论文阅读_EMO_在弱条件下使用音频生成富有表现力的视频
1 | 英文名称: EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions |
读后感
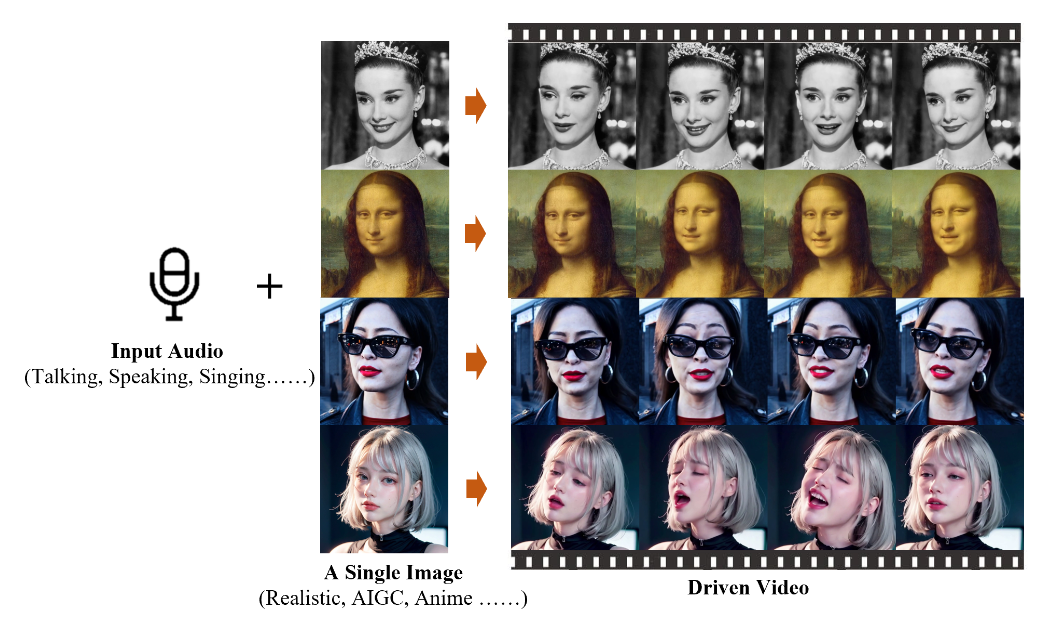
论文实现了使用扩散模型生成视频。输入是一张人像和音频文件,输出是音频对应的此人的说话视频。该功能已集成到通义千问中,输入“全民唱演/舞王”即可试用。除了真人动画,还能生成动画人物的视频。
相较于之前的方法,它不仅能控制嘴部动作,还能控制头部和表情的微妙变化。其架构也相对简单,它再次证明了扩散模型在图像和视频生成领域的主流地位,以及在生成视频领域的强大能力。
理论上,音频信息也包含一定的面部表情信息,音频提示和面部运动之间存在动态和微妙的关系。因此,可以在音频特征和表情特征之间进行对齐。文中提出的 EMO 模型主要改善了视频生成的可控性(可以设置一些参数)和稳定性(生成连续平滑的视频)。
摘要
目标:提高说话头部视频生成的逼真度和表现力。
方法:提出了一种利用扩散模型生成能力的方法的名为 EMO 的新框架,使用音频直接到视频合成方法,跳过中间的 3D 模型和提取面部特征的步骤。
结论:确保了整个视频的无缝帧过渡和一致的身份,产生了极具表现力和逼真的动画。EMO 不仅能够制作令人信服的口语视频,还能够制作各种风格的歌唱视频,在表现力和真实感方面明显优于现有的先进方法。
1 引言
以人为主的视频生成一直是研究的焦点,比如会说话的头是从用户提供的音频剪辑中生成面部表情。
音频信号包含与面部表情相关的丰富信息,理论上使模型能够生成各种富有表现力的面部动作。然而,由于音频和面部表情之间映射固有的模糊性,将音频与扩散模型集成并不是一项简单的任务。这可能导致模型生成的视频不稳定,表现为面部失真或视频帧之间的抖动。在严重情况下,甚至可能导致视频完全崩溃(误差积累)。为了应对这一挑战,EMO 模型加入了稳定控制机制,即速度控制器和面区域控制器,以增强生成过程中的稳定性。
为了训练我们的模型,构建了一个庞大而多样的音频视频数据集,积累了超过 250 小时的视频和超过 1.5 亿张图像。这个庞大的数据集涵盖了广泛的内容,包括演讲、影视片段和歌唱表演,并涵盖中文和英文等多种语言。
2 方法
文中方法能够根据给定人物肖像的单个参考图像,生成与输入语音音频剪辑同步的视频。该视频保留了自然的头部运动和生动的表情,并与所提供语音的音调变化相协调。通过创建一系列无缝衔接的视频,具有一致身份和连贯运动的长时间有声人像视频,对于现实应用至关重要。
2.1 预备知识
简单地讲,扩散模型是一种生成模型,主要用于生成高质量的图像。它通过逐步还原从噪声图像中提取的特征来生成清晰的图像。这种方法广泛应用于图像合成和编辑,目前也常常使用语言描述来控制图像生成同,即有条件的生成。(小编说:扩散模型一两句话说不清楚,请参阅我之前关于 AI 图像部分的文章)
将原始图像特征分布 𝑥0 映射到潜在空间 𝑧0 中。去噪的训练目标是:
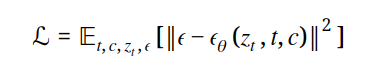
