论文阅读_大语言模型_Llama2
1 | 英文名称: Llama 2: Open Foundation and Fine-Tuned Chat Models |
1 读后感
这是一篇 77 页的论文,正文也有 36 页,让人望而却步。整体分成:Introduction,Pretraining,Fine-tune,Safety,Discussion,RelateWork, Conclusion 几部分,如果没有时间,看看前三个部分,大概 20 页左右也就差不多了。
产出的模型从 7B 到 70B 参数,其成果除了基本的 LLAMA-2 模型,还有精调的 LLAMA 2-CHAT 模型,其精调模型与 ChatGPT (3.5) 性能相当,可作为闭源模型的替代品,且 70B 的体量也是可接受的。
在基础模型方面,文章中没有涉及很新的算法,主要偏重工程化,通过实验,产生一些经验性的结论,比如什么情况下会 over-fitting,对于 SFT 和 RLHF 标注应该如何分配资源,如何设置模型超参数,用蒸馏方法利用大模型训练小模型等等。
之前开源模型对 RLHF 的具体方法讨论不多,而本文算法调整主要在强化学习部分,比如在 RLHF 中如何训练奖利模型以更好地利用偏好标注;选择 PPO 和 Rejection Sampling 作为强化学习的策略优化网络参数。如果你对 RLHF 具体实现感兴趣,比较推荐看看这篇文章。
2 介绍
之前的开源模型效果往往与 GPT-3 相当,而像 ChatGPT、BARD 和 Claude 这些封闭的大在模型经过 RLHF 精调,更符合人类偏好。精调往往需要巨大的算力和人工标注成本,且常是不透明且不易复制的,这限制了社区推进人工智能对齐的进展,文章致力于改进此问题。
文章产出包括:
- Llama 2:Llama 1 的更新版本,使用新的公开数据组合进行训练。还将预训练语料库的大小增加了 40%,将模型的上下文长度加倍,并采用分组查询注意力机制。最终发布具有 7B、13B 和 70B 参数的 Llama 2 基础模型。
- Llama 2-Chat:Llama 2 的微调版本,针对对话用例进行了优化。也发布了具有 7B、13B 和 70B 参数的模型。
3 预训练
预测训练使用了 从 Touvron(2023 原 Llama 论文)中描述的预训练方法。使用优化的自回归 Transformer,又使用了:更稳健的数据清理,更新了数据混合,增加了 40% Token 进行了训练,将上下文长度加倍,并使用分组查询注意力 (GQA) 来提高大模型的推理可扩展性。表 -1 比较了新 Llama 2 与 Llama 1。
