论文阅读_一对多的手术名称规范化
介绍
英文题目:A Knowledge-driven Generative Model for Multi-implication Chinese Medical Procedure Entity Normalization
中文题目:知识驱动的多含义中文医疗实体规范化生成模型
论文地址:https://www.aclweb.org/anthology/2020.emnlp-main.116.pdf
领域:自然语言处理,实体规范化,医疗
发表时间:2020
作者:Jinghui Yan 等,北京交通大学,中国科学院,繁宇科技有限公司
出处:EMNLP
被引量:4
阅读时间:22.06.04
针对问题:中文 ICD9 手术名称的规范化
结果:支持手术名称一对多规范化
核心方法:使用生成模型;利用知识约束;用子类数据精调模型
读后感
如果单纯依赖数据和模型,极可能产生一些完全不靠谱的匹配,文本规范化优化方法,多是针对这一问题的改进,比如代入知识。论文使用生成模型解决文本规范化问题,想法比较有意思,另外,使用约束的方式把知识代入了深度学习模型。
介绍
命名实体规范化(Named entity normalization,NEN)也叫实体链接(entity linking)。医疗实体规范化,主要指将诊疗过程中医生书写的文本与知识库中的实体建立连接,主要有手术名称对应 ICD9 编码规范化,和诊断名称对应 ICD10 编码规范化。
推动研究的主因是医生书写不一致,需要统一后再进行后续处理。且现实中很多科室一半左右的手术都由多个子手术组成,所以,规范化时一个手术需要对应多个标准手术名称。本文将其称为 multi-implication 多含义,文中也着重讨论了该问题的解决方法。图 -1 展示了一对多的情况。
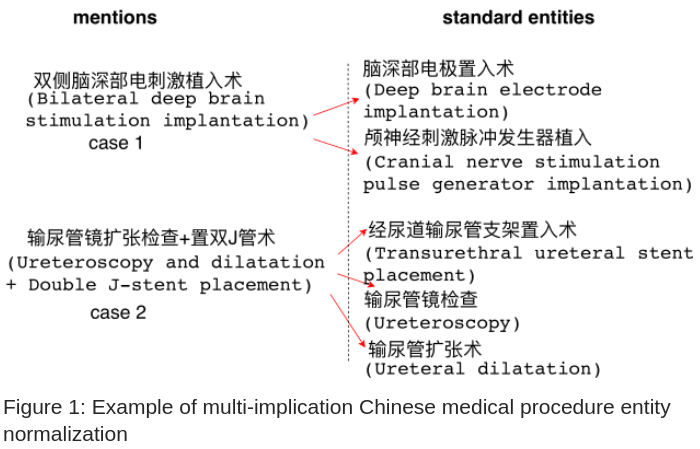
与一般文本匹配不同的是,实体规范化是将任意文本与固定的标准文本链接。
之前的研究多使用判别模型。判别模型一般包含两步:用规则或简单的文本相似度方法从标准名称中找到实体(将每个 ICD9 手术名称为作为一个实体)候选项;然后用判别模型计算原始文本(非标准文本,后简称医生输入)与标准文本的相似度,选相似度最高的作为结果,一般将其称为 Selecting and re-randing(SR) 策略,它对于一对一标准化效果很好。
文中提出使用生成模型来生成标准化实体,生成过程中使用了两种约束:
- 编码约束
