论文阅读_模型剪枝_彩票假设
英文题目:The Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models
中文题目:用基于彩票假设方法裁剪视觉模型
论文地址:https://arxiv.org/pdf/2012.06908.pdf
领域:机器视觉,深度学习,模型剪枝
发表时间:2021
作者:Tianlong Chen 等,德克萨斯大学
出处:CVPR
被引量:26
代码和数据:https: //github.com/VITA-Group/CV_LTH_Pre-training
阅读时间:22.10.06
读后感
文章介绍了一种针对图像处理的剪枝算法,不同与以往先训练后剪枝的方法,它的目标是直接训练出一个稀疏的子网络,并使子网络性能与稠密网络性能相当。
介绍
预训练模型提升了计算机视觉的效果,目前主流的方法是有监督学习和半监督学习。作者提出:可否在不影响下游任务性能的同时,降低预训练模型的复杂度?
文中提出基于彩票假设的方法(lottery ticket hypothesis:LTH),LTH 能在海量的稠密网络中,识别出高度稀疏的匹配子网络,同时实现完整模型的性能。
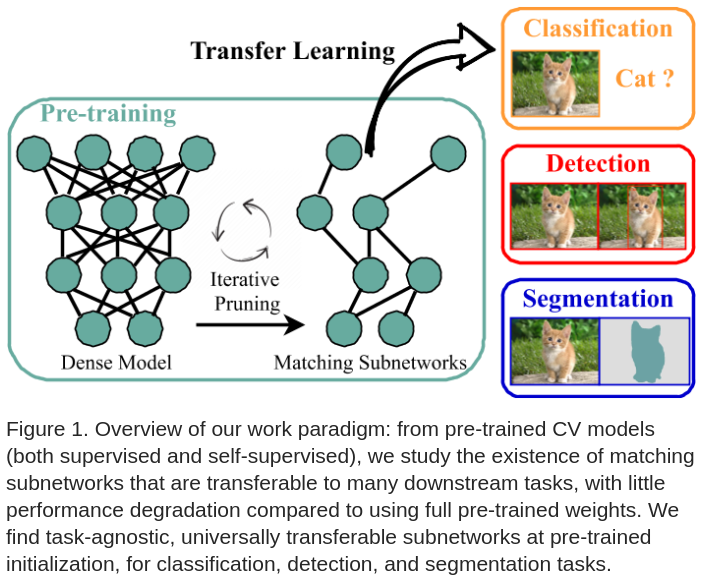
文中提出从两个角度结合预训练模型和 LTH:(1) 把正常预训练出的模型权重作为 LTH 的初始化参数;(2) 寻找匹配的子网络常需要多轮修剪和重新训练,因此尽量让子网络能被各种下游任务重用,如图 -1 所示:
剪枝算法一般分为非结构化剪枝和结构化剪枝,前者根据权重大小进行稀疏化;后者使用移除通道等方式,适用于更多硬件。
LTH 与传统的先训练后剪枝方法不同,它致力于训练与稠密网络性能相当的稀疏的子网络。
方法
数据
把 ResNet-50 作为基础模型,将分类、目标检测和分割作为下游任务,不修剪第一个卷积层和与具体任务相关的最后层。定义 f(x; θ, γ),其中 x 是输入的图像,θ是模型参数,γ是与具体任务相关的参数。