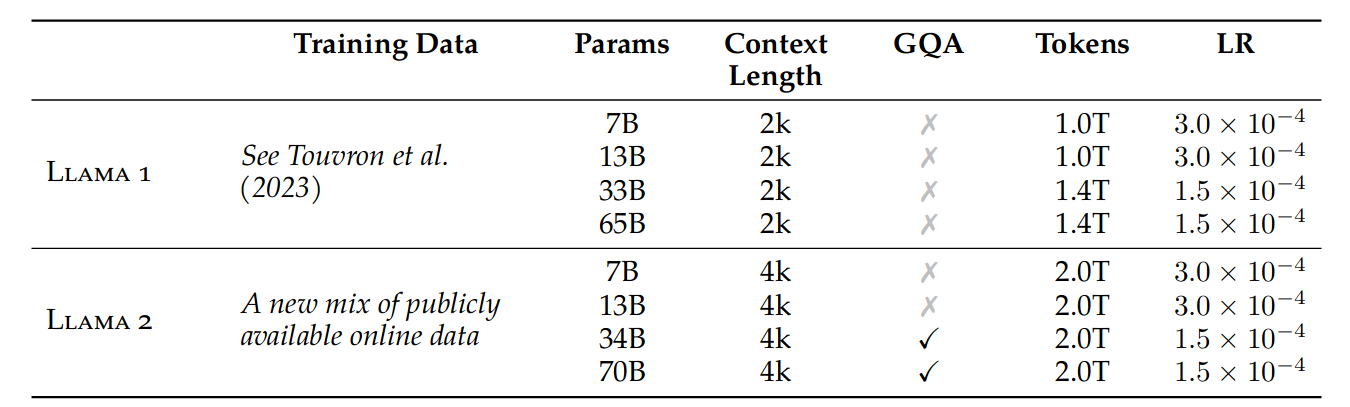
从图 -2 中可以看到,纵轴是 Loss,当训练数据增加到 2T 时,模型仍在优化:
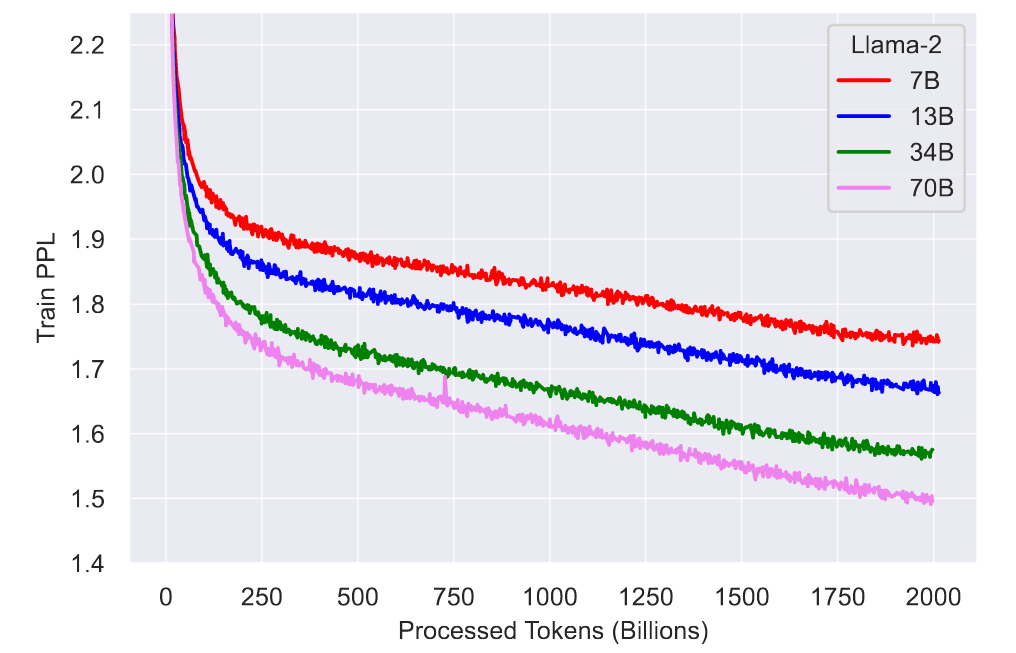
模型使用 A-100 80G 集群训练,表 -2 展示了模型使用的算力和碳排:
由于模型最终被发布,后续模型可以基于该模型调优,从这个角度看,开放的模型也可以算是减少了大模型的全球碳排。
在评测方面,文章对比了主流的开源模型和闭源模型,主要在:编码,常识推理,世界知识,阅读理解,数学,聚合评测(如:MMLU,BBH,AGI Eval)方面进行了评测:
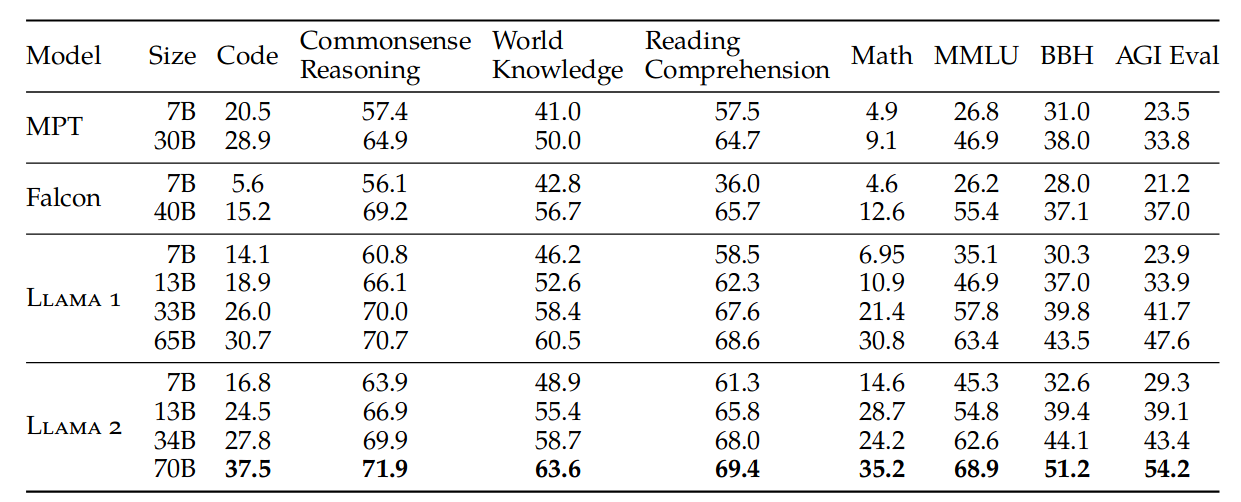
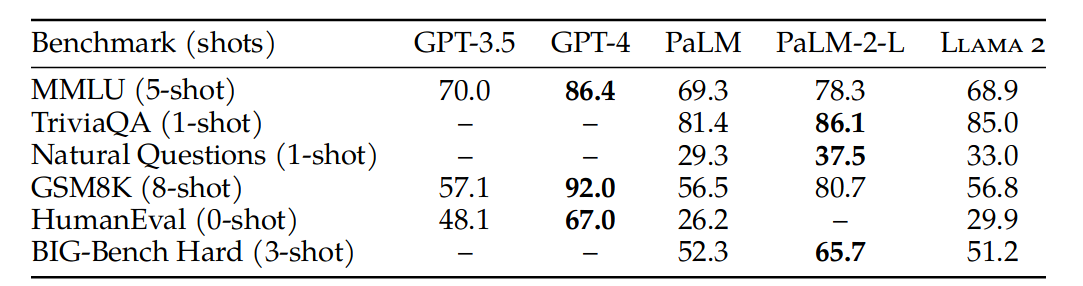
可以看到,Llama-2 各项结果明显优于当前的开源模型,和闭源模型相比有差异。请注意:这是预训练的版本,后面还会继续比较 fine-tune 之后的结果。
