基金交易量预测比赛_1_我的方案
1 比赛介绍
1.1 题目介绍
- 比赛名称:AFAC2025 挑战组 - 赛题一:基金产品的长周期申购和赎回预测
- 具体赛题请参见:https://tianchi.aliyun.com/competition/entrance/532352
- 参赛者需要:
- 借助大模型,自主获取并构建其他有效特征。
- 训练一个时序模型,有效建模产品收益和市场行情波动,预测每只基金在 2025/7/25 至 2025/7/31 七天内每日的申购量和赎回量。
- 比赛提供的数据:
- 自 2024-04-08 以来的 20 支基金申购和赎回数据,以及对应的几个界面的曝光量。(周期时间短、基金数据少、可获取数据的渠道有限)
- 注意:
- 预测的不是价格,而是交易量。
1.2 Demo 程序
主办方提供了一个 demo 程序:包含 400 多行代码,涵盖了时间特征提取、调用大模型、生成 embedding、使用 lightgbm 建模、生成提交文件等功能。该程序需要进行少量修改才能运行。其核心是:用大模型提取特征 + 机器学习时序预测。
距离我上次参加比赛已经有七八年了,机器学习和时序算法仍然是 xgboost、lightgbm、prophet,没有太大变化,只是在特征提取方面引入了大模型。
2 数据分析
3 我用到的外部数据
- 基金相关信息主要通过 deepseek 联网模式获取。数据抽取及最终转换为 CSV 格式的过程均可在网页上操作。