有监督预训练使用 ImageNet 训练 ResNet-50 模型;半监督训练使用基于 ResNet-50 的 simCLR 和 MoCov2 模型。
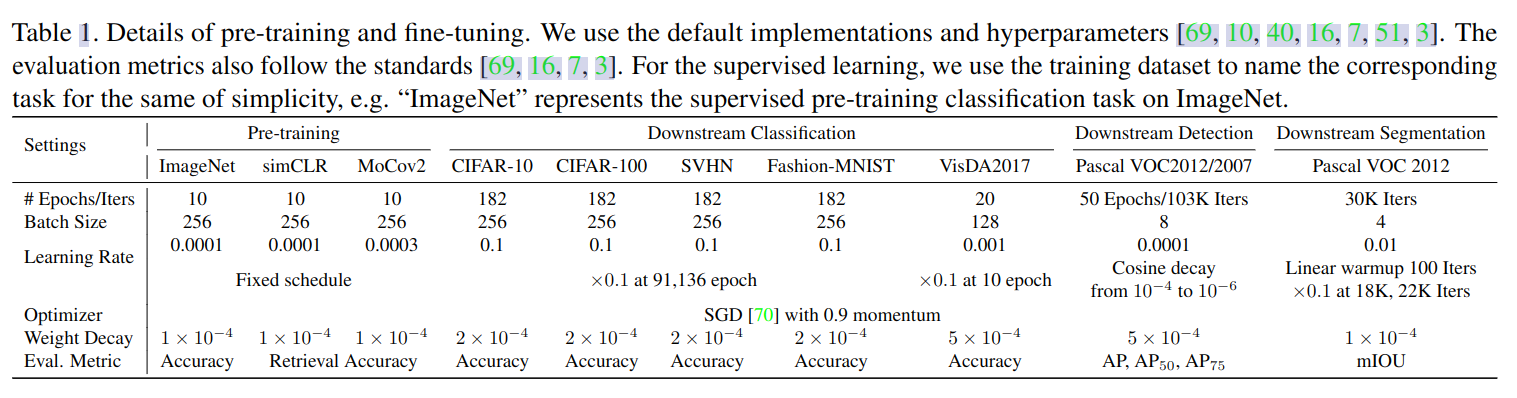
所有预训练都使用 ImageNet 数据,下游任务使用 Fashion-MNIST,SVHN,CIFAR-10,Pascal VOC 等数据集,这些任务在分辨率,数据源,类别,颜色空间都有差异,具体如表 -1 所示:
子网络
子网络:f (x; m⊙θ, ·),其中 m 是用于剪枝的二值 mask,⊙是元素层面的乘积,设 A 为针对具体任务 T 的算法,t 为迭代次数。θp 为预训练的权重;θ0 为随机初始化的权重;θi 为第 i 轮训练后的权重。E 为评价函数。定义如下:
可达子网络
可达子网络需要满足如下条件:
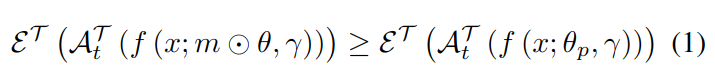
即:在使用相同的算法 A 和评价函数 E 的条件下,可达子网络的表现不比稠密网络差。
中奖奖券
如果 f(x; m⊙θ, r) 在 θ=θp 的条件下是可达子网络,此时的算法 A 就是中奖的奖券。
普适子网络
子网络 f(x; m⊙θ, γTi) 用于适配指定任务γTi,适用于所有任务的方法叫作普适子网络。
剪枝方法
具体实现使用经典的迭代权值剪枝方法 (IMP),首先训练未修剪的密集网络用以完成任务 T,然后删除部分具有全局最小值的权重,以修剪网络,使用该方法多次迭代。具体如算法 -1 所示:

预训练中奖奖券的迁移
图 -2 展示了不同预训练模型稀疏参数的性能:
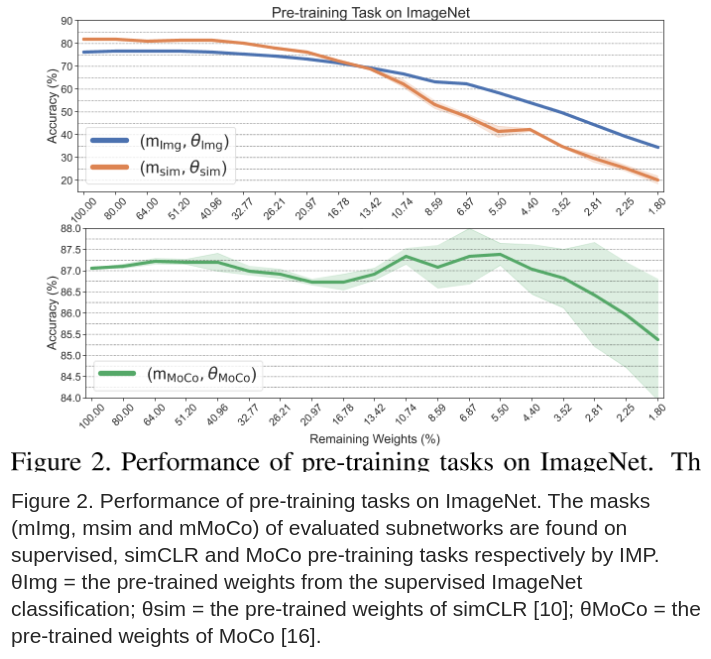
下面将在不同任务中,从三个角度讨论:(1) 中奖彩票在下游任务中表现如何?(2) 有监督和无监督模型哪个更好?(3) 普适模型和任务相关的模型有啥差异?
