两阶段股票价格预测研究
1 | 英文名称:A Two‑Stage Framework for Stock Price Prediction: LLM‑Based Forecasting with Risk‑Aware PPO Adjustment |
摘要
- 目标:提出一个结合 LLM 与风险感知 PPO 的框架,提升股票价格预测准确性并控制风险。
- 方法:第一阶段由 LLM 生成基于历史数据与新闻情绪的预测,第二阶段由强化学习 PPO 利用 VaR/CVaR 等风险指标调整预测输出。
- 结论:该 LLM‑PPO 框架在预测准确性与风险敏感性上均优于传统模型,为市场波动环境下决策提供更加稳健的工具。
读后感
这篇文章非常实用,方法简洁而不刻意复杂。
1 方法
相较于传统机器学习模型,该方法能够捕捉更复杂的模式并提取实时文本信息,同时融入情绪因素。此外,它不仅优化收益,还特别关注金融风险,如市场波动和回撤。

简言之,就是将历史数据输入到 LLM 中,通过它来预测股价。具体的提示如下:
1 | 您是一名金融分析师,在股票市场预测方面具有专业知识。 |
- LLM 模型:采用 Groq AI 的 Deepseek-R1-Distill-Llama-70B,不进行微调,用于情绪分析和财经新闻解读。
- PPO 算法:基于 PyTorch 中 Stable-Baselines3 进行训练。
- 计算指标:通过 pandas-ta 库计算各种指标。
- 数据下载:每天从可靠来源如雅虎财经下载新闻文章,通过财经新闻提要和股票新闻 API(https://eodhd.com/financial-apis/stock-market-financial-news-api)获取数据。
- 情绪指标:使用 Python 包 NLTK 生成财经新闻的情绪极性分数,范围为 -1 到 1。
2 强化学习 PPO 实现
2.1 状态表示
(详见 3.2 节)
\[
s_t = \{ \hat{y}_t, P_t, \sigma_t, \text{VaR}_t \}
\] - ŷt: LLM 预测的价格 - Pt:
历史价格趋势 - σt: 市场波动率(volatility) -
VaRt: Value at Risk(VaR,某一置信水平下最大可能亏损)
