论文阅读_VLOGGER_图片+声音->生成视频
1 | 英文名称: VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis |

读后感
这是 Google Research 3 月份的一篇论文,主题是条件化视频生成。文中提出了 VLOGGER 模型,一种从图像和音频生成可变长度视频的方法,支持头部运动、凝视、眨眼、嘴唇及手部运动。VLOGGER 基于生成扩散模型,不需要对每个人单独进行培训,也不依赖面部检测和裁剪,能够生成完整的图像(不仅仅是面部或嘴唇),并考虑了广泛的场景(例如可见的躯干或不同的主体身份),这对于正确合成人类交流至关重要。
除了口型以外,面部表情在说话时的动作还与文本内容有关,需要对文本含义进行理解。音频里可能也包含一些信息,以生成带有情绪的视频表达。另外,这里的一个亮点是:可以生成手的动作。从生成图片的经验来看,生成正常的手型几乎是最为复杂的图像生成问题之一。
如果想理解语音所阐释的意义,也可能需要 LLM 的配合,而不仅仅是声音和视频的简单对应关系。从训练数据可以看出,该模型主要使用英语数据进行训练,因此,对其它语言的理解决效果也能没那么好。
摘要
目的:提出一种名为 VLOGGER 的方法,从单张图片生成由音频驱动的高质量人类视频。
方法:使用人类到 3D 动作的扩散模型;引入一种新的扩散架构,结合空间和时间控制。
结果:VLOGGER 在图像质量、身份保留和时间一致性方面优于现有方法,并能生成上半身手势。
1 引言
内容创作、娱乐或游戏等行业对合成人类的需求很高。然而,逼真人类视频的创作仍然很复杂,且已有的人工制品仍不成熟。这需要大量人工干预才能获得实际结果。需要更自然的方式,让人在交互中产生同理心。
交流不仅仅是音频与嘴唇和面部运动的结合——人类通过手势、凝视、眨眼或姿势使用身体进行交流。这在客户服务、远程医疗、教育或人机交互等领域得到了广泛应用。
VLOGGER 由一个基本模型和一个超分辨率扩散模型组成,以获得高质量的视频。为了增加稳健性和概括性,我们策划了一个大规模数据集。在肤色、身体姿势、视点、语音和身体可见性方面,其多样性比以前的数据要大得多。与之前的尝试相比,该数据集还包含带有动态手势的视频,这对于学习人类交流的复杂性非常重要。

2 方法
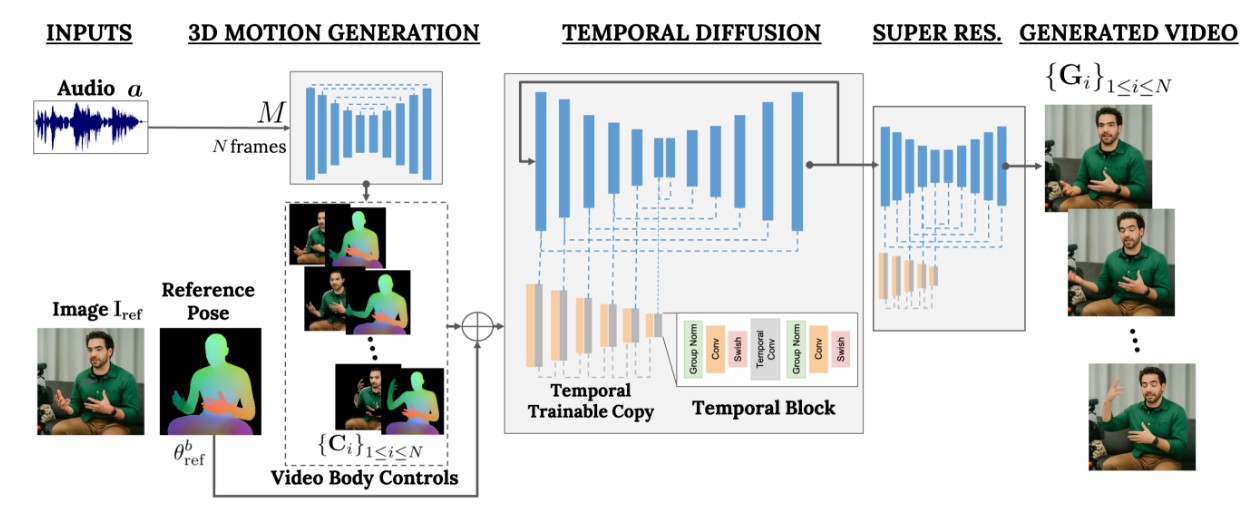
目标是生成一个可变长度的逼真视频,合成一个说话的目标人物,并展示逼真的头部运动和手势。框架称为 VLOGGER,如图 2 所示。VLOGGER 是一个基于随机扩散模型的两阶段流水线,用于将语音转换为视频。
