论文阅读_BEVSegFormer
介绍
英文题目:BEVSegFormer: Bird’s Eye View Semantic Segmentation From Arbitrary Camera Rigs
中文题目:BEVSegFormer: 基于任意相机的鸟瞰图语义分割
论文地址:https://arxiv.org/abs/2203.04050
领域:机器视觉,自动驾驶
发表时间:2022 年 3 月
作者:来自上海的自动驾驶创业公司 Nullmax
阅读时间:2022.05.28
其它相关网文:https://blog.csdn.net/Yong_Qi2015/article/details/124311369
介绍
之前从摄像机视图转成 BEV 的方法多以 IPM 为主,该方法需要知道摄像机的内外参数以及位置信息。在有遮挡及距离比较远的情况下,都无法达到很好的效果。近年来更多应用了深度学习方法。
优点
- 不需要摄像机的参数
- 有效聚合多摄像头数据
- 优化了图像分割效果
核心算法
(论文正文第 3 页)
三个步骤:
从一个共享 Backbone 处理各摄像机,输出 Feature map。
基于 Transformer 的编码器加强 Feature map。
解码器通过交叉注意机制处理 BEV 查询。
最终利用输出的查询结果进行语义分割。
文章的核心基本就在以下图和公式:
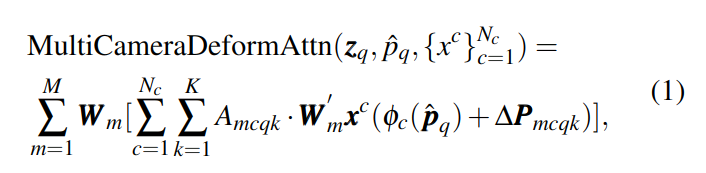
其中 m 是头数,c 是摄像头,k 是采样点个数。∆P 是 k 个采样点的偏移,A 是注意力权重。p^是参考点,φ用于标准化坐标和特征图位置的转换,q 表示 BEV 中每一个小块。
第三步 Decoder 如下图所示:
