论文阅读_扩散模型_SDXL
1 | 英文名称: SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis |
1 读后感
SD 是语言引导的扩散模型。SDXL 是 2023 年 7 月 Stable Diffusion 新发的大模型框架,它是潜在扩散模型(LDM)扩展。其主要效果是:加强了画面细腻度,优化了构图,以及对语言的理解能力。
我对比了 SD 1.5 和 SDXL 模型,感觉速度差不太多,个人感觉:图片质量,对文字的理解略有提升,可能因为目前 SDXL 的基模比较少,用的还不太多。个人理解,目前阶段,无论是 AI 写作,绘画还是编程,都需要与人和其它工具深度结合,远不到可以独立解决问题,自动生成最终成果的阶段,但确实能提升效率和效果。
这篇文章没有使用一般的技术论文结构,他将相关工作,方法,实验都写到了第二部分,具体方法也没做太多展开;限制和展示分别写在了正文和附录中。
2 研究背景和动机
视觉创作领域的一个主要问题是,虽然黑盒模型通常被认为是最先进的,但其架构的不透明性阻碍了对其性能的评估和验证。缺乏透明度阻碍了复现,抑制了创新,并阻止社区在这些模型的基础上进一步推动科学和艺术的进步。而本文提出了 SDXL 开源模型,显著提高了 SD 的性能,可与最先进的图像生成器相媲美的合成结果。
具体方法是:
- SDXL 使用了之前三倍大的 U-Net 作为主干网络,增加的参数包括:引入第二个文本编码器,更多的注意力块和更大的交叉注意力上下文。
- 增加两种调节技术,在多种大小和长宽比上优化模型训练。
- 增加了基于扩散的 refine 模块,应用于去噪过程,提高了生成样本的视觉保真度。
3 方法
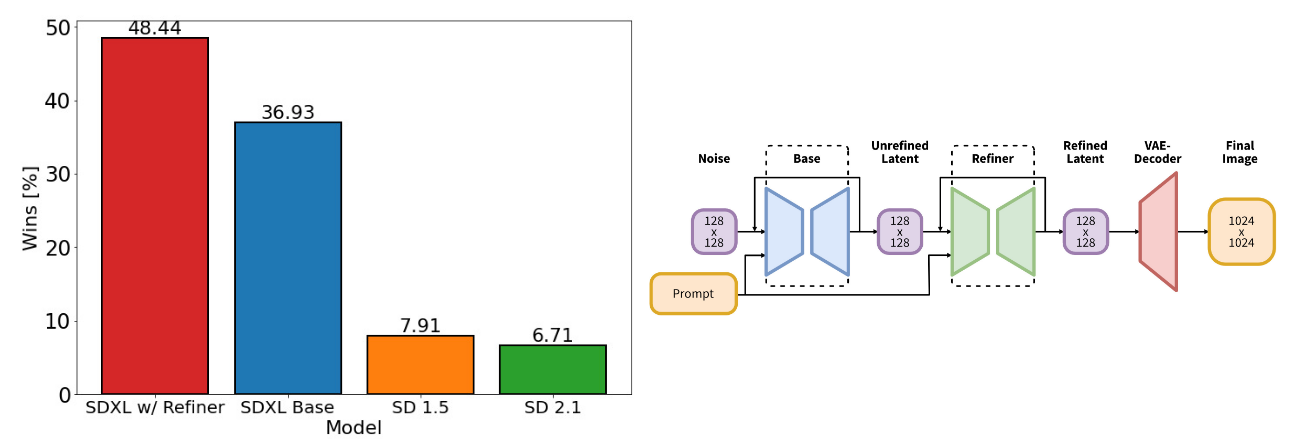
3.1 架构与规模
U-Net 是当前扩散模型的主流架构,SDXL 把 U-Net 网络扩展到之前的三倍大小,具体参数如表 -1 所示:

