Science重磅_让大模型像婴儿一样学习语言
1 | 英文名称: Grounded language acquisition through the eyes and ears of a single child |
1 读后感
这是一篇 2024 年 2 月发表在 Science 上的论文,是跨信息科学和认知科学的研究,来自纽约大学的数据科学中心和心理学系。作者主要研究了人在婴儿期如何学习关联视觉和语言。
看到图 -3,模型通过学习把具象扩展到抽象的时候,真的挺激动的,会有一种:在这伟大的时代,看着人们正在创造历史的感觉。这需要有多模态技术的加持,还需要一个老实孩子。
这篇文章的结构不太像医学论文也不太像科技论文,感觉每段都很有料,推荐通篇阅读,只是有点小贵。下面还是从引言 (背景),方法,评价的角度来梳理这篇文章,我的想法和评论都用括号斜体括起来,其它内容均来自论文及对论文的归纳总结。
2 摘要
目标:训练模型根据少量训练样本,像婴儿一样学习视觉(眼睛)与语言(耳朵)之间的关系。
方法:作者提出了基于儿童视角的对比学习(Child’s View for Contrastive Learning,CVCL)模型。使用一个 6 到 25 个月大的儿童的长期头戴摄像机录像,采集 61 小时的相关视觉,训练模型对视觉和语言概念系统进行对齐。
结果:展示了学习词语意义中的关键因素。
3 引言
儿童在 6-9 个月时,开始将词汇与其视觉对应物连接起来;到 18-24 个月时,他们平均可以理解 300 个词,其中大部分是名词。例如:当一个孩子在话语中听到“球”这个词时,他们如何学会将这个词与圆的、弹跳的物体关联起来,而不是与其他特征、物体或事件关联呢?
对于儿童的学习过程,哲学家和认知科学家提出了很多假设,一种理论认为,词汇学习是由简单的、通用的、联想机制驱动的,例如画面与声音共现;其他理论则提出可能有更强的约束(例如:先天倾向,或者额外的推理和认知能力)。