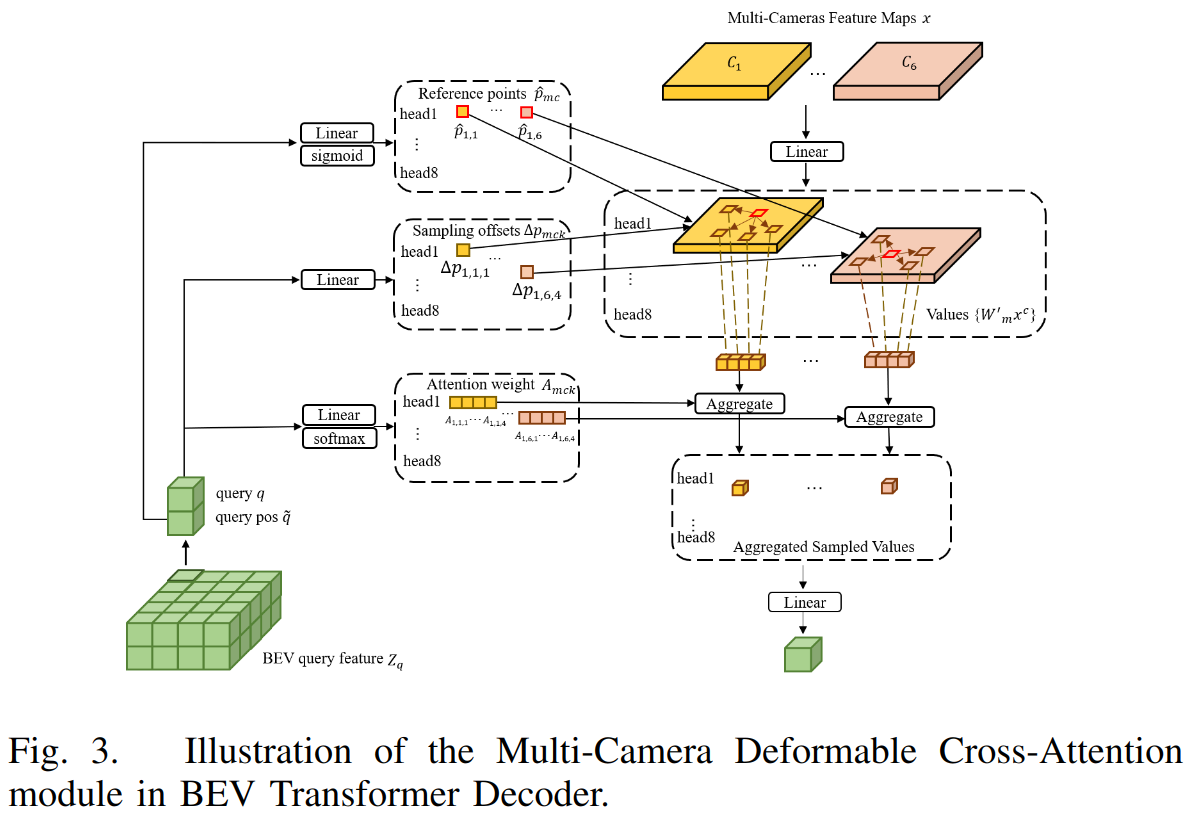
对于 BEV 中的每一个小块,箭头过程描述了每个小块是如何更新。输入是摄像头影像(黄色和橙色表示不同的摄像头,对应公式中的 x),以及之前 BEV 的查询 query q 其该块的位置 query pos q(所有块 zq,及每块的参考点 pq)。
对于每一个小块 q,使用可学习的投影层对其位置嵌入到二维的参考点
\[ \hat p_q \in R ^ {M \times N_c\times2} \]
其中是指使用两个可学习的线性映射层,以生成参考点周围的采样点(见右侧中间的虚线框),采样后线成一个序列(右侧四个黄块和橙块),再通过 Attention 为这些小块加权,最终产生了新的序列(右下角)。
与 DETR 不同的时,文中方法通过多摄像头的 Feature map 学习独立的参考点,因此网络可以根据不同的镜像机特征,自动选择不同位置的参考点。
前置知识
DETR
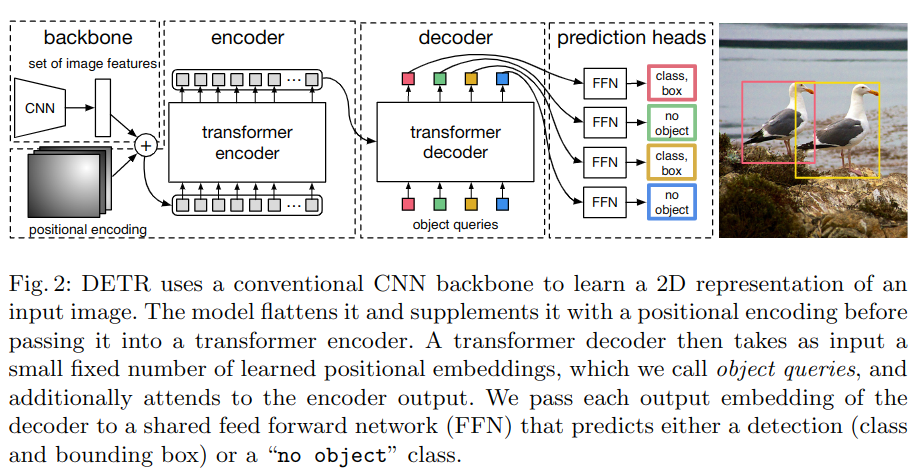
DETR 的全称是 DEtection TRansformer,是 Facebook 提出的基于 Transformer 的端到端目标检测网络。
之前目标检测方法主要是基于 Anchor,简单地说就是对图片中不同位置和大小的小方框进分类,然后再做回归精调框的大小。
DETR 同样也使用了 backbone 的 Feature map,不同的是它还加入了位置嵌入,然后送入 encoder;另外,还使用 object queries(可学习的动态 anchor)作为解码器的输入,最终将解码器的输出送入最终分类器。
Deformable DETR
Deformable DETR 是注意力模块只关注参考点周围的少量关键采样点,而不是所有点。