论文阅读_Visual_ChatGPT
name_ch: Visual Chatgpt:使用可视化基础模型进行交谈、绘图和编辑
name_en: Visual ChatGPT:Talking, Drawing and Editing with Visual Foundation Models
paper_addr: http://arxiv.org/abs/2303.04671
code: https://github.com/microsoft/visual-chatgpt
date_publish: 2023-03-08
读后感
在 ChatGPT 和图像构建方法间做了桥接,和其它模型相比,除了利用大语言模型中的知识,还利用了 ChatGPT 强化学习带来的能力,是一个结合已有技术的一个优雅示例。
本文将 CoT 的潜力扩展到大规模任务,包括但不限于文本生成高清图像、图像到图像的翻译、图像到文本的生成等。CoT 指的是 Chain-of-Thought 思想链,主要指模型的多步推理能力,以解决更为复杂的问题。
主要对聊天的场景进行优化,在提示上作文章。即:在 ChatGPT 外边包了一层,这也是当前最常见的用法。文章偏工程化的具体实现。
介绍
主要实现:
- 不仅发送和接收语言,还发送和接收图像。
- 提供复杂的视觉问题或视觉编辑指令,提供多个 AI 模型的多步骤互动协作。
- 提供反馈并询问对修正结果评价。
提供了如下功能:
- 明确告诉 ChatGPT 和 VFM,并指定输入输出格式;
- 将不同的视觉信息,如 png 图像、深度图像和掩码矩阵转换为语言格式,帮助 ChatGPT 理解;
- 处理不同视觉基础模型的历史、优先级和冲突。
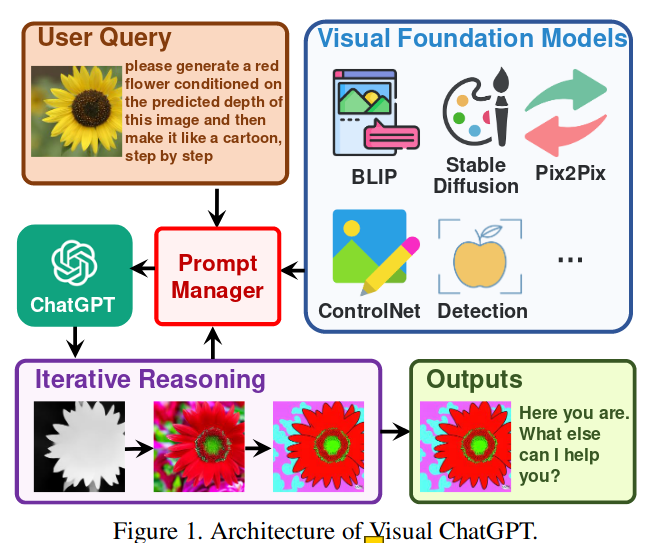
文章贡献:
- 提出了 Visual ChatGPT,打开了 ChatGPT 与视觉基础模型结合的大门,使 ChatGPT 能够处理复杂的视觉任务;
- 设计了一个 Prompt Manager,其中涉及 22 个不同的虚拟功能矩阵,并定义了它们之间的内部关联,以便更好地交互和组合;
- 进行了大量的零样本实验,展示了丰富的案例来验证 Visual ChatGPT 的理解和生成能力。
Visual ChatGPT
全文唯一公式:
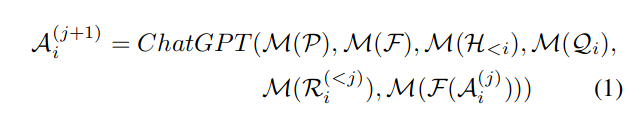
i:i 轮对话
j:解决复杂问题时,回答可能拆解成多步,j 表示每一步
P:系统性提示
F:虚拟函数模块,F={f1,f2,...fN},它包含一组各有输入输出的决策函数。
H:前几轮的对话 s 历史
Q:表示人机对话中第 i 轮对话中的问题,它可以包含图片和文本
R:解决复杂问题时,前 j 个步骤的结果
A:人机对话中第 i 轮对话中的答案,回答支持多种格式混合
M:提示管理器(核心功能),将图像等信息转换成 ChatGPT 能识别的文本;
其核心过程主要分为以下四步:
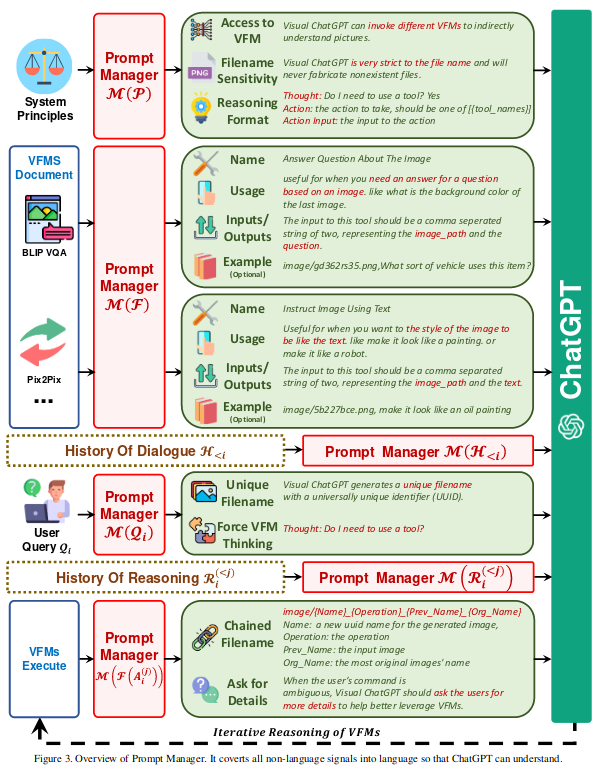
处理系统性提示 M(P)
生成 ChatGPT 能明白的语义
基础模块 M(F)
更好地与图像工具结合,常见的两种应用是:生成/编辑图片,根据图片回答问题。
处理用户输入 M(Qi)
用户输入可能是文本或者图片。
处理输出 M(F(Ai))
处理 VFM 产生的图像,并在 VFM 和 ChatGPT 间交互,最终生成可以反馈给用户的数据。
实验
实验使用 ChatGPT (OpenAI “text-davinci-003” version)。