文中对最简单的方法(第一种理论)进行了测试,通过一个孩子的纵向头戴式视频记录(如图 -1 A 所示),研究了词 - 视觉映射的可学习性。为此,使用了儿童视角对比学习模型(CVCL)。在不加入任何先验知识和线束的情况下,追踪词语和可能的视觉参照物之间的共现情况来确定它们的映射。
4 方法
4.1 数据
在 SAYCam-S 数据集上训练 CVCL,该数据集包含了一个孩子的纵向自我中心视频记录,包括孩子生活中 6 到 25 个月的片段,总共有 60 万个视频帧与 37500 个转录话语配对(从 61 小时的视频中提取)。但它只捕捉到了孩子清醒时间的大约 1%,且不包含他们经历的其他方面。
4.2 模型
提出基于儿童视角的对比学习模型(Child’s View for Contrastive Learning,CVCL)。使用一个对比目标来协调两个神经网络,一个视觉编码器和一个语言编码器,如图 -1B 所示。
在自我监督的训练方式下(只使用孩子视角的录像,不使用外部标签),对比目标将视频帧和语言表达的嵌入(向量),共现视为正例,非共现视为负例。
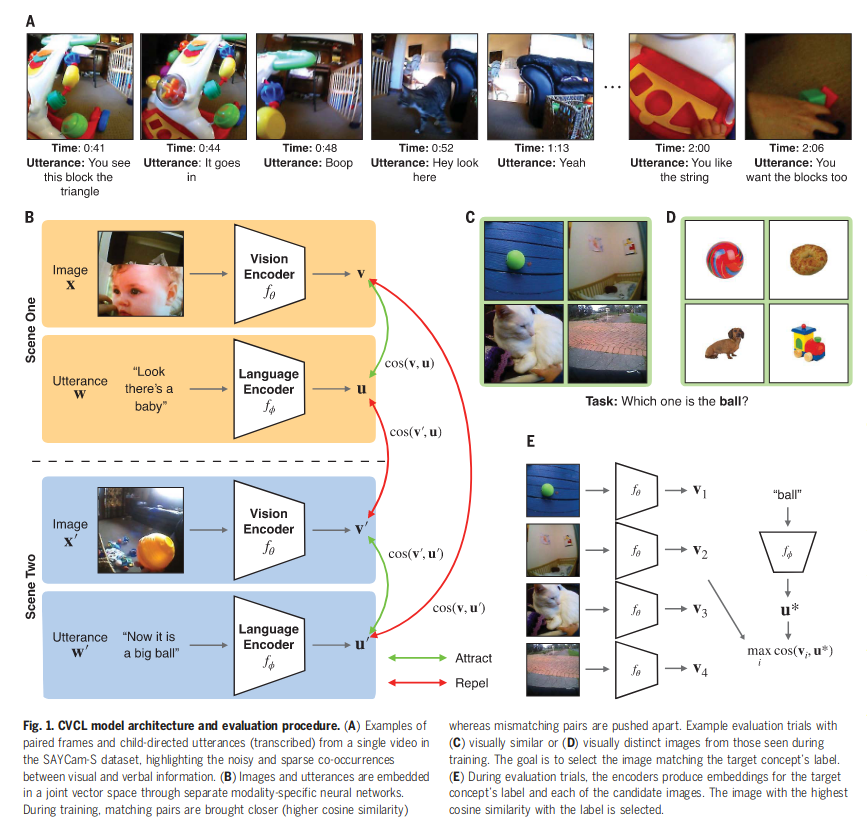
4.3 评估
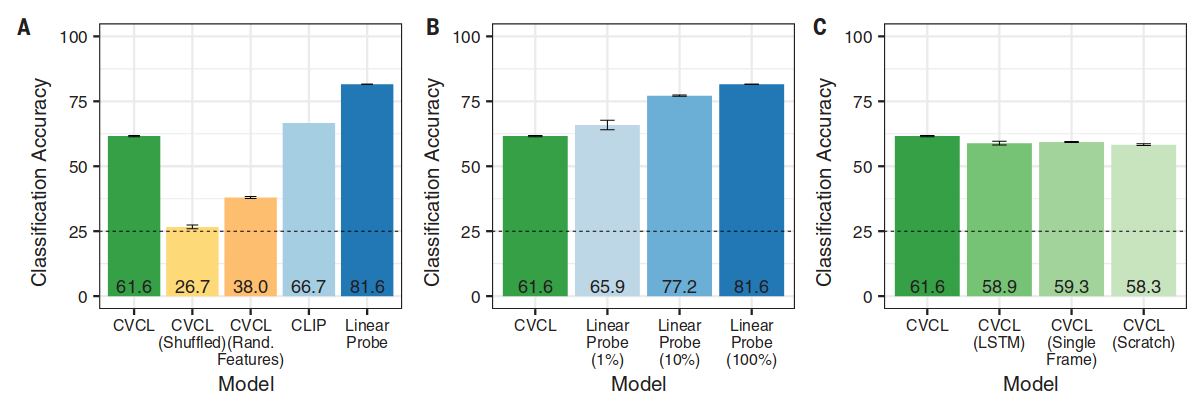
使用常见测试儿童的方法对测试进行评如,如图 1-C,D 所示,让模型从四个选项中识别类别标签。CVCL 的分类准确率是 61.6%,CVCL 在 22 个概念中 11 个的性能与 CLIP 差距在 5% 以内(CLIP 是一个图像 - 文本对齐模型,通过 4 亿个图像 - 文本对训练)。此外,利用数千个标注了类别的数据,训练了一个有监督模型:线性探测模型 Linear Probe。该模型是通过在预训练的视觉编码器(从自我监督初始化)上拟合一个线性分类器构建,最终达到了 81.6% 的准确率。