ICD-9-CM 中包含分类,因此,给知识库中的每个实体一个惟一的类别标签,并为每个类别生成一个标签前缀树,以容纳属于它的所有实体。在生成文本时,约束生成的字符属于相应的类别。
- 类别精调
同一类别的实体往往有共性。根据标签拆分数据集,然后分别利用每类数据中的句子对精调模型。
基于上述方法,提出 generating and re-ranking (GR) 策略。对于每个医生输入文本,通过一个生成模型,用 beam search 方法产生几个标准的候选实体,然后,利用预训练的判别模型对所有候选词进行评分和重新排序。
论文贡献如下:
- 使用序列生成框架处理中文 ICD9 规范化中的一对多问题。
- 根据知识库中的类别约束生成序列,避免产生不合理的结果。
- 比之前模型效果好。
方法
定义一:字符生成顺序与实体中字符的顺序一致。
定义二:生成字符 ci 的前提条件包含:类别 l,以及在 l 条件下的字符序列 s=c1,c2...ci-1(前面已生成的字符串)
基于类别约束的编码
设医生输入的非标准文本为 M,最终对应出多个 ICD9 实体{e1,e2...eN}作为输出。首先,编码模型生成实体的类别标签;然后从知识库中找到该标签对应的所有实体建立前置树 prefix tree;最后,编码器生成实体字符。其中前置树和之前生成的文本都作为本时间步生成字符的约束。当新的标签产生时,前置树也被替换。
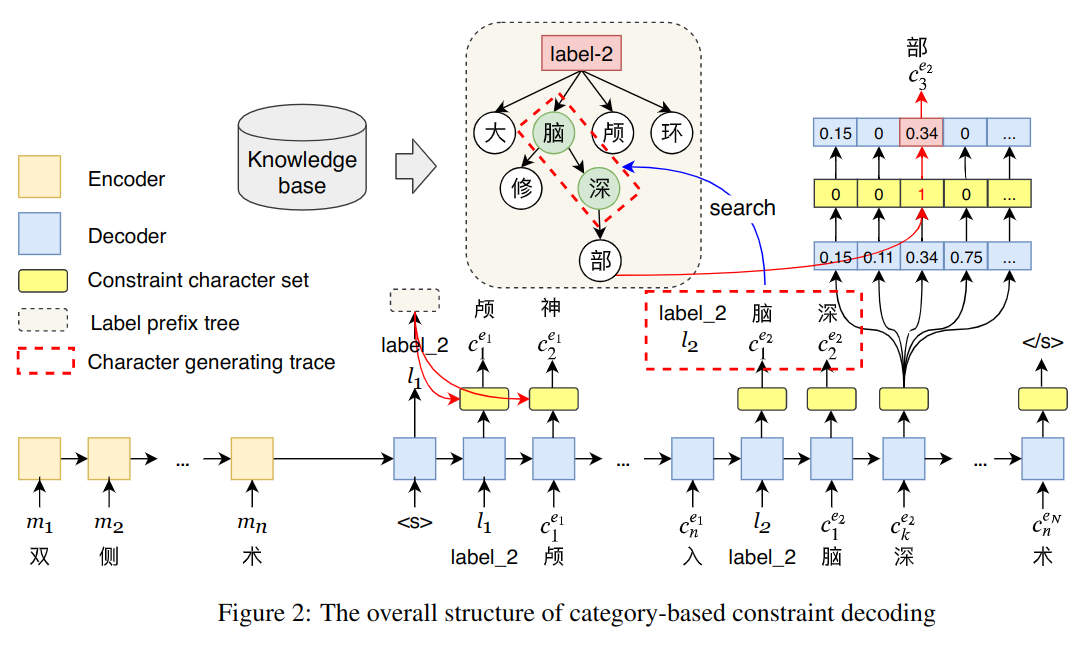
如图 -2 所示,产生第二个实体的第三个字符 c3e2 时(右上)时,根据最近的标签 l2 生成前置树,再根据前置树和前两个字符作为约束生成第三个字符。
标签前置树
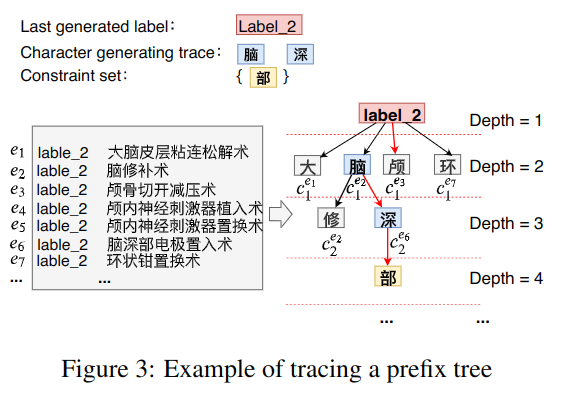
如图 -3 所示,假设之前已经生成了脑和深,且当前标签是 label-2。逻辑如算法 -1 所示:

首先,取标签 l 下的所有实体的 ICD9 文本,作为 S 集合,即图 -3 灰框中的数据,构造树的第二层是实体的第一个字,第三层是第二个字,层的深度取决于最长的实体包含几个字符。从程序的第 7 行开始遍历各实体中的所有字符,将其加入树。
有了前置树,再代入 label2, 脑, 深,即可产生约束,如算法 -2 所示:

如果之前还没生成任何字符,则返回整个树作为可选项,否则,将之前生成的所有字符作为约束,返回其约束下的所有可选项。如果无可选项,则认为之前输入的字符已经到达叶节点,加入结束符号。