第一个网络以采样率将音频波形作为输入,生成中间的身体运动控制。这些控制负责在目标视频长度上实现凝视、面部表情和 3D 姿势。第二个网络是一个时间 - 图像到图像的转换模型,扩展了大型图像扩散模型。它采用预测的身体控制来生成相应的帧。为了将过程条件设置为特定身份,网络还获取了一个人的参考图像。VLOGGER 在新引入的 MENTOR 数据集上进行了训练。
2.1 音频驱动的运动生成
2.1.1 架构
第一个网络𝑀旨在根据输入语音预测驱动运动。它还考虑通过文本到语音模型的输入文本,将其转换为波形,并将生成的音频表示为标准的 Mel-Spectrograms。𝑀基于 Transformer 架构,在时间维度上有四个多头注意力层。包括帧数和扩散步骤的位置编码,以及输入音频和扩散步骤的嵌入 MLP。在每一帧中,使用因果掩码,使模型只关注前一帧。该模型使用可变长度的视频进行训练,以便能够生成非常长的序列。
通过使用 3D 人体模型,可以生成更具表现力和动态的姿势。模型根据输入音频预测面部和身体参数,生成面部表情和身体姿势变化,以动画化目标人物。在训练和测试中,通过拟合参数化身体模型获取的 3D 形状参数来建模人物身份。采用卷积神经网络架构,将预测的表情和姿势参数用于定位,并将模板顶点位置栅格化为密集表示,以获得密集掩码,同时对身体的语义区域进行栅格化处理。
以往的人脸重现工作常依赖变形图像,但这些在基于扩散的人体动画架构中被忽视了。提出使用变形图像来指导生成过程,有助于保持主体身份。在每帧中,将参考图像中可见的每个身体顶点分配一个像素颜色,并渲染新帧,得到部分变形图像。所有渲染假设全透视相机,从训练视频或参考图像推断视角。有关于示意图,请参见图 2。在下一节中描述时间图像扩散模型,并在附录中详细说明。同时,在实验部分探讨了密集表示和变形图像的使用效果。
2.1.2 损失函数
该模型采用扩散框架,逐步向真实样本添加高斯噪声,同时将音频输入作为条件。目标是通过训练去噪网络来预测噪声,从而模拟真实头部和身体的运动分布。在实验中,直接预测真实分布的性能更好。
此外,引入了一个额外的时间损失 Ltemp,用于惩罚连续帧之间的预测差异。使用这两个损失的线性组合来训练完整模型。为了确保头部和手部运动更平滑,同时允许面部表情有更大的动态变化,我们对表情和身体姿势使用了不同的时间损失权重。
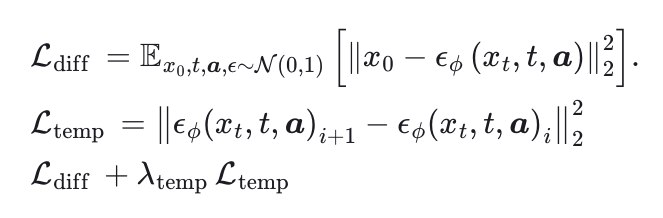
2.2 生成逼真的会说话和移动的人
2.2.1 架构
下一个目标是对输入图像 Iref 进行动画处理,使其遵循之前预测的身体和面部运动。这些运动用不同类型的蒙版 C 表示。基于图像控制的方法上,提出了一种新型时间感知扩散模型。受 ControlNet 启发,将初始训练好的模型冻结,并制作了一个可训练的新副本,这个副本采用输入时间控制。在每个下采样块的一些特定位置加入一维卷积层,如图 2 所示。这个网络通过处理连续帧和控制信号进行训练,并根据这些输入生成参考人物的动画短片。