论文还对比了从数据中学习,与从标注数据中学习的效果(自学成材和有人教),通过减少标注数据展示标注的作用,如图 2-B 所示。实验显示,一个直接标注的例子至少相当于七个来自监督学习的例子(有监督学习更快,自监督可以学习任何内容)。图 2-C 示例了与其它结构模型对比的效果。
4.4 扩展到其它视频范例
测量 CVCL 在 Konkle Objects 评估数据集上的性能,评估包括 64 个视觉概念,其对应的词汇都存在于 CVCL 的词汇表中,图片包含一个在白色背景上的单个对象。使我们能够检查 CVCL 学习的词汇是否能推广到分布外的视觉刺激。如图 3A 所示:
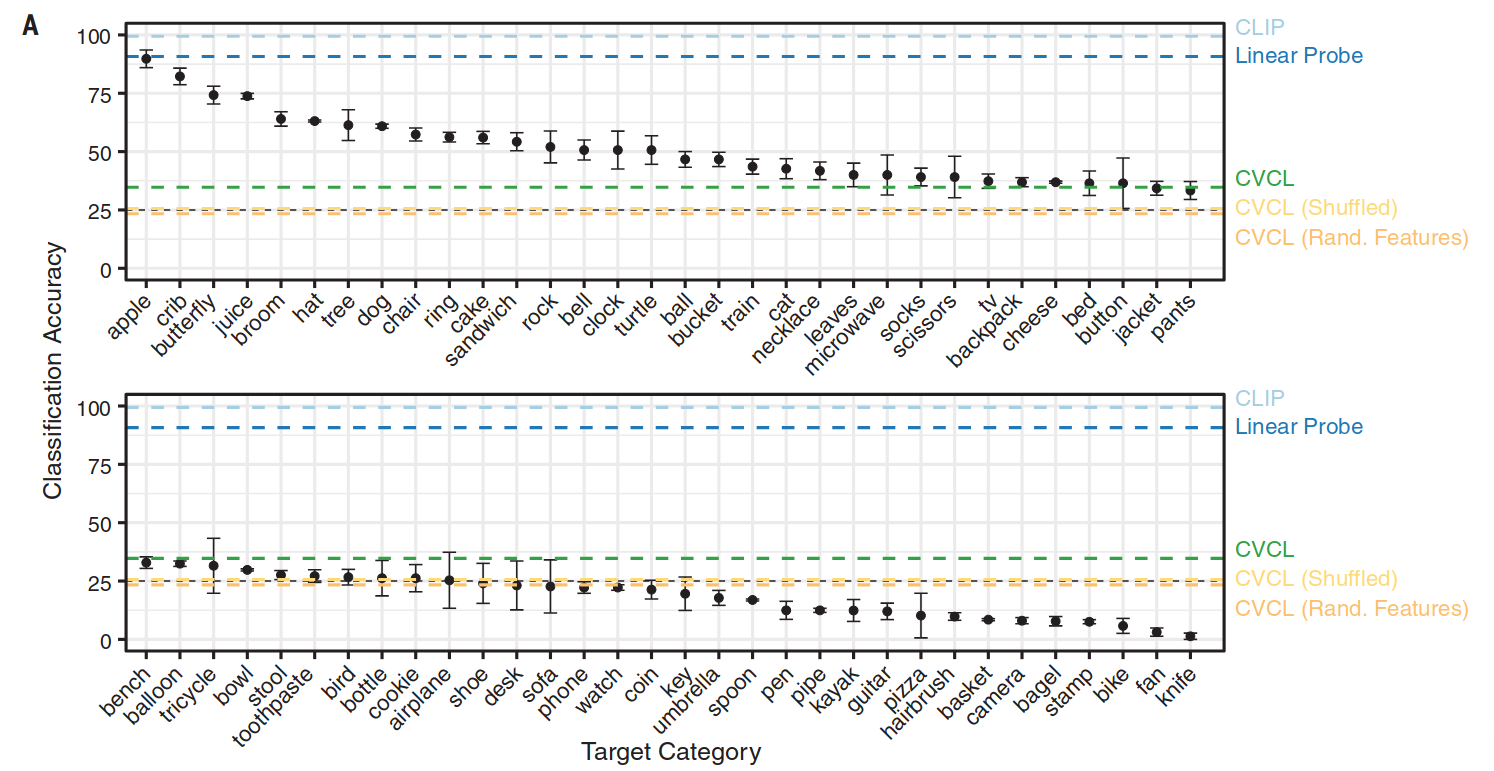
64 个概念中的 16 个得分超过 50%,另外 42 个概念的得分高于机会水平 25%,总的准确率是 34.7%,这展示了模型的泛化能力。
图 3-b 展示了真为直观的泛化效果,每一行展示了四个不同视觉概念,左侧是两个随机选取的训练样本。同时,右侧展示了四个测试样本,从左到右分别对应:最好的两个样本、中位数样本以及最差的样本。每个泛化样本下方的百分比正确率是指当该图像作为目标时的表现。

4.5 多模态表示
此部分考量了模型的表征能力。首先检测 CVCL 的视觉和语言概念系统的对齐程度,通过余弦相似度方法比较指向同一事物的视觉与语言嵌入的相似度,并使用 t 分布(t-SNE)将关系可视化。在视觉和语言之间发现了显著的概念对齐(相关系数 r=0.37,p<0.001)。
另外,不同的类别汇聚程度也有不同,如图 4-B 所示,如视觉变异性较大的“手”和“玩具”比较分散,相比之下,像“汽车”和“婴儿床”形成了更为紧密地聚类。

从图 4-C 中可以看到:其中蓝色为语言概念,绿色为视觉信息,一个词只使用一个向量表示,如拼图 puzzle,而与它对齐的图像分别指向了字母拼图和动物拼图,并且可以看到视觉上相似的物品集合表示为不同的子聚类;这些都是模型通过对比学习学到的隐式表示,而没有引入任何抽象概念。
图 -5 展示了使用 GradCAM 注意力方法,突出显示与目标类别最相关的图像区域。
