论文阅读_对比学习_SimCLR
1 | 英文题目:A Simple Framework for Contrastive Learning of Visual Representations |
读后感
众所周知,有监督学习相比于无监督学习和半监督学习速度更快,效果更好,但也存在一些问题,比如难以泛化解决其它问题,需要高成本的标注等等.
对比学习是一种半监督学习(自监督学习),它可以生成一种表示,用一组数表征一个时间序列,一句话,一张图... 然后再代入下游任务.具体方法是用实例间的相似和差异学习怎么描述这个实例,从而捕捉内在的不变性;从高维到低维,构建更抽象地表示.
个人感觉有监督和半监督学习各有优势,实际建模时有效结合二者,即可以提升训练效率,也能减少标注成本.
1 介绍
对比学习属于自监督学习.自监督学习一般不需要标签,通过数据本身构造模型,训练结果可以支持更多下游任务.常见的自监督学习包括:
- AutoEncoder 自编码器
- GAN 生成对抗网络
- Mask 语言模型,如:BERT
- Contrastive 对比学习模型,其原理是:语义相似 ->表征一致
文中提出了简单的对比学习表示框架 SimCLR.
本文主要贡献
- 利用数据增强构造训练数据
- 构建可学习的非线性模型,提升数据表示质量
- 构造特殊的损失函数
- 相对于有监督学习,对比学习使用更大的批处理规模和更长的训练时间
2 方法
2.1 对比学习框架
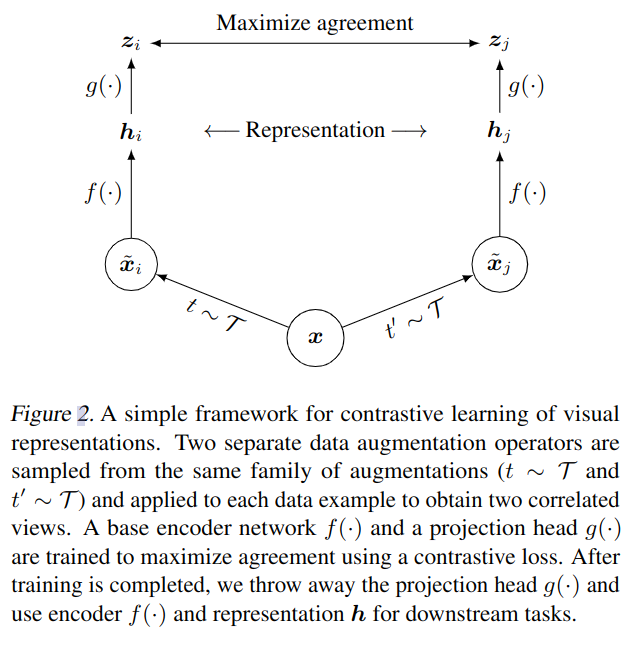
- 如图 -2 所示,对于实体 x,使用数据增强方法分别构建 xi 和 xj,将二者的组合看作正例对.
- 使用神经网络编码器 f 获取增强数据的向量表示 h,文中的 f 使用了用于图片处理的 ResNet.
- 使用小型神经网络进行投影变换 g,将向量映射到对比损失函数可以应用的数据空间,转换成向量表示 z.
- 利用对比损失函数判别正反例,正例是对同一实例增强得到的数据对,反例是对不同实例增强产生的数据对.
反例一般使用同一 batch 中的数据构造,损失函数定义如下:
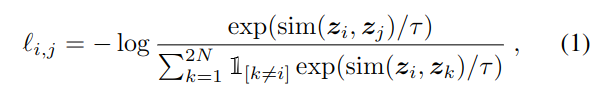
设 batch 中包含 N 个实例,每个实例生成两个数据增强,则产生 2N 个增强数据,此时分子计算的是正例间的距离,分母计算负例间的距离,τ 是温度参数.
具体算法如下:

2.2 使用大 Batch Size 训练
将 Batcch size 设置为 256-8192,此时负例数据巨大,计算量也是巨大的.使用 SGD/Momentum 优化器可能造成模型不稳定,因此,使用 LARS 优化器,TPU,32-128 个核不等,另外,还使用了全局的 Batch 归一化方法,以解决不同设备上并行训练时的归一化问题.
2.3 评价策略
以预训练的模型为基础,最上层加入一个线性分类器,在冻结的基础网络上训练,以评价具体任务,将测试集准确率作为评价指标,另外,实验还与其它半监督学习和转移学习方法进行了对比.