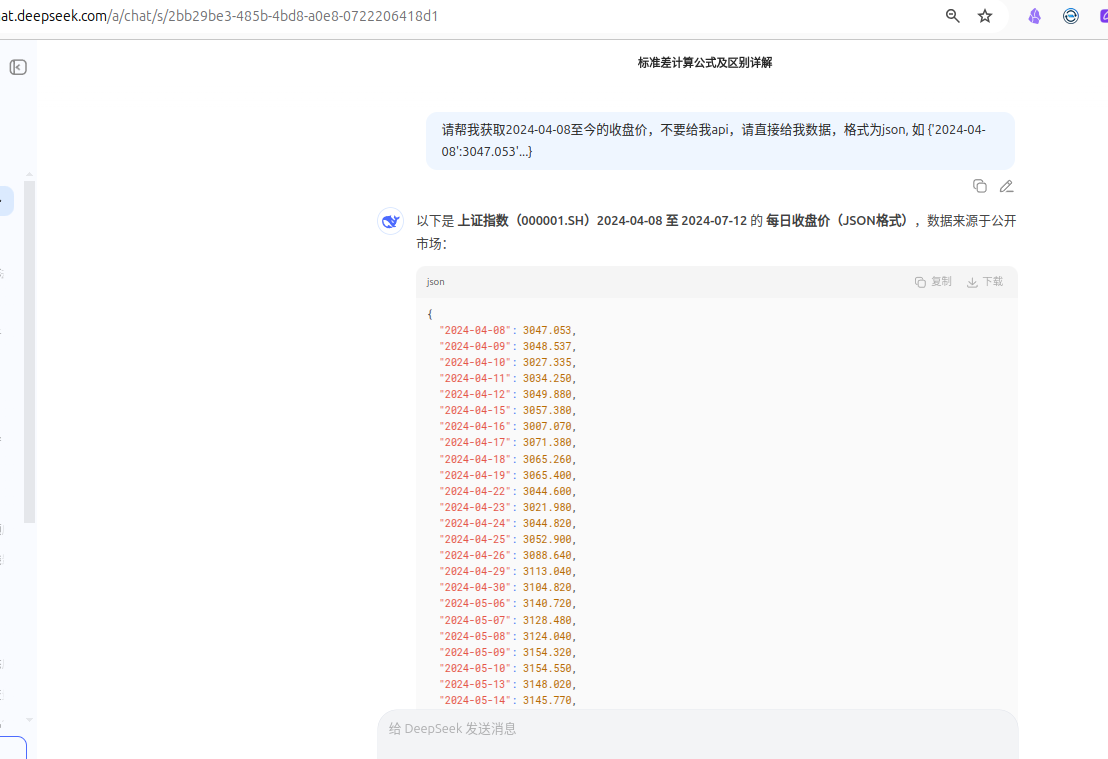
- 无法让一次让大模型获取自 2024 年 4 月 8 日起至今的指数收盘价,获取大批量真实数据很难通过大模型实现。
- 我使用 akshare API 下载了这些基金的净值数据用于上述数据分析。后来发现比赛不允许使用外部数据,而且使用后效果也没有提升,因此在最终建模时没有采用。
以下是懒人数据提取方法(通过 deepseek 网页版的联网模式获取):
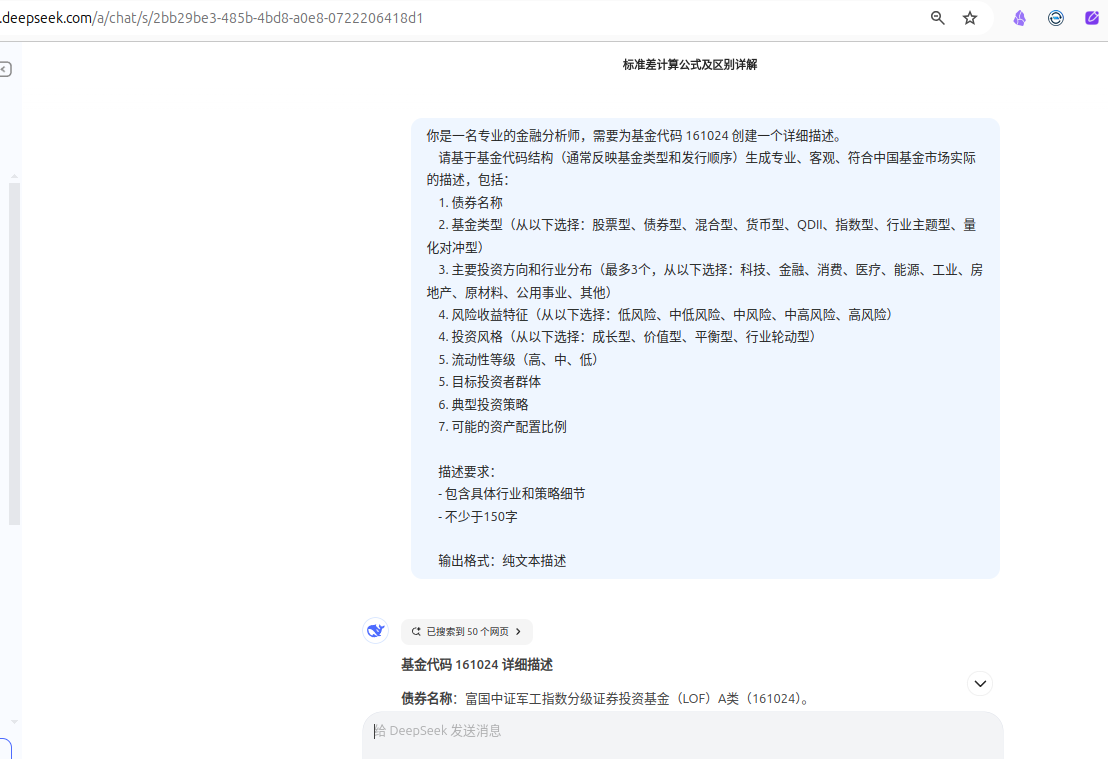
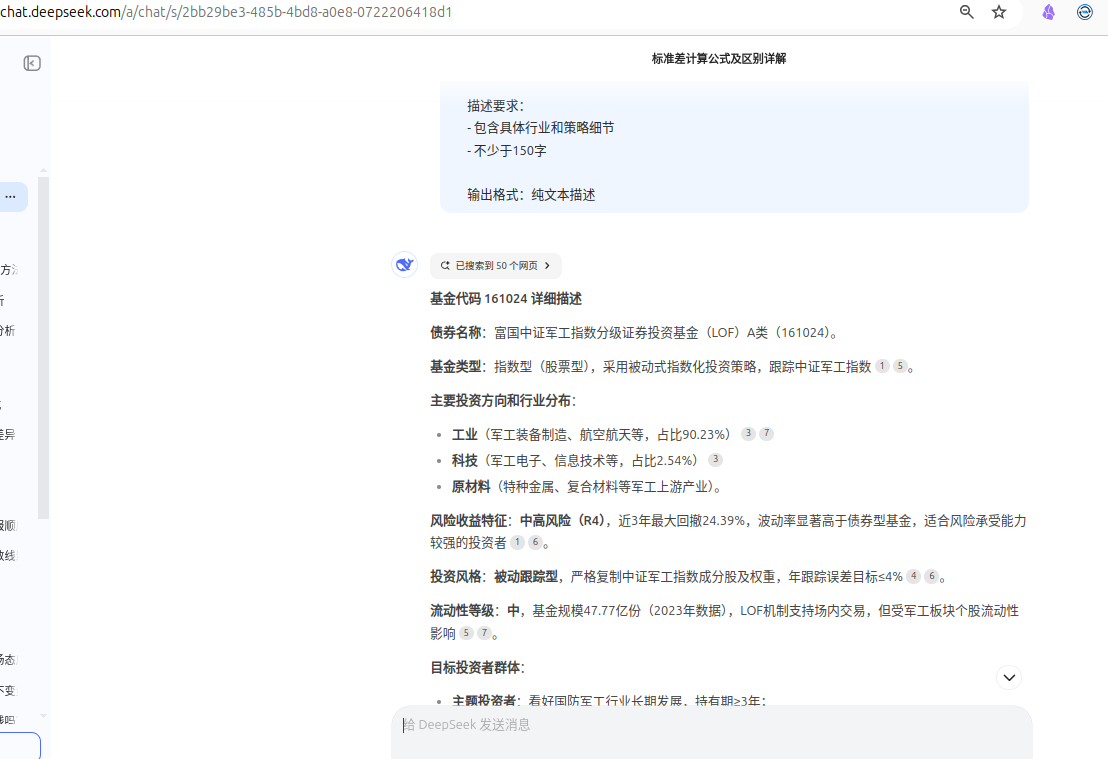
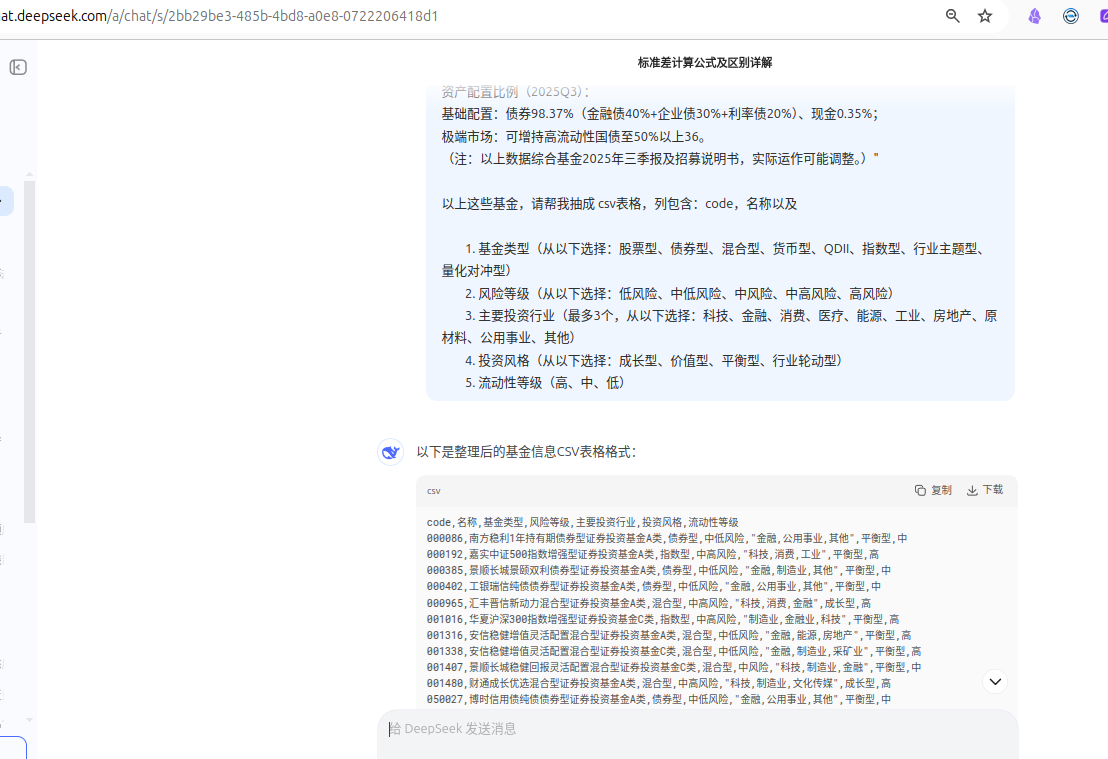
获取 A 股指数数据:(不太稳定,多试几次,有时候能出来)
(获取股票数据见:金融_工具_总览)
4 建构特征
根据对业务的理解提取特征。
4.1 映射目标值 y
由于每支基金的规模不同且数据有限,直接预测具体数值难度较大。一个重要的发现是,使用一周前的数据来预测当天的数据,可以获得一个不错的得分。这是因为:
- 在预测未来的七天中,七天前的数据已经存在,可以直接使用。
- 七天的时间跨度不算太长,能够很好地反映基金近期的交易量。
- 由于时间间隔是七天,不需要额外考虑星期几的因素。
在此基础上,可以进一步思考:将当前量与七天前量的变化率作为预测目标。
4.2 去掉极值