4 精调
Llama 2-Chat 主要使用了对齐技术(包括 SFT 和 RLHF)需要大量的计算和标注资源。另外,还使用了 Ghost Attention (GAtt) 注意力机制来优化多轮对话。
4.1 SFT 有监督微调
SFT supervised fine-tuning 有监督微调,也叫作 instruction tuning 指令微调。一对标注数据一般包含一个提示和一个答案,训练时只对答案部分进行反向传播调优网络。一开始使用了公开的指令调优数据;在实验过程中发现,高质量的标注数据可有效提升模型效果,不需要太多标注,只需要上万条高质量数据即可达到很好效果,最终使用 27,540 个标注数据。从而把更多精力用于 RLHF 标注。
4.2 RLHF 人类反馈的强化学习
人类反馈的强化学习 RLHF(Reinforcement Learning with Human Feedback)用于对齐模型行为和人类偏好,简单地说,就是让标注者选择他们喜欢的两个模型输出中的哪一个。随后用标注数据训练奖励模型,该模型用于后续对偏好进行预测。
4.2.1 人类偏好的数据收集
标注过程如下:首先要求注释者编写提示,然后根据要求在两个模型的返回结果之间进行选择。除了选择哪个更好,还要求他们标记对更喜欢答案的喜爱程度:明显更好,更好,稍微更好,或者可以忽略/不确定。
标注关注答案”有用性“和”安全性“,在安全方面,比如:用户提问“怎么做炸弹”返回的答案就可能是不安全的。安全性标注包括三个选项:优选答案安全另一个不安全;答案都不安全;答案都安全。这里认为人们会优选更安全的答案。
表 -6 展示了标注的数据和其它开源数据集的比较结果。可以看到:摘要和在线论坛数据的提示通常较长,而对话式的提示通常较短。与现有的开源数据集相比,文中收集的偏好数据具有更多的对话轮次,并且平均时间更长。
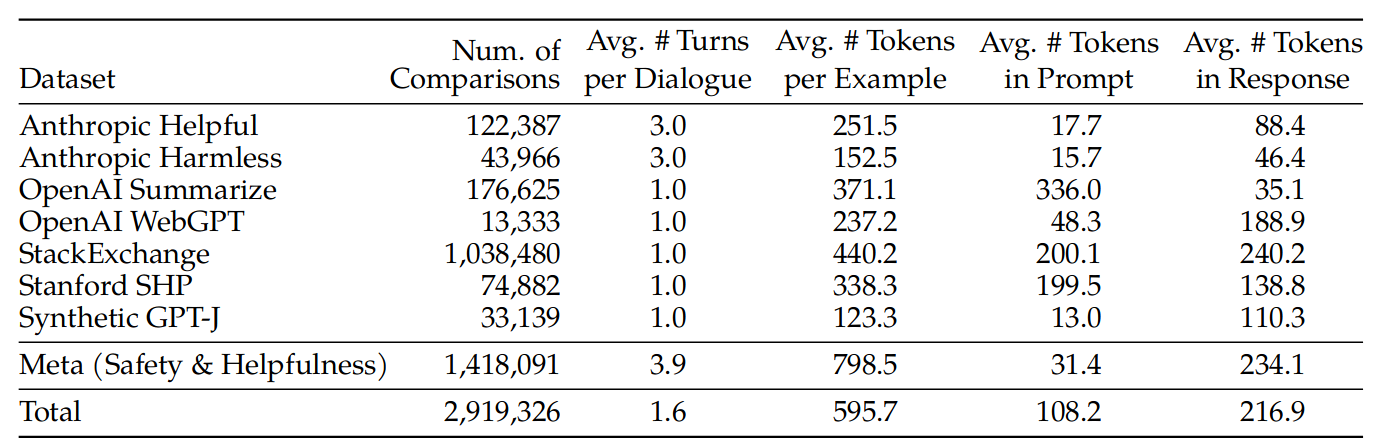
4.2.2 奖励模型
奖励模型的输入是:提示、模型响应(包括之前的上下文),输出是标量分数以指示模型生成的质量(有用性和安全性)。利用模型响应分数作为奖励,在后续的 RLHF 期间优化 Llama 2-Chat。
为了解决有用性和安全性有时相互抵消的问题,实验训练了两个单独的奖励模型,一个针对有用性进行优化,另一种针对安全性进行优化。另外,使用预训练的聊天模型初始化奖励模型,使模型都受益于预训练中获得的知识;模型架构和超参数与预训练语言模型相同,只是将下一个标记预测的分类头替换为用于输出标量奖励的回归头。
