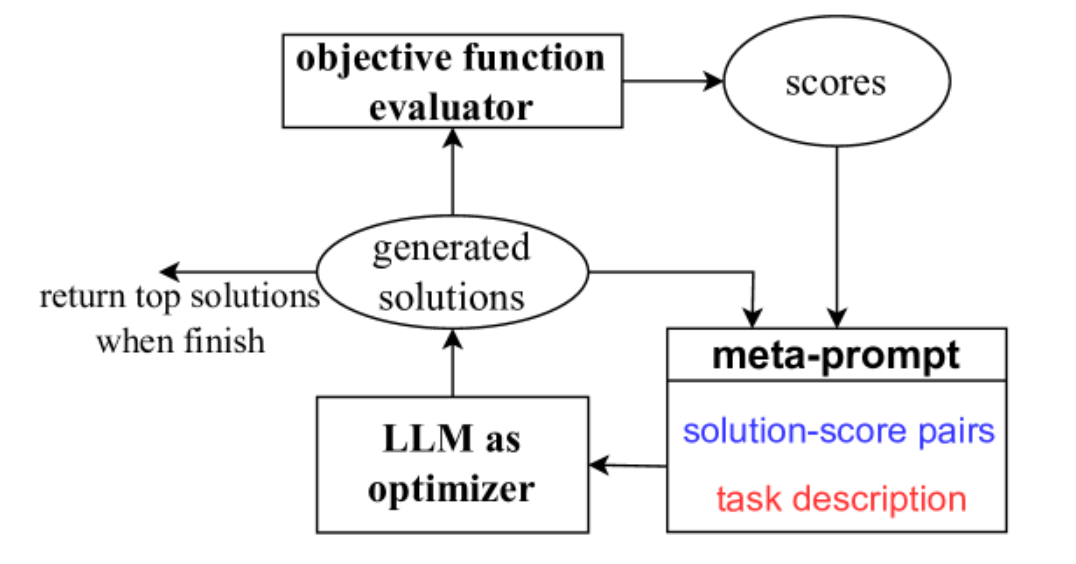
优化从初始解开始,然后迭代更新解以优化目标函数。OPRO 框架概述如图所示。给定元提示作为输入(右下红色),LLM 生成目标函数的新解,然后将新解及其分数添加到元提示中,以进行下一个优化步骤。元提示包含在整个优化过程中获得的解决方案 - 分数对,以及任务的自然语言描述和(在提示优化中)任务中的一些示例。
2.2 元提示设计
作为优化器的输入 LLM,元提示包含以下两个基本部分:问题描述和优化轨迹(右下红色蓝色)。
问题描述
优化问题描述:首先优化问题的文本描述,包括目标函数和对解的约束。例如,对于提示优化,可以指示 “LLM 生成一条精度更高的新指令”,在元提示中将此类指令表示为元指令。另外,还可以提供定制的元指令,作为生成的解决方案的非正式正则化指令,例如“指令应该简洁且普遍适用”。
优化轨迹
优化轨迹:除了理解自然语言指令外,LLMs 还被证明能够从上下文演示中识别模式。元提示利用了这个属性,并指示它 LLM 利用优化轨迹来生成新的解决方案。具体来说,优化轨迹包括过去的解决方案及其优化分数,按升序排序。在元提示中包含优化轨迹可以 LLM 识别得分高的解决方案的相似性,鼓励在 LLM 现有良好解决方案的基础上构建可能更好的解决方案,而无需明确定义解决方案的更新方式。
解决方案生成
在解决方案生成步骤中,LLM 使用元提示作为输入生成新解决方案。此阶段解决的关键优化挑战如下:
优化稳定性
在优化过程中,并非所有解决方案都能获得高分,并且比以前的解决方案单调改进。这有时会导致优化不稳定和大方差。为了提高稳定性,提示 LLM 在每个优化步骤生成多个解决方案,从而 LLM 同时探索多种可能性,并快速发现有希望的方向。
权衡探索和利用
调整 LLM 采样温度,以在 exploration-exploitation 之间取得平衡。较低的温度鼓励 LLM 利用先前发现的解决方案周围的解决方案空间并进行小的调整,而高温则允许更 LLM 积极地探索可能明显不同的解决方案。