论文阅读_代码生成_CODEFUSE
1 | 英文名称: CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model |
读后感
CODEFUSE 是蚂蚁集团开源的代码生成模型,目前开源了两个版本:CodeFuse-13B 和 CodeFuse-CodeLlama-34B。其中,13B 是基于论文中设计的模型架构,34B 则是在 CodeLlama-34b-Python 的基础上进行微调。
从整体上看,无法确定 CODEFUSE 是根据自己设计的架构从头训练,还是基于 CODELAMMA 进行自然语言训练并逐步微调,哪个更好。论文需要有创新性,打榜又需要高分,所以只能采用这种写法。
既然如此,就没必要深究 CODEFUSE 的模型结构了。不过仍有一些可以学习的地方,比如从实验结果来看数据微调有效;并且介绍了从头训练一个 13B 代码模型所需的数据、硬件、时间以及可能遇到的问题;另外,他推出的 CODEFUSEEVAL 评测集,也挺全面的;这里至少证明了 CODELLAMA 精调后的效果,并且还开放了模型,网上还有一些量化后可以在 4090 上运行的轻量级版本。

引言
CodeFuse-13B 使用 LoRA/QLoRA 使用自预训练的基本模型对多个代码任务进行了微调,而 CodeFuse-CodeLlama-34B 使用 CodeLlama-34b-Python 进行了微调。令人兴奋的是,CodeFuse-13B 超越了其他类似大小的代码 LLMs,CodeFuse-CodeLlama-34B 在 HumanEval 基准测试中优于 GPT4 和 ChatGPT-3.5。