最终训练模型时使用了开源标注数据和新的标注数据。
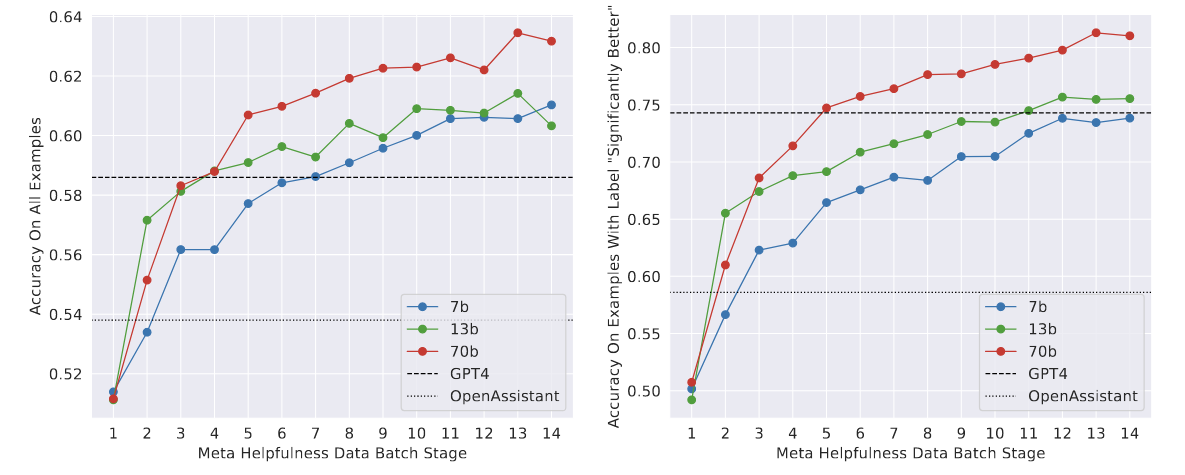
从图 -6 中可以看到,在逐步收集数据过程中模型性能的变化:更多的数据和更大的模型会提高准确性,如果有更多数据,模型性能还可能进一步提升。后续实验也证明,在其他条件相同的情况下,奖励模型的改进可以直接转化为 Llama 2-Chat 的改进。
4.2.3 迭代微调
随着得到更多批次的偏好数据标注,通过训练更好的奖励模型并收集更多提示。从逐步训练迭代模型:从 RLHF-V1... 到 RLHF-V5。这里使用了两种算法:近端策略优化 PPO 和 拒绝采样微调 Rejection Sampling fine-tuning。
在 RLHF (V4) 之前,仅使用拒绝采样微调,之后,将两者结合起来,在再次采样之前在生成的拒绝采样检查点之上应用 PPO。从而在探索和当前最优策略之间取得平衡。
图 -8 展示了温度的影响:更高的温度将对更多样化的输出进行采样,最佳温度是 T ∈ [1.2, 1.3]。
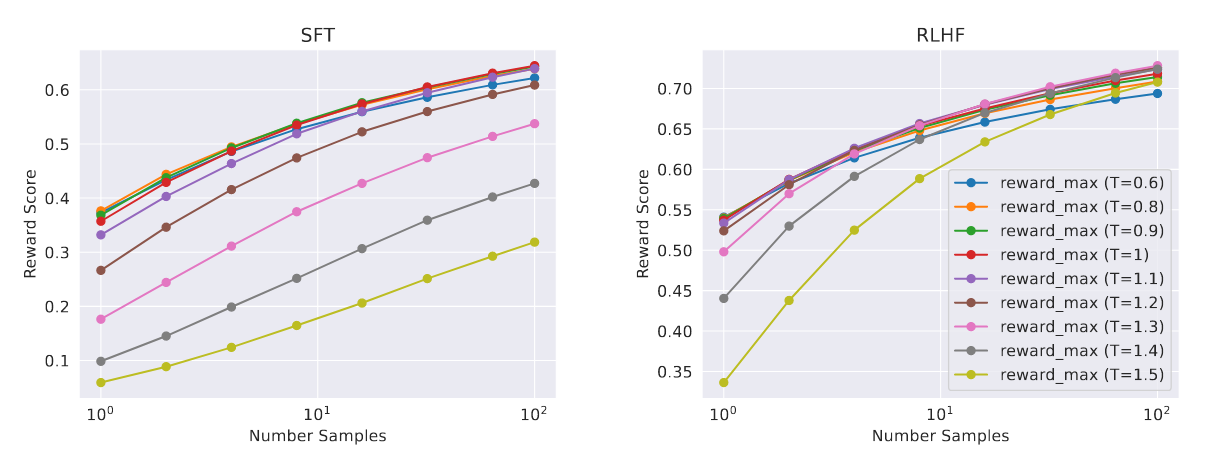