公式中 t 是时间步,C 是来自 CLIP 的 ViT-L/14 文本编码器,𝜖𝜃是改良的 U-Net 模型,通过交叉注意力机制将文本特征与潜在特征融合。
2.2 网络 pipeline
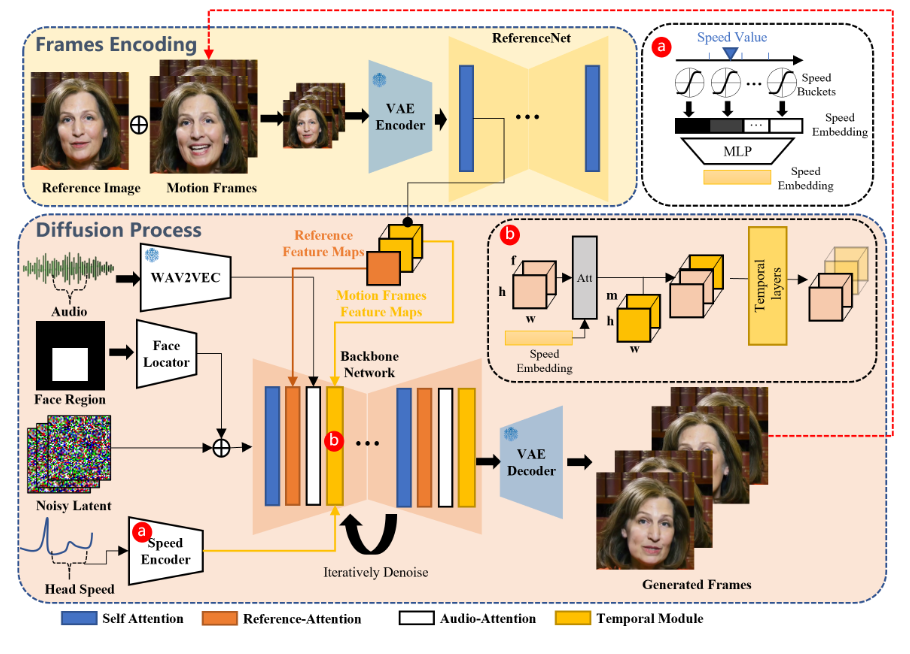
图 -2 展示了训练过程,框架主要分为两个阶段。初始阶段称为帧编码,使用 Reference-Net 从参考图像和运动帧中提取特征。在扩散过程阶段,一个预训练的音频编码器处理音频嵌入。面部区域掩码与多帧噪声结合,用于生成面部图像。然后使用骨干网络进行去噪操作。在骨干网络中,应用了两种注意力机制:参考注意力和音频注意力。这些机制分别用于保持角色身份和调节角色动作。此外,还使用了时间模块来操控时间维度,并调整运动速度。
骨干网络获取多帧噪声潜伏输入,并尝试在每个时间步长内将它们降噪到连续的视频帧。骨干网络具有与原始 SD 1.5 相似的 UNet 结构配置。
2.2.1 骨干网
文中的实验没有使用提示嵌入。因此,将 SD 1.5 UNet 结构中的交叉注意力层改为参考注意力层。这些修改后的层现在使用 Reference-Net 中的参考特征作为输入,而不是文本嵌入。
2.2.2 音频层
声音的发音和语调是生成角色动作的主要驱动力。通过预训练的 wav2vec 模型,可以提取输入音频序列的特征,并将这些特征拼接成音频表示。然而,动作可能会受到未来或过去音频片段的影响,例如在说话前张嘴和吸气。为了解决这个问题,每一帧的声音特征通过拼接附近帧的特征来定义:从当前帧前后各取一些特征进行拼接。为了将声音特征融入生成过程,在主网络中的每层参考注意力层之后,添加音频注意力层,以实现跨注意机制。
2.2.3 ReferenceNet
ReferenceNet 的结构与 Backbone Network 相同,用于从输入图像中提取详细特征。ReferenceNet 和 Backbone Network 都源自相同的 SD 1.5 UNet 架构,并继承了原始 SD UNet 的权重。目标角色的图像被输入到 ReferenceNet,以从自注意力层中提取参考特征图。在 Backbone 的去噪过程中,相应层的特征会与提取的特征图一起经过参考注意力层处理。由于 ReferenceNet 主要用于处理单个图像,因此没有 Backbone 中的时间层。
2.2.4 时间模块
大多数方法在预训练的文本生成图像架构中加入时间混合层,以理解和编码连续视频帧之间的时间关系,从而生成流畅的视频。借鉴 AnimateDiff,通过自注意力时间层处理帧内特征,将输入特征图配置为 (批量大小×高度×宽度)×帧数×特征维度,有效捕捉视频中的动态内容。
当前基于扩散的视频生成模型只能生成预定数量的帧,无法创建较长的视频序列,影响口述视频应用。为保持片段间的无缝过渡,本方法将之前生成片段的最后几帧作为“运动帧”,并输入到 ReferenceNet 中,提取多分辨率运动特征图,在去噪过程中与时间层输入合并,确保片段间一致性。生成第一个片段时,运动帧初始化为零图。
需要注意的是,虽然主干网络可以多次迭代以对噪声帧进行降噪,但目标图像和运动帧是连接起来的,并且只输入到 ReferenceNet 中一次。因此,提取的特征在整个过程中被重用,确保在推理过程中不会大幅增加计算时间。