在将 y 从预测具体量转换为变化率后,对变化率的分布进行了分析,发现有些值特别大,呈现出一种“平地起高楼”的形态。这种情况可能与信息以及突然出现的政策相关,事先很难预测出来,即使有预感也无法预测出具体出现的日期。因此,我们对小于 0.1 和大于 0.9 的分位数进行了截断处理。
4.3 时间特征
在特征提取过程中,我根据 demo 程序提取了一些与日期时间相关的数据,比如假期等信息。
4.4 基金信息
也是按照 demo 来做的,通过提示词提取了与基金相关的信息(文字上略做调整):
1 | 1. 债券名称 |
然后,将数据处理为 LightGBM 模型能识别的 one-hot 编码。需要注意的是行业分布,不仅要拆分所属行业,还要处理顺序,例如:科技、金融、工业。由于科技排在最前面,因此给予了较大的权重。
此外,结合认知,额外增加了一些特征,例如:基金名是否包含“军工”关键字。因为虽然军工行业属于工业,但已知今年军工的走势与一般工业有所不同。
4.5 Embedding
加了之后,感觉没什么用,而且还需要下载 Torch 相关的安装包,所以我就给删掉了。肉眼观察,除了“军工”这个词外,没有发现其他特别的关键字。
4.6 统计特征
将七天前和十四天前的交易量作为当前行预测的特征,是时序预测中常用的方法。另外,对七天前的交易量进行了以下操作:提取最大值、最小值、平均值、标准差等。还对本周与前一周、前一周与前两周的值进行差分,计算趋势的斜率。