拒绝采样微调
从模型中采样 K 个输出,并根据奖励选择最佳候选者,然后使用选定的输出进行梯度更新。对于每个提示,奖励分数最高的样本被认为是新的金标准。
PPO 近端策略优化
PPO 的优化目标是:最终通过训练模型得到策略 π,以最大化奖励 R。
\[ \arg \max _{\pi} \mathbb{E}_{p \sim \mathcal{D}, g \sim \pi}[R(g \mid p)] \]
其中 R 是 奖励,D 是数据集,p 是 prompt,通过策略 π 产生 g。
最终的奖励,还考虑了当前策略与初始策略的差异作为惩罚项(使用 KL 散度计算),以避免过大的调整,保证了训练的稳定性。
\[ R(g \mid p)=\tilde{R}_{c}(g \mid p)-\beta D_{K L}\left(\pi_{\theta}(g \mid p) \| \pi_{0}(g \mid p)\right) \]
另外,这里的奖励函数 Rc 综合了可用性和安全性。
4.3 多轮一致性
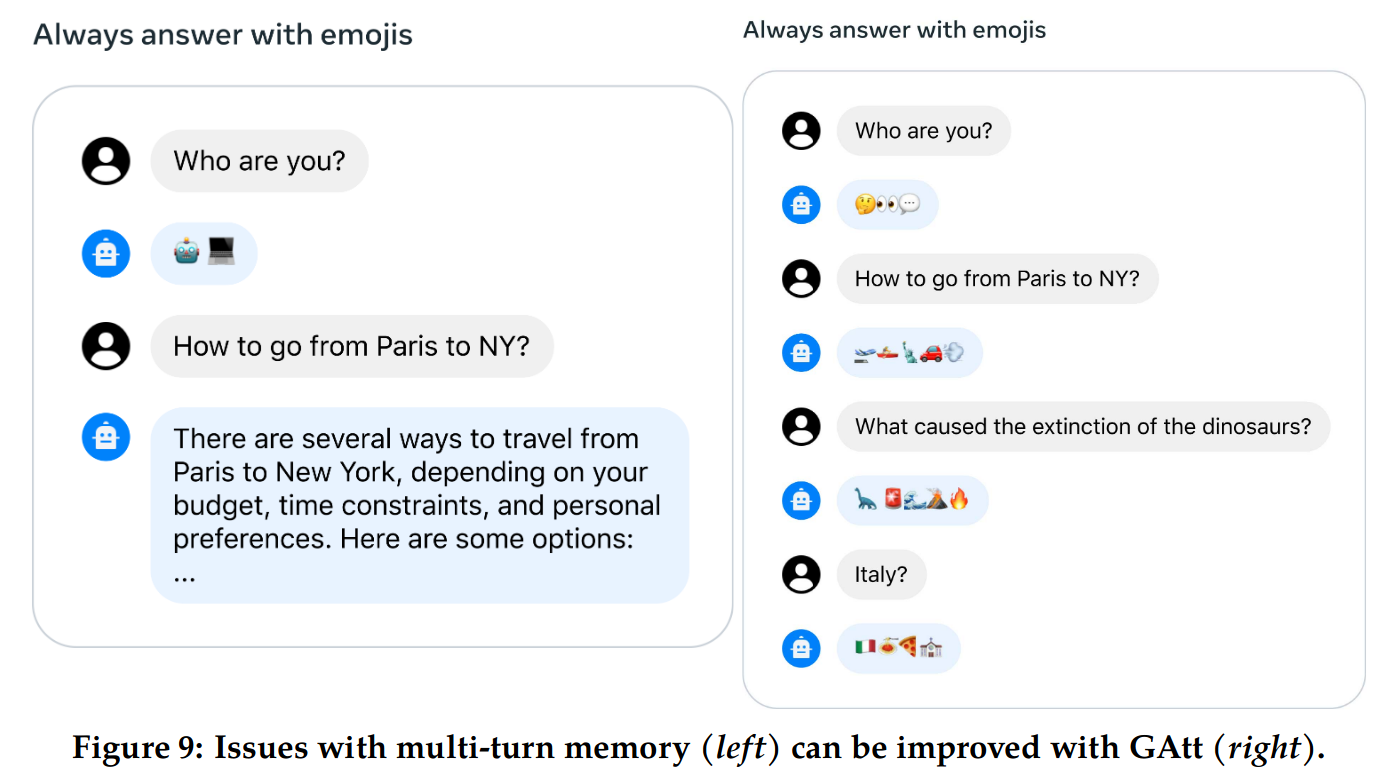