2.2.2 训练
文中方法使用 MENTOR 数据集进行训练,该数据集包含独特人类主体的全长视频。训练时,网络会获取一系列连续帧和一个人的任意参考图像。理论上,任何视频帧都可以用作参考,但实际上我们选择时间上较远的帧作为参考。因为时间较近的帧会让训练变得简单,降低泛化能力。
网络的训练分为两个阶段:首先在单帧上学习新的控制层,然后通过添加时间组件在视频上进行训练。这种方法可以在第一阶段使用较大的批次大小,加快头部再现任务的学习过程。
2.2.3 损失函数
损失函数类似于第一步的计算,这里主要考虑了图片 I 和控制信息 C 对结果的影响。
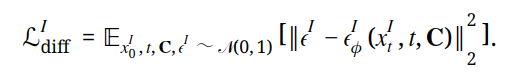
2.2.4 超分辨率(Super Resolution)
以 128×128 分辨率生成基础视频,并使用级联扩散方法扩展时间条件,生成两个超分辨率变体,从而获得 512×512 或 256×256 高质量的视频。
2.2.5 时间外延
这里探讨了时间外延的方法:先生成 N 帧,然后根据之前的帧迭代性地外延生成更少的帧 N'<N。使用 DDPM 来生成每个视频片段,并展示了这种方法可以扩展到数千帧。最终,展示了该网络能够生成逼真且时间上连贯的人类视频。
2.3 MENTOR 数据集
从大型内部视频库中整理 MENTOR 数据集,该数据集包含声音输入,从躯干向上大部分面向镜头,主要用英语交流。视频为 240 fps,24 帧(10 秒剪辑),音频为 16 kHz。
为了模拟全身交流的人类,估计了 3D 身体关节和手部,并通过最小化投影误差和连续帧之间的时间差来拟合一个统计的 3D 身体模型。过滤掉背景变化明显、面部或身体部分检测不完全或估计抖动、手部完全未检测到(比如人在抓握和操作物体时)或音频质量低的视频。这个过程生成了一个超过 800 万秒(2200 小时)和 80 万个身份的训练集,以及 120 小时和约 4000 个身份的测试集,使其成为迄今为止在身份数量和长度上最大的高分辨率数据集。
此外,MENTOR 数据集包含广泛多样的主体(如肤色、年龄)、视角或身体可见性。在附加材料中提供了统计数据,并与现有数据集进行了更广泛的比较。我们计划向更广泛的研究社区发布经过整理的视频 ID、面部拟合和估计的身体姿态。
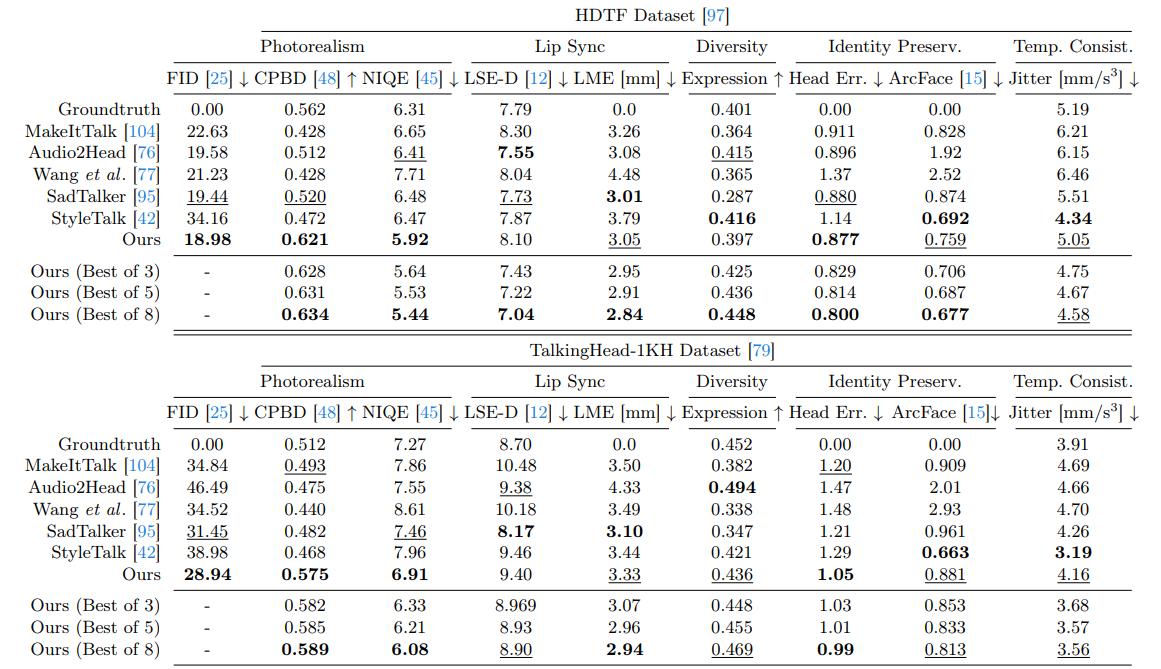
3 实验
使用多种指标来评估生成视频的图像质量、唇同步、时间一致性和身份保持。在图像质量方面,FID 分数衡量真实图像和生成图像之间的距离,CPBD 和 NIQE 验证生成图像的质量。在唇同步质量方面,通过估算面部标志点坐标并报告嘴部顶点位置差异(LME),同时报告 LSE-D 分数。报告抖动误差来衡量生成视频的时间平滑度。