2.2.5 人脸定位器和速度图层
时间模块可以保证生成帧的连续性和视频剪辑之间的无缝过渡。然而,由于独立生成过程,它们不足以确保角色在剪辑中运动的一致性和稳定性。本文采用了“弱”控制信号方法,对人脸位置和头部运动速度进行控制。
如图 -2 所示,使用蒙版 𝑀 作为面部区域,其中包括视频剪辑的面部边界框区域。使用由轻量级卷积层组成的人脸定位器,旨在对边界框掩码进行编码。然后,将生成的编码掩码添加到噪声潜在表示中,再输入主干网络。这样可以使用蒙版来控制角色脸部的生成位置。
创建一致且流畅的剪辑运动是很困难的,因为在生成过程中头部运动频率会有所不同。为了解决这个问题,可以将目标头部运动速度纳入生成过程。具体来说,将头部旋转速度分成多个离散的速度等级,每个等级都有一个中心值和一个半径。我们将速度重新定位到一个向量上,并使用类似音频层的方法,为每一帧生成头部旋转速度嵌入。
在时间层中,重复这个嵌入,并实现跨注意力机制,在时间维度上操作速度特征和重构后的特征图。通过这种方式并指定目标速度,可以同步不同剪辑中生成角色的头部旋转速度和频率。结合面部定位器提供的面部位置控制,最终输出可以既稳定又可控。
还应注意的是,指定的人脸区域和指定的速度并不构成强控制条件。
2.3 训练策略
培训过程分为三个阶段。第一阶段是图像预训练,其中 Backbone Network、ReferenceNet 和 Face Locator 是训练的标记。在此阶段,Backbone 将单个帧作为输入,而 ReferenceNet 处理来自同一视频剪辑的不同、随机选择的帧。Backbone 和 ReferenceNet 都从原始 SD 初始化权重。
在第二阶段,引入了视频训练,合并了时间模块和音频层。𝑛+𝑓 从视频剪辑中采样连续帧,起始 𝑛 帧是运动帧。时态模块从 AnimateDiff 初始化权重。
在最后阶段,集成速度层,仅训练这一阶段的时间模块和速度层。
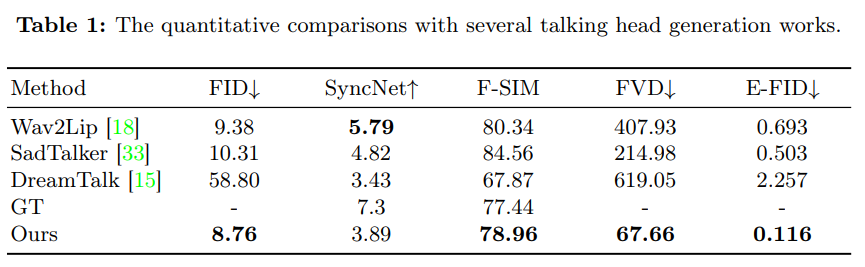
3 实验
从互联网上收集了大约 250 小时的谈话头视频,并用 HDTF 和 VFHQ 数据集进行补充来训练模型。由于 VFHQ 数据集缺少音频,因此仅在第一个训练阶段使用。我们应用 MediaPipe 人脸检测框架来获取人脸边界框区域。通过面部特征点提取每帧的 6-DoF 头部姿势,标记头部旋转速度,然后计算连续帧之间的旋转度。
为了展示该方法的优越性,采用了多个定量指标进行评估。使用 Fréchet Inception Distance (FID) 来评估生成帧的质量。为了评估身份保留情况,我们计算了面部相似度(F-SIM),通过对比生成帧与参考图像的面部特征来实现。此外,我们还使用 Fréchet Video Distance (FVD) 进行视频级别评估。SyncNet 分数用于评估唇同步质量,这是对话头应用的关键指标。为了评估生成视频中面部表情的表现力,引入了 Expression-FID (E-FID) 指标,通过面部重建技术提取表情参数并计算这些参数的 FID,以衡量合成视频中的表情与真实数据集之间的差异。