约束字符集
根据约束计算λ,如果不符合约束 C,则产生 yt 的概率为 0。
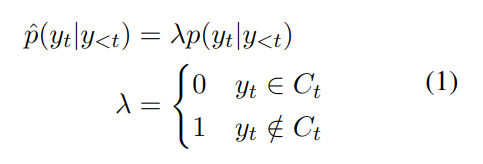
基于类别的精调
根据每个类别训练模型以针对不同类别调优模型,如图 -4 所示:
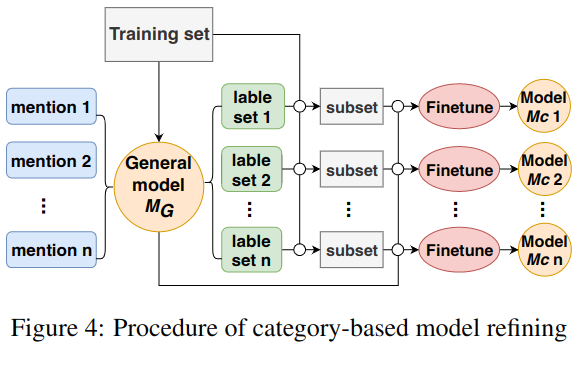
首先,基于所有训练数据训练模型 MG。
然后,使用 MG 预测测试集所属类别 t^,子集 s^,计算其标签 l^。
进而,对于每个 s^,从训练集中找到对应的子集 D^。
最后,使用 D^中数据精调模型 MG,生成模型 MC。

综上,可将训练视为两个场景,第一个场景训练通用模型,第二个场景针对子类精调模型。由于精调数据量小,为避免过拟合,只精调一轮。
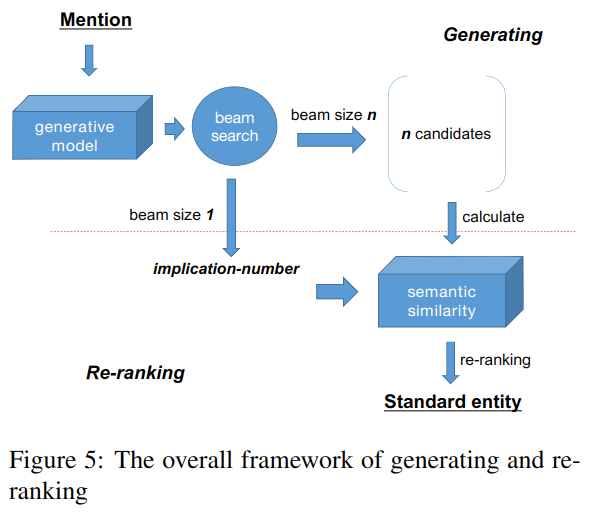
生成和重排
流程如图 -5 所示,使用大小为 k 的 beam search 直接产生候选集,每个候选集包含一个或多个实体。语义相似度模块使用 BERT 来计算医生输入和各选项的相似度得分。在一对多的情况下,选择前 n 个候选项作为最终结果,n 由 beam size 为 1 的输出决定。
实验
实验数据是 CHIP 2019 比赛中的临床实体规范化任务,数据概况如下:
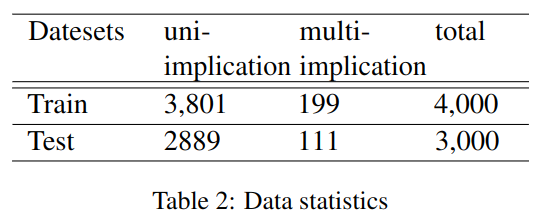
目标为 ICD9-2017-PUMCH 编码,共包含 9867 个实体,即 9867 个不同的手术名称。
与编辑距离及基于 search and re-rank 的 Bert 方法相比较,结果如下:
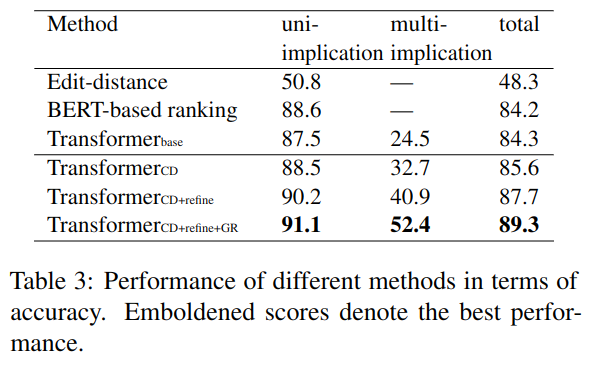
只当标准实体的数量和文本都完全正确时,才算作正确。
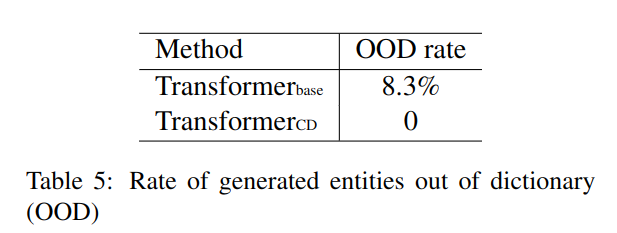
如果生成的文本不在标准数据中,就不能正常匹配,被称为 out-of-dictionary(OOD)问题,表 -5 展示了使用约束避免了这一问题。
示例如图 -6 所示:

由于字典中无”尺骨头“,通过约束,生成了”尺骨部分”。
实验还证明使用生成序列和 Beam search 方式生成的候选集与原始的 BM25 方法相比,召回率更高,生成的候选集也可以更少。
另外,基于字符的方法优于基于 token 的方法,这可能是由于如果前期分词不准会干扰后续建模,以及测试集中出现的词未必出现在训练集中等问题造成。