需要注意的是,在计算统计特征时,可能会导致数据泄露。例如,将从今天开始倒推七天的均值作为当前实例的特征,在预测五天后的数据时,这个均值是无法获取的。这会在测试集中取得很好的结果,使某些特征的重要性看起来很高,但在实际预测未来时,由于缺乏这些已泄露的特征,实际效果可能不佳。
另外,还引入了当天之前几天大盘的趋势。其原理是,大盘好的时候,大家倾向于购买股票和偏股基金;而大盘不好的时候,大家更倾向于购买债券。
5 训练模型
在建模过程中,我测试了线性回归和随机森林,并最终选择在演示中使用 LightGBM。我训练了四个不同的模型,分别用于预测:第一天的申购金额、第一天的赎回金额、第二至第七天的申购金额,以及第二至第七天的赎回金额。
根据常识,前一天的交易量与当天的交易相关性必定大于七天前的数据。然而,在当天预测未来七天时,后六天无法准确得到前一天的交易量。如果将预测值而非真实值代入模型,可能会导致更大的误差。于是,我尝试通过加入一些字段来标记预测的是第几天,同时为训练数据加入扰动以模拟前一天预测值不准确的情况,但效果并不理想。最终,我决定使用两套模型进行预测。
训练一开始进行了 train/val 切分,后面使用全量数据进行训练。选择使用 MAE 作为损失函数,替代 RMSE,以减少极端值对模型的影响。此外,还进行了一些特征筛选,使用 SHAP 方法限制特征数量,以防止过拟合。测试结果表明,这样做提升了模型效果。
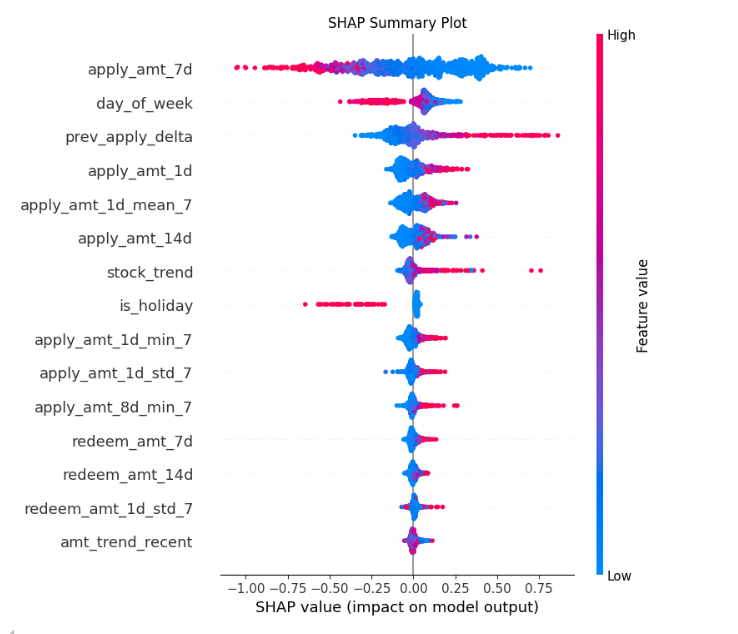
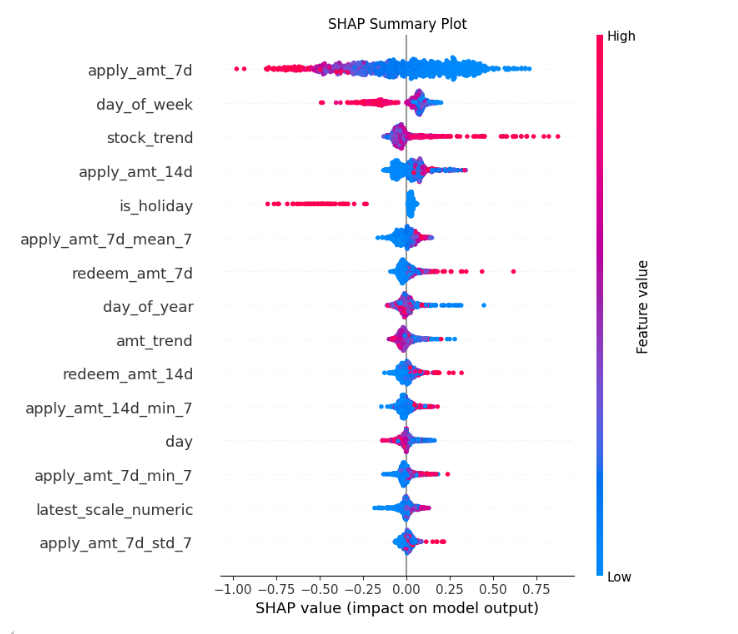
