论文阅读_ICD编码_MSATT-KG
介绍
英文题目:EHR Coding with Multi-scale Feature Attention and Structured Knowledge Graph Propagation
中文题目:基于多尺度特征关注和结构化知识图传播的 EHR 编码
论文地址:https://sci-hubtw.hkvisa.net/10.1145/3357384.3357897
领域:自然语言处理,生物医疗,ICD 编码
发表时间:2019
作者:Xiancheng Xie 等,复旦大学
出处:ACM CIKM
被引量:25
阅读时间:2022.06.16
读后感
很好地结合了现有的资源和方法:利用编码的内在关系,结合了注意力机制,知识图谱,密连接网络等方法。
泛读
- 针对问题:ICD 自动编码
- 核心方法:
- 通过对每个词上下文邻居的 n-gram,选择多尺度特征
- 利用 ICD 标签的语义:编码越相近,含义越相近,利用图卷积网络捕捉 ICD 编码的层次关系和语义
- 基于 ICD 标签的注意力;结合多尺度特征,用注意力选择信息量最大的 n-gram 特征
- 理解程度:
- 一个半小时精读,又花了约两小时整理成文。
方法
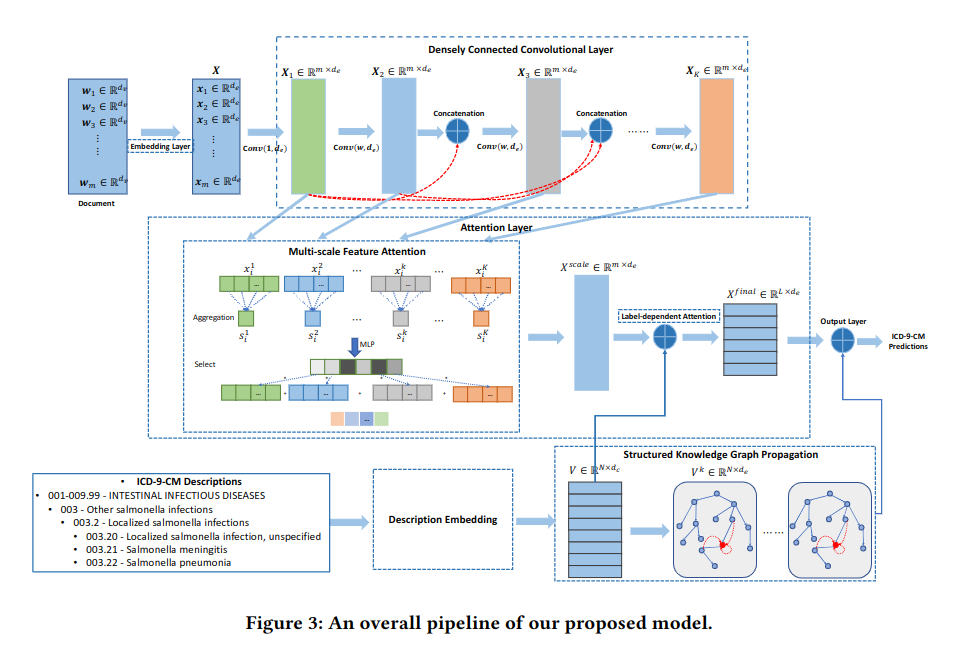
概览
论文将问题定义为多标签分类问题。方法由三部分组成:
- 提取多尺度特征(图上)
- 两层注意力机制更好地计算输入文本的表征(图中)
- 用知识图谱迭代计算 ICD 表征(图下)
符号定义
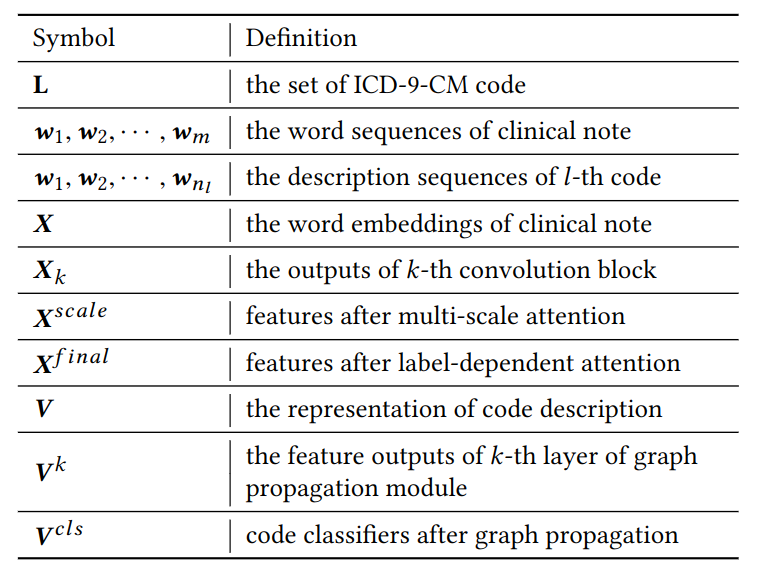
其它符号:m 表示医生输入串的长度,n 表示 ICD 编码描述文本的长度,d 表示维度。
嵌入层
用 X 表示词嵌入,利用 word2vec 的连续词袋 (CBOW) 对训练集中的所有文本进行预训练,词嵌入大小为 100,窗口为 5,5 次迭代。
密连接卷积层
CNN 由 K 个卷积块通过密连接堆叠而成,用 Xk 表示第 k 个卷积块的输出,Xk 计算方法如下:
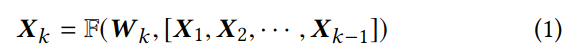
其中中括号表示串联,Xk 由前 k-1 层输出串联 (图中红线) 后,与参数 W 通过函数 F 计算出 Xk,W 是卷积核。为了保持字符串的长度一致,使用 zero-padding 填充。由于使用了卷积,Xk 可被视为 n-gram 特征,通过卷积逐层抽象;再用 concat 将各层抽象连接起来,生成了多尺度特征。
注意力层
多尺度特征注意力