迁移到分类任务
结果如图 -3 所示:
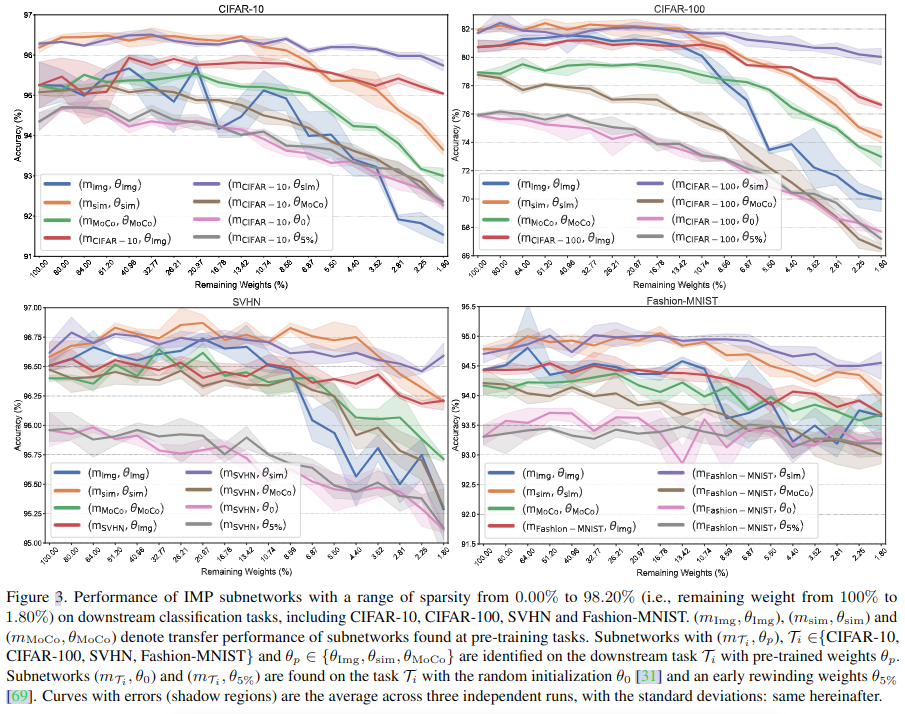
- 普适子网络 (mP,θp) 可迁移到不同的下游分类任务。可以看到三种模型,只要不修剪得太厉害,其精度在修剪后差异不大。
- 不同的预训练方式(有监督和自监督),对于不同数据集,表现不同。
- 针对具体任务训练的模型 f(x; mT⊙θp, ·) 只在极度修剪时优于普适模型 f(x; mp⊙θp, ·)。使用预训练模型参数作为修剪模型的初始参数时效果最好,使用随机初始化和少量迭代初始化的模型(粉色和灰色)在所有任务中都更差。
迁移到目标检测和分割
效果如图 -5 所示:
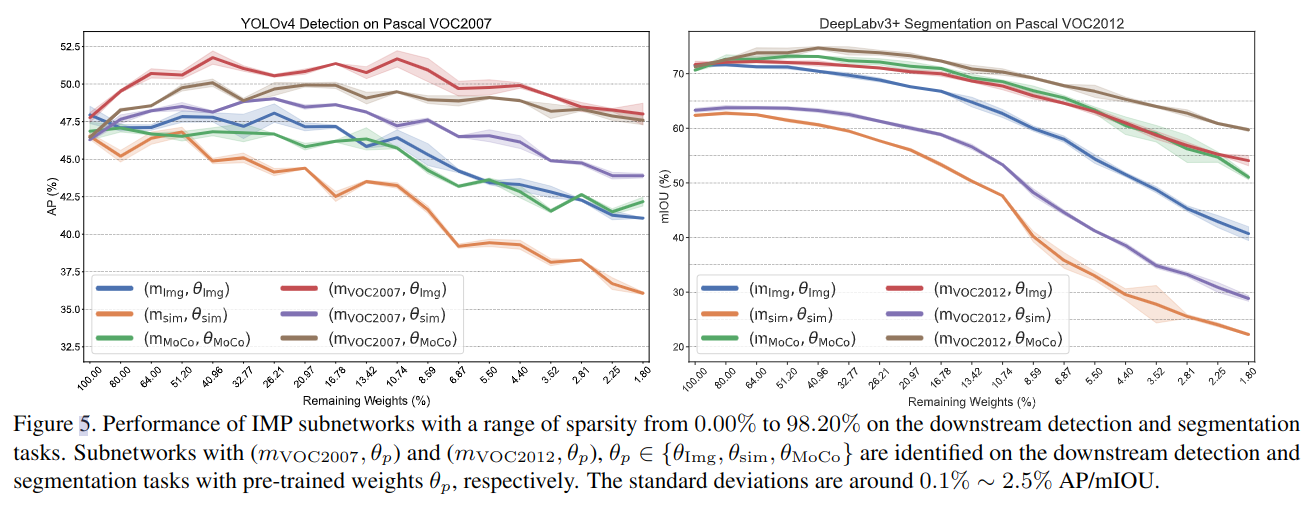
- 普适子网络 (mP,θp) 可成功地迁移到不同的下游任务中。
- 不同于分类任务,在目标检测和分割任务中表现一致:MoCo 都表现最好,有监督模型一般,Sim 模型最差。
- 针对具体任务训练的模型明显优于普适模型。