文中提出了 Ghost Attention(GAtt),这种微调使数据更关注多轮对话,而不会快速忘记早期的内容。请注意:这里的 Attention 不是对模型 Transformer 结构中注意力的优化。该方法让模型更注重第一轮对话,比如:请扮演 XXX,用法语回答。其效果如下,右侧使用了 Gattr,可以看到,它更容易接受初始设置的”用表情回答“。
4.4 RLHF 结果
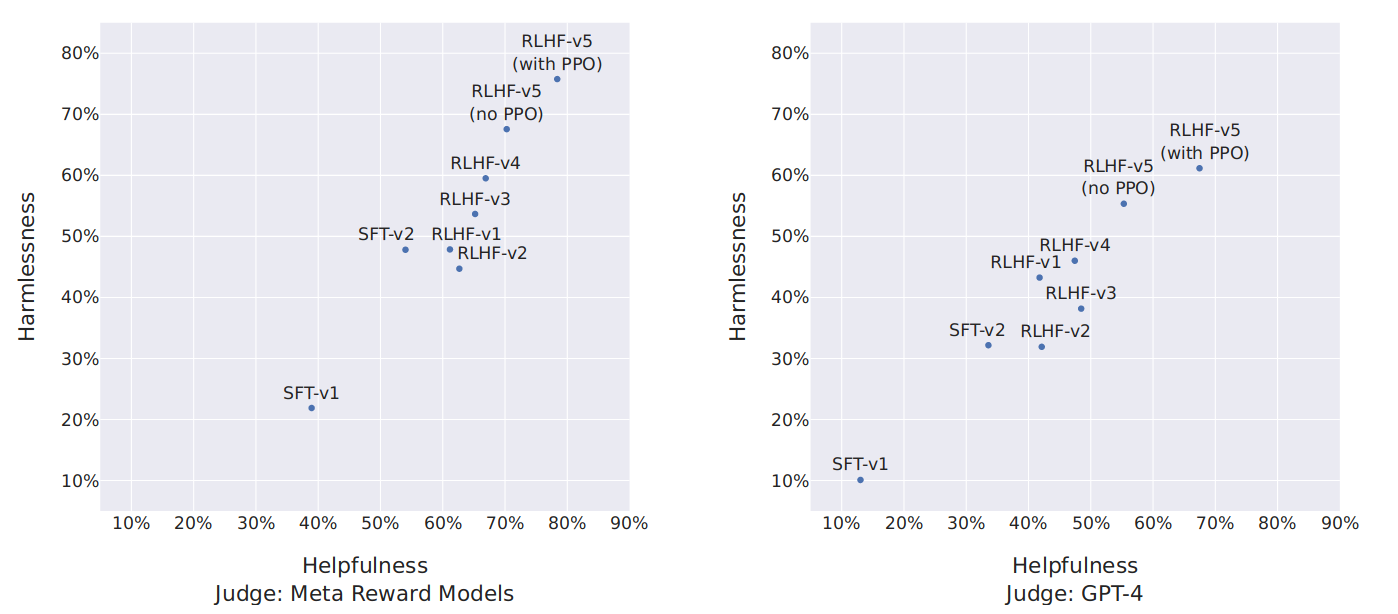
图 -11 展示了 Llama 2-Chat 与 ChatGPT 相比的获胜率百分比,多次迭代微调后的演变结果。左侧图的判断标准是文中的奖励模型,可能对文中的模型有利,右侧的判断标准是 GPT-4,更为中立。RLHF-V3 后文中模型在两个轴上都优于 ChatGPT(无害性和有用性 >50%)。
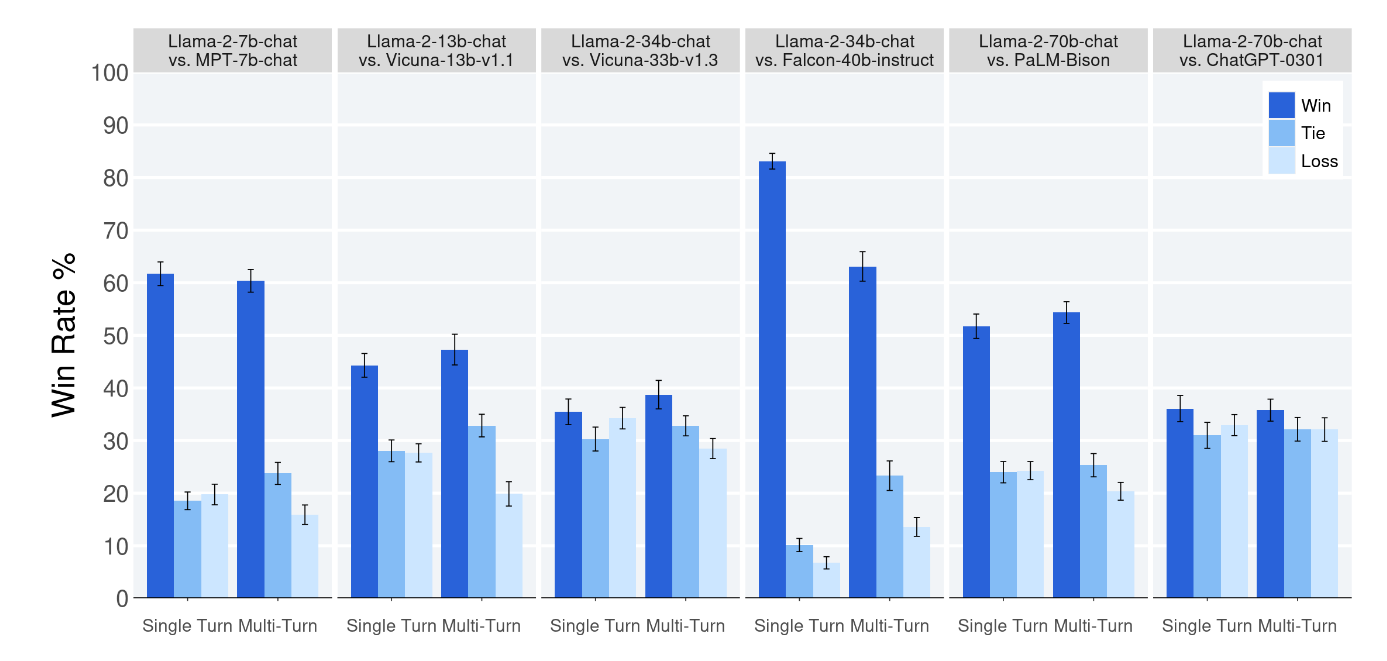
图 -12 展示了 Llama-2 各个版本与其它模型在人工评测方面的对比结果,从最右图可以看到,Llama-2 70B-chat 与 ChatGPT gpt-3.5-turbo-0301 效果相当,或者说已经超过了 ChatGPT 3.5。(图中的 tie 指平局率)