下面展示了预测第一天的模型和预测后几天的模型所用的特征分析:在预测第一天时,前一天的各种统计特征排名靠前。可以想见,如果用它来预测后几天,不知道前一天及前几天的具体统计数据,使用这个模型进行预测一定会不准确。
在一日预测中,前 1 天的 统计特征、趋势及日期特征比较重要。
在多日预测中,7 天和 14 天的统计特征、趋势及日期特征比较重要。
6 预测
预测时使用滚动预测,相比直接切分测试集数据,这种方法更贴近真实场景。但仍需注意数据泄漏问题,尤其是在添加滚动特征和统计特征时。
在这里,我用了一个小技巧:添加 LEAK 标记,故意泄漏数据,然后比较泄漏前后的差异。
在预测之后,我还尝试了一下后处理。具体方法是:当预测值与之前的均值相差多倍标准差时,进行截断。
7 评测
7.1 评测程序
当我看到这个比赛时,距离结束已不到一周。也就是说即使我当天就上传了结果,也要等到 A 榜结束后才能看到自己的首次成绩。于是,我让 Copilot 写了一段代码来模拟赛题公式的评测。这样,就可以利用历史数据来对比我的模型与历史最佳成绩之间的差异了。
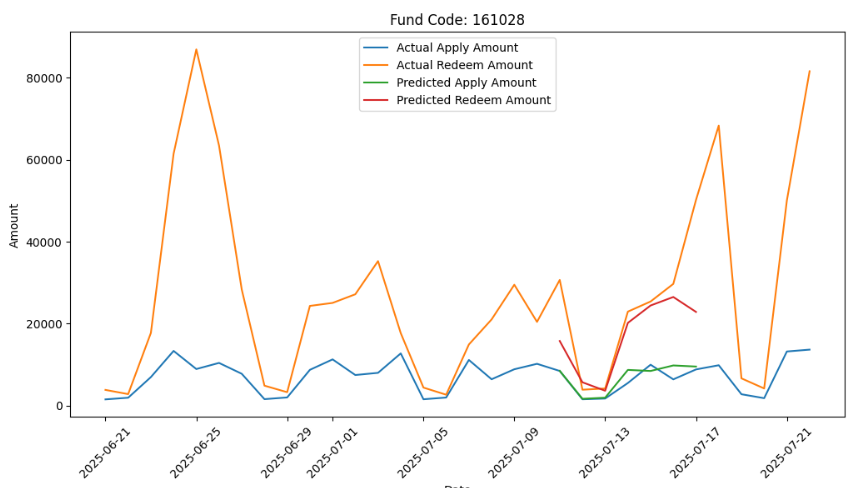
7.2 做图直观评测
把一支基金的历史数据和预测数据画在同一张图上进行对比,看起来更加直观,更容易发现问题。用此方法对预测误差大的实例进行问题具体分析。
8 反思
9 源码
https://github.com/xieyan0811/AFAC2025_xy