主要贡献
- 介绍了 CodeFuse-13B,这是一个具有 13B 参数的开源预训练代码 LLM 及其训练过程。它专为具有中文提示的代码相关任务而设计,支持 40 多种编程语言。
- 为各种 IDE 开发了 CodeFuse 扩展。这些扩展使开发人员能够将 CodeFuse 无缝集成到他们的编码工作流程中,从而提高生产力和代码生成能力。
- 评估了 CodeFuse 在各种应用场景中的有效性,包括代码生成、代码转换、代码注释和测试用例生成。结果表明,CodeFuse-13B 的 HumanEval Pass@1 得分为 37.10%,优于其他具有类似大小的多语言模型。此外,CodeFuse-13B 在涉及中文提示的实际场景中优于其他模型。
CodeFuseEval
(以下内容来自 CodeFuse 官方知乎帐号)
CodeFuse 官方:CodeFuseEval - 代码类大模型多任务评估基准
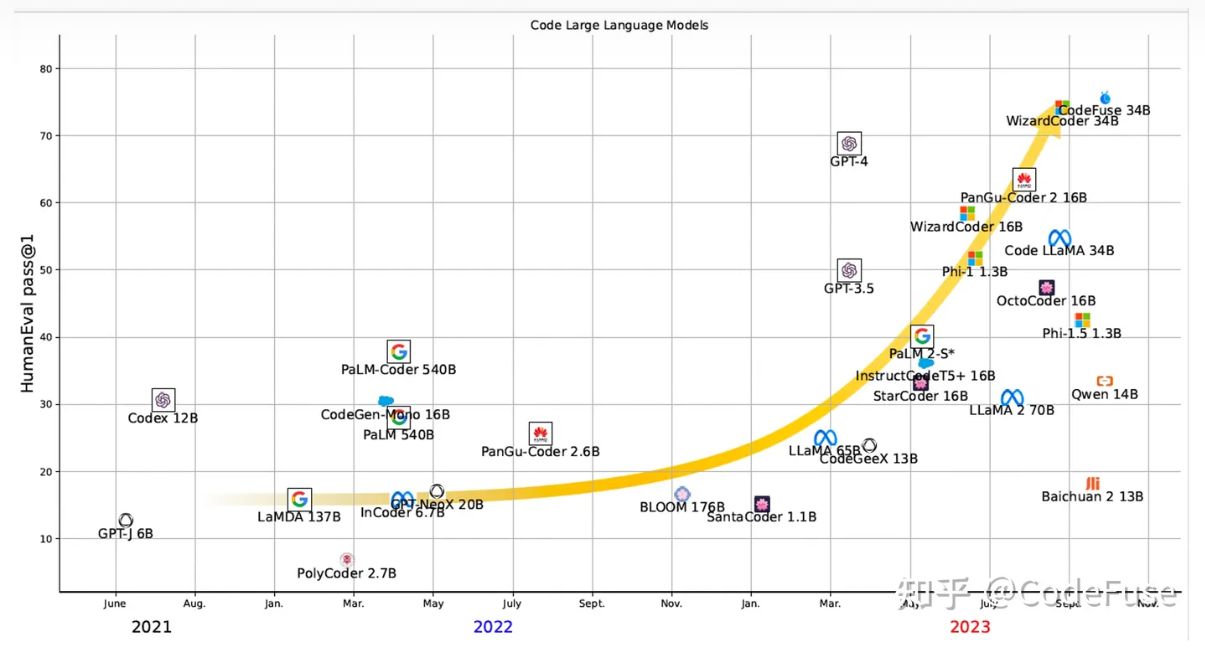
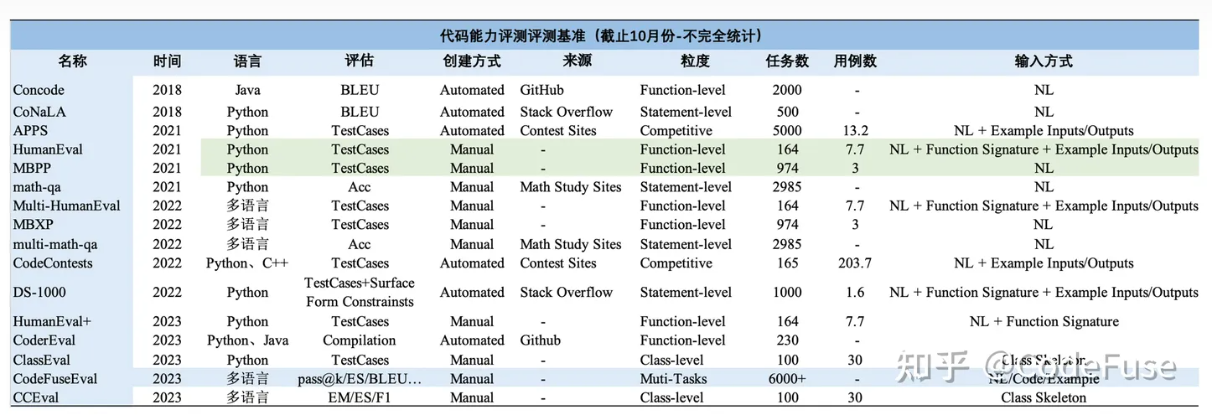
评估大模型在代码补全、自然语言生成代码、测试用例生成、跨语言代码翻译、中文指令生成代码、代码注解释、Bug 检测/修复、代码优化等不同任务的能力表现。
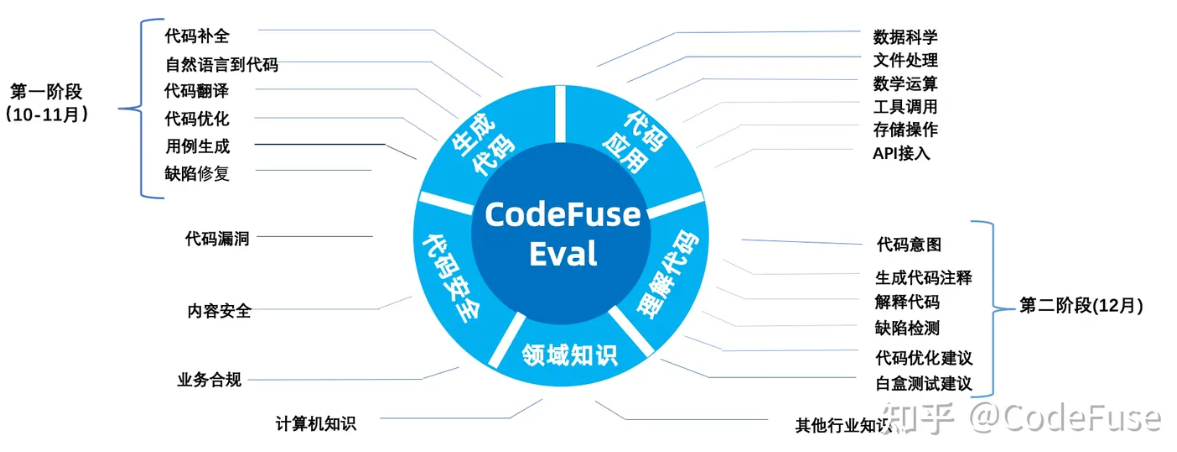
本期开放的评测集包括代码生成、代码翻译、自然语言生成代码等多类任务共 6300+ 任务覆盖 Java、C++、JS、Python 等 6 种编程语言。同时,开放了配套的环境镜像及框架。