这相当于告诉 PPO 当前市场大致状态和 LLM 的原始判断。
2.2 动作空间
\[ y_t = \hat{y}_t + a_t \]
\[ |at|≤ϵ⋅yˆt \]
PPO 不直接做预测,而是微调 LLM 的预测值。
at是它做的“加法或减法”;- 有个限制
ε,不能改得太夸张(比如 LLM 说涨 2%,PPO 最多调个 ±0.4%)。
避免大起大落,保持调整“温和、合理”。
2.3 奖励函数设计
\[
R_t = -|\hat{y}_t - y^*_t| - \lambda \cdot \text{CVaR}_\alpha
\] - |ŷt − y*t| 是预测误差,越小越好; -
CVaRα 是“条件在最坏α% 情况时的平均亏损”,越小越稳; -
λ 是调节权重,控制偏好“准确”还是“稳健”。
奖励 = “准确度” + “抗风险能力”的加权结果。
2.4 PPO 目标函数(损失)
\[ \mathcal{L}(\theta) = \mathbb{E}_t \left[ \min \left( r_t(\theta) A_t, \; \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) A_t \right) \right] \]
r(θ)
是“新策略和旧策略的概率比”;如果新策略变化太大,就会被
clip(裁剪);
3 实验
3.1 数据与实验设计
- 时间范围:2015–2024 年
- 涵盖公司:Apple、汇丰银行、百事可乐、腾讯(0700.HK)、丰田(7203.T)
- 特征包括:开盘/收盘价、成交量等;技术指标如 SMA、EMA、RSI、MACD、Bollinger Bands;基于新闻文本的情绪极性分数。
3.2 结果
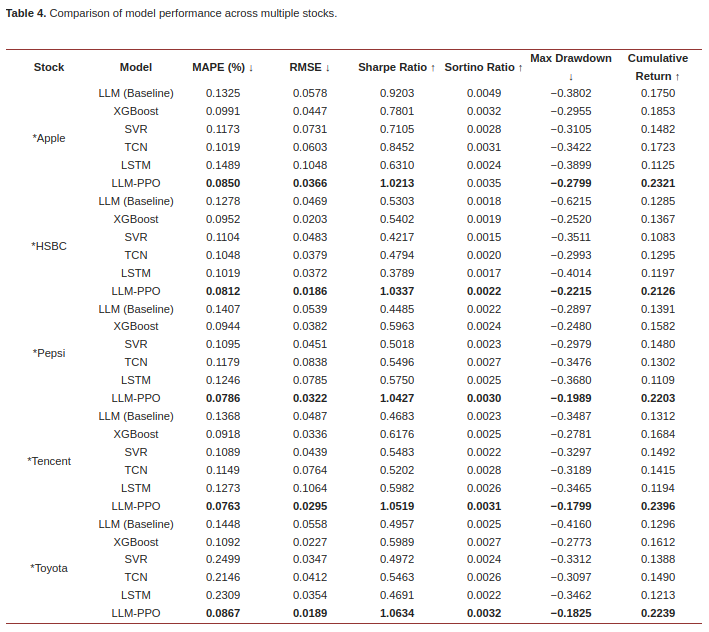
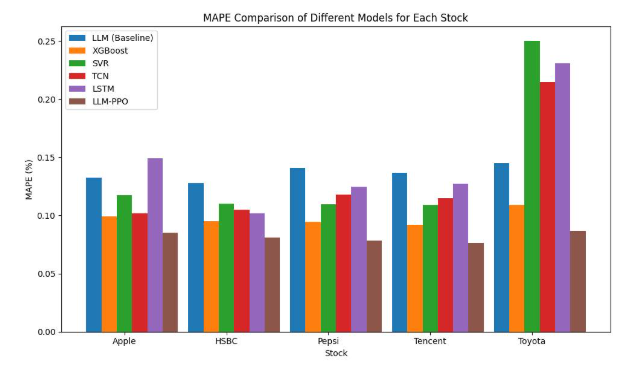
LLM-PPO 是最佳选择,而 xgboost 也是不错的选择。
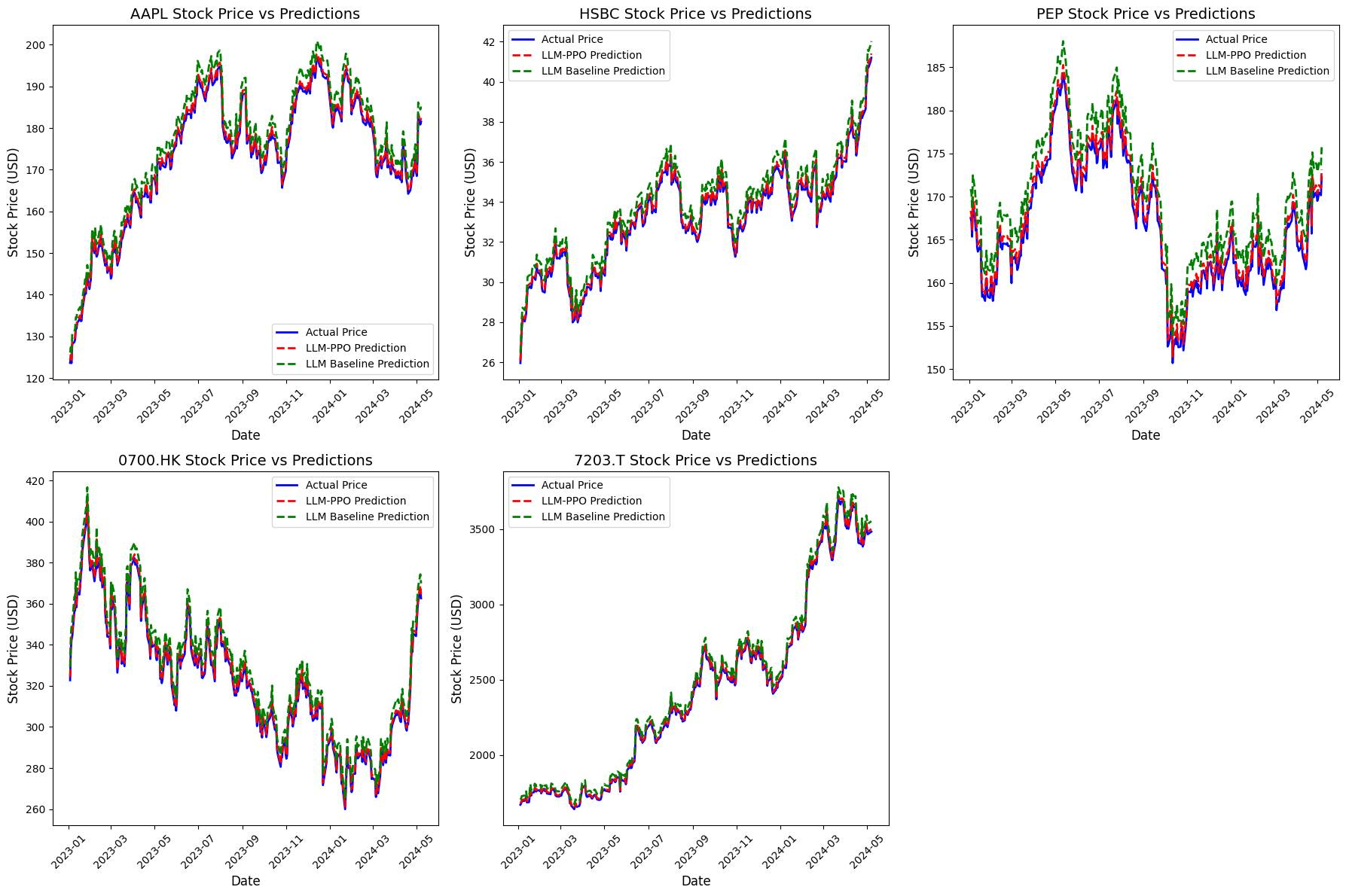
4 问题与局限
- LLM 本身可能会生成带有“幻觉”性质的解释,需要经过人工审核。
- 实验的范围较小(仅有 5 支股票的样本集),窗口为 5 日的短期预测,泛化能力有待验证。