论文阅读_Chinchilla
name_ch: 训练计算优化的大型语言模型
name_en: Training Compute-Optimal Large Language Models
paper_addr: http://arxiv.org/abs/2203.15556
date_publish: 2022-03-29
读后感
针对训练数据量,模型参数量,以及数据训练量,通过实验,得出一些结论:更长的训练时间,更多 token,能提升模型效果;大模型的参数量和性能之间存在幂律分布;训练时 token 越多,模型效果越好,作者认为模型的大小与训练 token 量应等比增加。
换言之:不应该太过纠结于拟合当前的知识和存储量,更重要的是扩展知识面,另外应该多“思考”。
摘要
现在大模型严重训练不足。通过大量实验发现对于模型的每加倍 size 训练令牌的数量也应该加倍。Chinchilla 使用更少的计算来进行微调和推理,极大地促进了下游应用。
介绍
可以看到,相对当时其它模型,Chinchilla 使用了更多的 token 和更少的模型参数。

文中主要讨论了,在运算量固定的情况下,如何选择参数和 token 量的配比,使损失函数最小。
通过在 5 到 5000 亿个标记上训练 400 多个语言模型,范围从 7000 万到超过 160 亿个参数。如图 -1 所示:
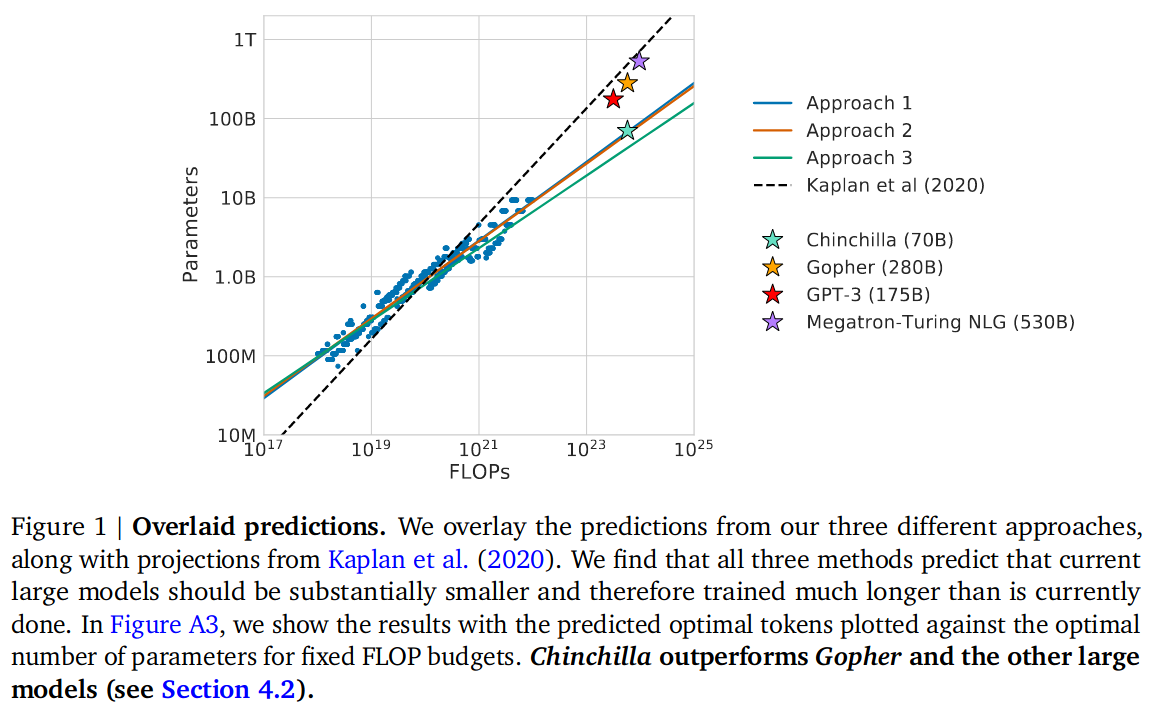
文中介绍 Chinchilla 模型是对 Gopher 的调整,将模型大小变为其 1/4,token 变为其 4 倍,与 Gopher 计算量基本一致。它不仅效果更好,还减少了模型规模,使其能在更低成本的硬件上运行。
方法
从图 -2 中可以看到 token 量,参数量和运算量的相互关系:
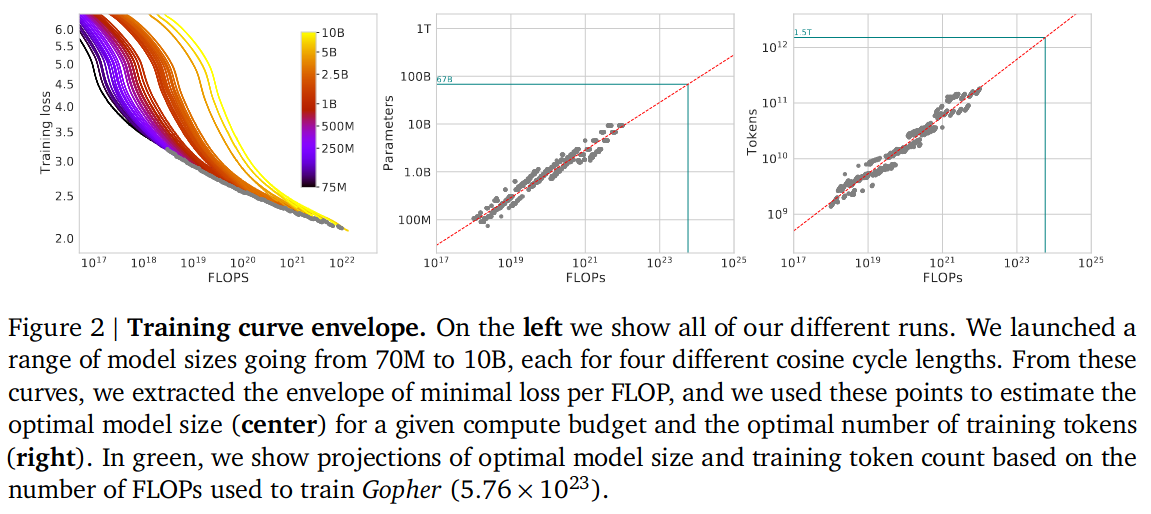
实验尝试了使用不同大小的训练数据,不同参数量,以及把参数量和数据规模加入 Loss 的惩罚,经过大量实验(论文第三部分),得出以下结论:
随着计算预算的增加,模型大小和训练数据量应该以大致相等的比例增加。