如图 -3 所示,对于每个位置 i,注意力机制根据其 k 个层的特征(k 个尺度/k-gram)计算权重分布。步骤包括聚合和筛选。
聚合:用 s 作为 xi 在第 k 层的表示,它聚合了各个维度:

然后,计算注意力权重,用于选择携带信息最多的尺度:
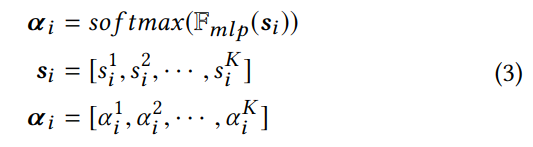
函数 F 是一个多层感知机,上式计算了每一层 (1~k) 的权重。
再用各种权重给各层的输出加权:
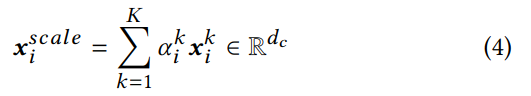
最终通过串联,产生了所有位置加权后的 Xscale:
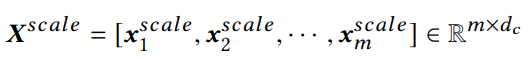
它将被传入下一个 attention 层。
ICD 标签注意力
在文本分类任务中,一般使用平均池化或最大池化处理各维度。针对多标签任务,不同 ICD 编码可能关注不同局部文本,因此,使用基于 ICD 标签的注意力来选择最相关的短语。对于每个标签,使用了线性池化:
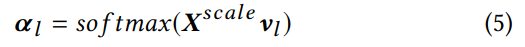
不同的标签记作 l,vl 是标签的向量表示,这里的注意力 a 用于计算基于标签的输入文本的向量表示:
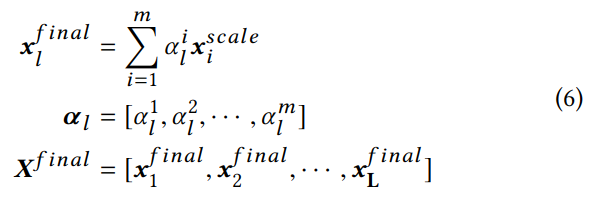
知识图迭代
加入知识图是为了引入 ICD 编码之间的层级关系和相关性。如果只使用 ICD 编码,对于每种编码都需要一些实例参与训练,论文使用了 ICD 编码 ID 对应的描述文本,句中各词记作{w1,w2,...wn}。
标签向量 v 的计算方法如下:
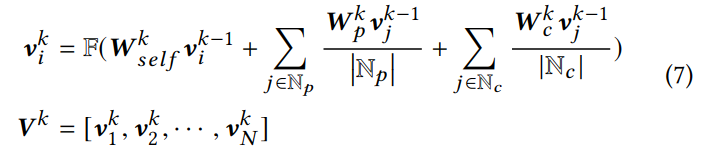
先计算标签描述文本中的每个位置 i,结合其自身 self,其父类 p 和子类 c,在上一次迭代时的表示,分别加权计算当前的表示,F 为激活函数。各个节点的初值是通过训练数据训练出来的自然语言模型得到的。
输出层
输出层结合了 X 和 V,利用 sigmod 计算出对应各个 ICD 编码的概率。
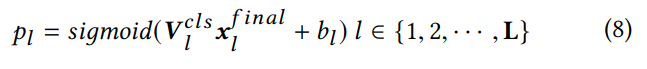
计算出的 Pl 是概率值,常见的方法是使用阈值 0.5 来判别类别标签的是与否。而训练集中的每个类别,负例明显多于正例,使其结果偏向负例。为了优化阈值,使用了回归方法:
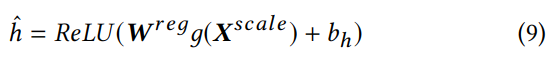
使用该方法后,阈值也是拟合出来的。其中 g 为最大池化,用于生成文本的全局表征,W 是回归参数。
最终的损失函数结合了 (8) 和 (9) 的误差:

其中λ是权重,用于调整二者的比例。