将 Transformer 的大部分计算转移到 UNet 中的较低级别特征,以提升效率。结构上:省略了最高特征级别的 Transformer 块,在较低级别使用 2 和 10 个块,并完全删除 UNet 中的最低级别(8×下采样)。
另外,还选择了更为强大的文本编码器,文本编码器的参数总大小为 817M。除了使用交叉注意力根据文本输入来调节模型之外,还根据 OpenCLIP 模型的池化文本嵌入来调节模型。
3.2 微调节
3.2.1 根据图像大小微调
LDM 由于其两阶段结构,训练模型需要最小的图像尺寸。一般有两种主流方法,一种是丢弃小分辨率图片(如<512 像素);另一种方式是上采样。
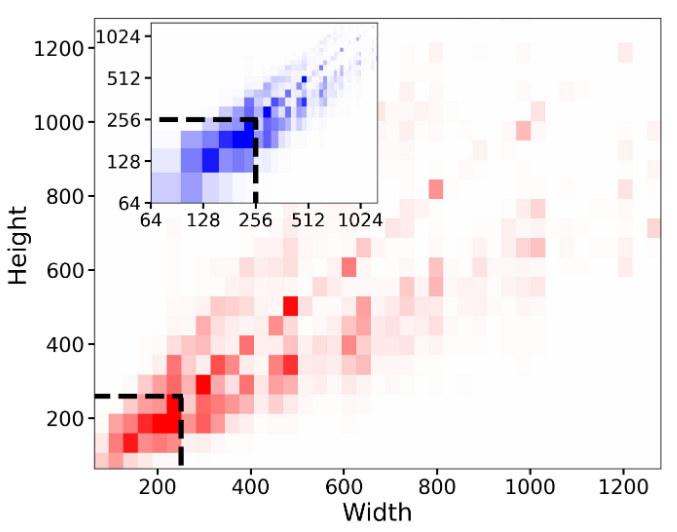
如图所示,在预训练的数据集中,小于 256 的图像占 39%,如果将之丢弃,可能影响模型性能和泛化,而对太多图片上采样可能使生成的图片变得模糊。
文中提出的方法是:根据原始图像分辨率来调节 UNet 模型,将图像的原始宽高,csize = (horiginal, woriginal) 作为模型的附加条件。每个组件使用傅立叶特征编码独立嵌入,这些编码连接成向量,将其添加到时间步嵌入以输入模型。推理时,传入待生成图片的宽高,模型将学会参考 csize 生成图像。
具体实验用 ImageNet 数据训练三个 LDM 模型,将图像大小限制为 512x512。
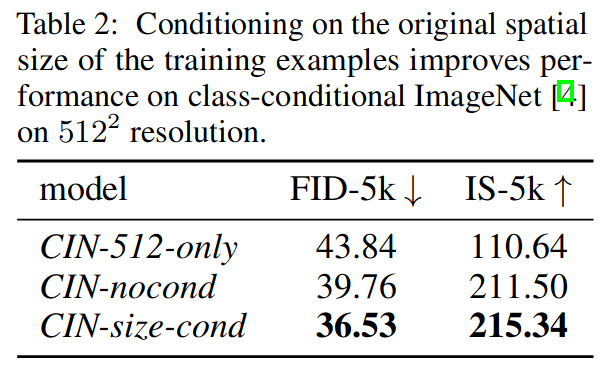
CIN-512-only 去掉了 512 以下的图片,CIN-nocond 使用所有图片但未做处理,CIN-size-cond 将图像大小传入模型。实验结果说明,对于小数据量训练,csize 确实提升了效果。
3.2.2 根据裁剪参数调节

图 -4 展示了 SD 之前版本的另一个常见问题,构图不对,这是由于 Pytorch 要求输入大小相同的数据,而训练数据中图片长宽比不同。一般处理方法是先缩放,再随机从其长边剪切图像再训练。
文中提出的方法与处理大小的方法类似,将裁剪坐标 ctop 和 cleft 进行统一采样,并通过傅里叶特征嵌入,将它们作为条件参数输入到模型中。推理时,将 ctop, cleft 设为 0。
3.3 多尺度训练
一般生成的图像都为 512x512,1024x1024,而实际的需求往往不是这样的。为解决这一问题,文中将数据划分为不同纵横比的桶,将像素数尽可能保持接近 1024x1024 像素。
在优化过程中,每个 batch 由同一存储桶的图像组成,在每个训练步骤的存储桶大小之间交替。此外,模型接收桶大小作为条件,表示为整数元组 car = (htgt, wtgt),并将其嵌入到傅立叶空间中。
3.4 改进自编码器
通过改进自编码器来改善生成图像中的局部细节。文中调整 batch size(256 vs 9)训练自编码器,另外使用指数移动平均值跟踪权重。新的自编码器在所有评估的重建指标中都优于原始模型。
3.5 Refine 阶段
右图使用了 Refine 模块,可以看到更多细节,这种方法有效提升了局部细节效果(如背景/人脸细节)。

具体方法是:在同一潜在空间中训练一个单独的 LDM,该 LDM 专门用于高质量、高分辨率数据,并采用 SDEdit 在基础模型的样本上引入 加噪 - 去噪 过程。在推理时,从基础 SDXL 渲染潜变量,并使用相同的文本输入,通过细化模型直接在潜空间中对它们进行扩散和去噪。其用户评价效果与其它模型对比,如图 -1 的左侧所示。
4 限制和展望
4.1 展望
- 当前模型为两阶段模型,之后倾向于变为单阶段模型。
- 文本理解力有待进一步提升。
- 结构上,之后更倾向于大规模 Transformer 框架。
- 模型增大加大了推理成本,未来将侧重于减少推理所需的计算量。
- 目前使用离散时间方法,后将尝试连续时间方法,以提高采样灵活性,并且不需要噪声时间校正。
4.2 限制
(附录 B)
- 模型在合成复杂的结构时可能会遇到挑战,例如人手,其原因可能是手类物体出现的差异非常大,模型很难提取真实 3D 形状和物理限制的知识。
- 模型生成的图像没有达到完美的照片真实感。例如微妙的灯光效果或微小的纹理变化。
- 模型由数据训练而成,可能包含一些社会和种族偏见。
- 多个对象或主题下的“概念出血”现象:不同视觉元素的意外合并或重叠。比如“蓝色帽子”和“红色手套”,生成时变成了蓝色手套和红色帽子。这是由于文本编码器无法绑定正确的属性和对象造成的。另外,渲染长文本时也会遇到困难。
5 实际使用
5.1 模型下载
- 文生图: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
- 图生图: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0
5.2 速度测试
- SDXL 生成一张 512x512 图 10-20s 左右
5.3 其它
- SDXL 提示词 https://zhuanlan.zhihu.com/p/646828832
- 需要把提示词写得特别清晰,如果不指定风格,常是简笔画风格。
- 之前的模型有的模型很有自己的风格,这不是普适的模型能做到的。
- refiner 模型:挺喜欢它的细节的,尤其是物体和风景,简直就和相片一样,且有艺术感。
- 关键词:
- 加更多细节:a detailed painting