由于是对图片数据操作,使用了剪切,缩放,颜色失真,高斯模糊等方法进行数据增强;使用 ResNet-50 作为编码器,2 层的投影变换网络,最终将数据映射到 128 维空间内.使用 NT-Xent 作为损失函数,LAR 作为优化器,batch:4096,100 次迭代.
3 具体实现
这篇论文主要介绍了针对图片的对比学习方法,对于自然语言,时序数据,图结构的对比学习方法也与之类似,主要都是针对以下几个方面设计和实现:
- 数据增强
- 根据数据不同,增强方式如:切分/旋转/变化/随机 Mask/随机噪声/选择不同阶段数据/dropout/采样;用来自同一样本的数据增强,生成正样本对;用来自不同样本的数据增强,生成负样本对.
- 优化方法包括:通过数据增强更好地保留共性;锁定更有效的硬负例等.
- 信息编码
- 通过训练模型,将实体转换为相对低维的向量表示.
- 损失函数
- 根据数据设计损失函数,使正样本更加一致,负样本完全不同,邻近样本比正样本远,比负样本近.
- 其它优化
- 根据数据设计更复杂的结构,比如利用图中的邻居信息构建介于正负样本之间的样本作为中间样本;利用时序数据中来自同一数据源的不同时段数据作为中间样本....
3.1 数据增强

文中对图片的处理方法如图 -4 所示,就其本质来看,数据增强的目标是调整一些已知特征,让模型学到图中未被修改的深层次特征.这也带来一些问题,比如上图中,增强只与具体图片相关,模型学到了这张图片中的狗,但并未学到狗的共性,这一点稍逊于有监督学习.
不同的增强方法学习效果也不同,图 -5 展示了不同方法,以及不同方法组合的影响:
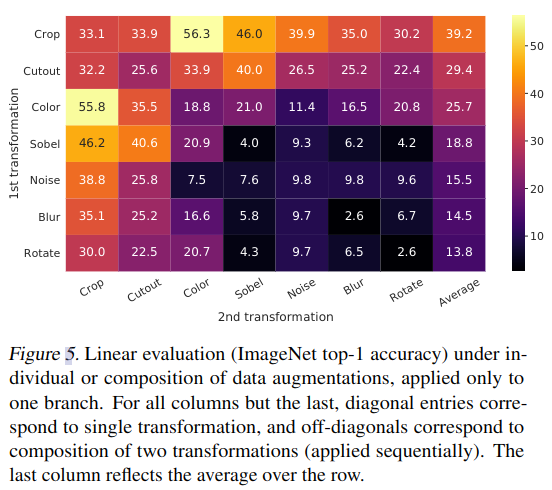
可以看到,尽管模型可以区分对比学习中的正反例,但任何单个变换都不足以学习到很好的表征,而颜色失真和剪切的组合效果明显,这可能是由于遮蔽了单张图片的特性,从而学到了共性.
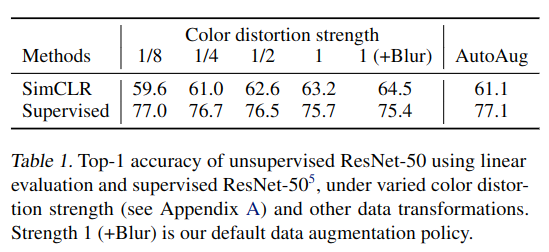
另外,从表 -1 中可以看到,数据增强的变化越大,SimCLR 学习效果越好:
3.2 网络结构
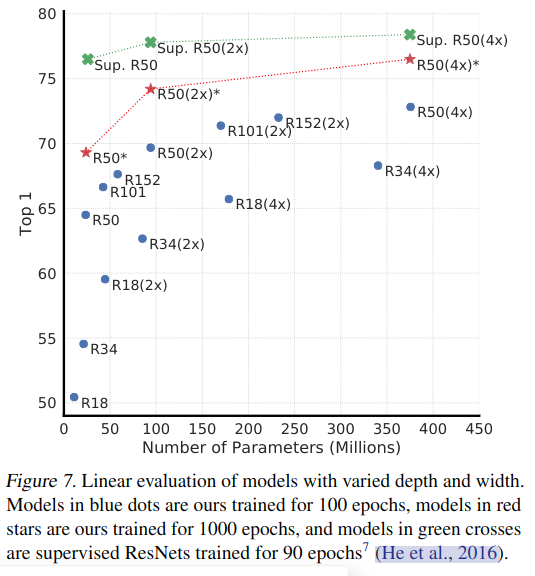
无监督对比学习受益于更大的模型.如图 -7 所示:绿叉是 90 次迭代的有监督学习,红星是 1000 次迭代的对比学习,蓝点是 100 次迭代的对比学习.从中可以看到有监督学习的优势.对于无监督学习,网络的深度宽度影响更大.