图 -3 展示了不同参数对应的估计训练数据量(后面的模型可以参考这个量):
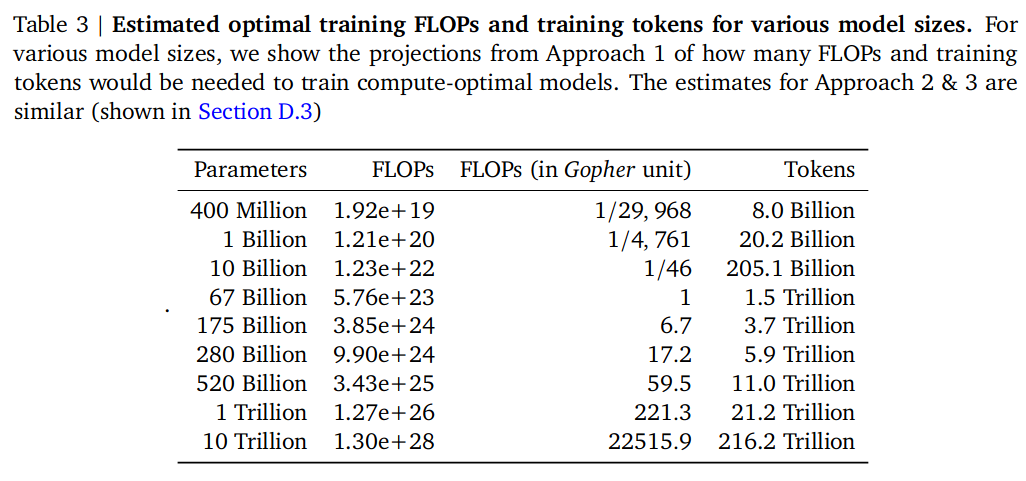
Chinchilla 模型
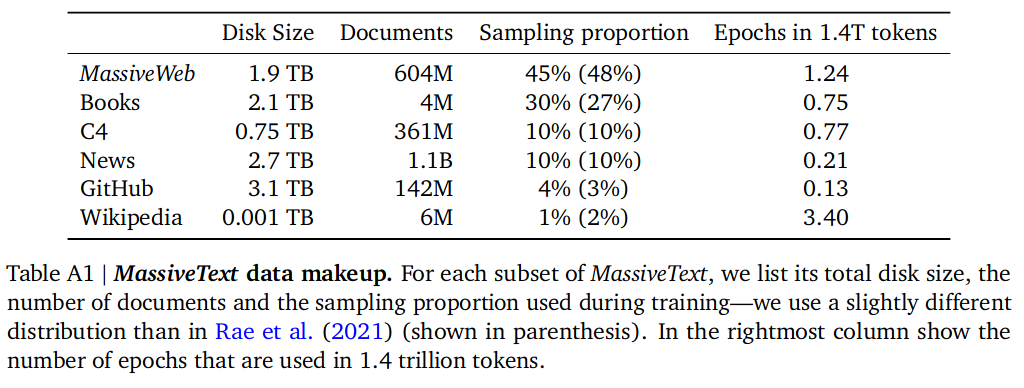
训练数据
模型结构

实验
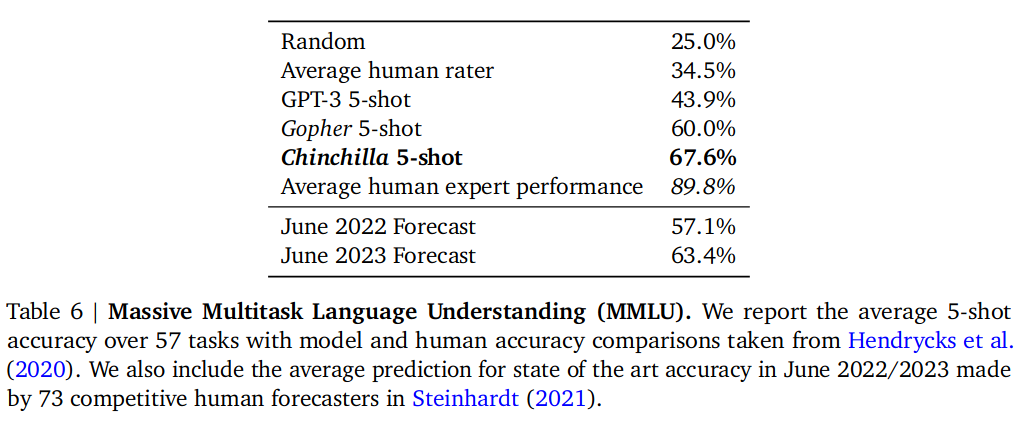
实验在阅读理解,问答,常识,MMLU 等多个测试集中评测,效果是 Chinchilla 在绝大多数情况都优于其基础模型 Gopher,其中MMLU对比效果如下(其它详见正文),对于其中几个子项(高中政治,国际法,社会学,美国外交政策)评测效果高于其它所有模型:
收获
- 延伸阅读:Scaling laws for neural language models,被本篇引用了 23 次。
- FLOP 是一种衡量模型计算量的指标,全称为 Floating Point Operations,即浮点运算次数。在 NLP 中,FLOP budgets 是指模型的计算量预算。