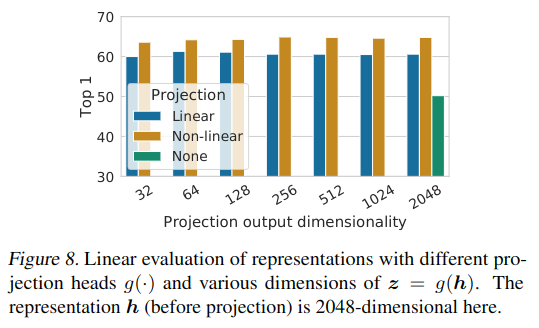
投影变换可提升表示质量.图 -8 展示了使用不同结构的投影变换效果,对比结果发现,非线性变换(加 ReLU 激活函数)效果最好,而与输出维度无关.
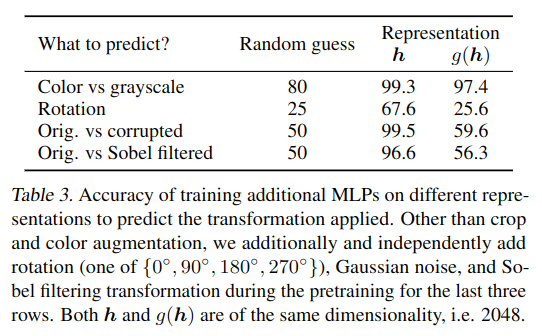
如表 -3 所示,投影前的表示比投影后的表示携带更多信息,这可能是由于投影函数去除了一些对其它下游任务有用的信息.
3.3 损失函数和 Batch Size
实验证明,不同的损失函数,超参数对实验结果有显著影响.另外,更大的 batch size 及迭代次数也能更好地优化模型.这可能与负例的硬度(难度)和数量相关.
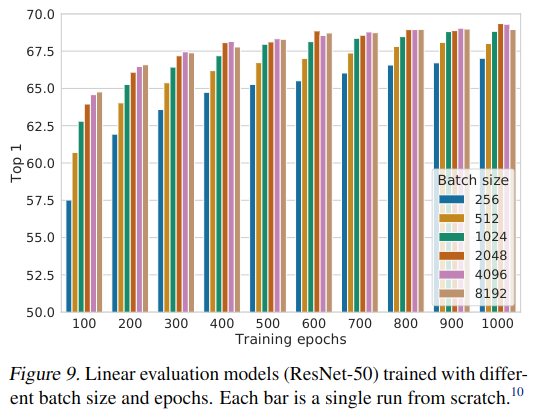
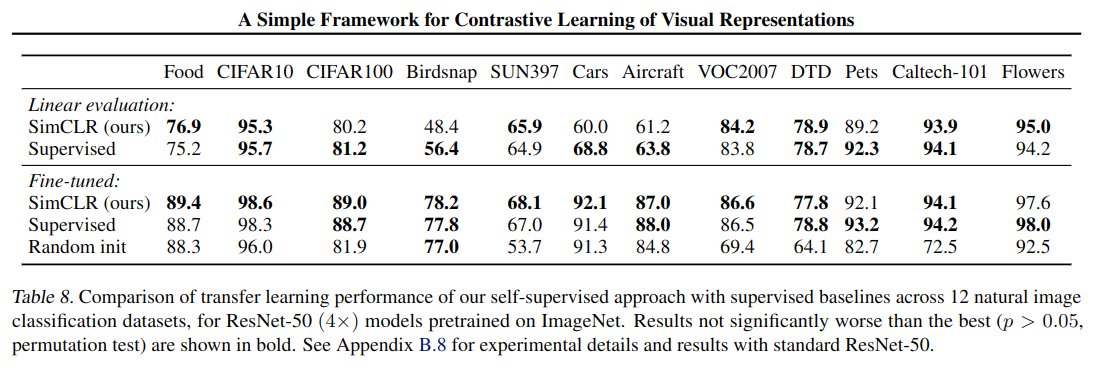
4 实验
主实验结果如下: