论文阅读_参数微调_P-tuning_v2
1 P-Tuning
1 | 英文名称: GPT Understands, Too |
目标:大模型的 Prompt 构造方式严重影响下游任务的效果。离散化的 token 的搜索出来的结果可能并不是最优的,导致性能不稳定。本篇论文旨在探讨,如何提升预训练语言模型进行自然语言提示的有效性。
方法:作者提出了 P-Tuning,设计了一种连续可微的 virtual token(同 Prefix-Tuning 类似)。将 Prompt 转换为可以学习的 Embedding 层,用 MLP+LSTM 的方式来对 Prompt Embedding 进行处理。
结论:弥合 GPT 和 NLU 应用程序之间的差距 (2021 年),P 调参后的 GPT 可以比在 NLU 调参的类似大小的 BERT 效果更好。
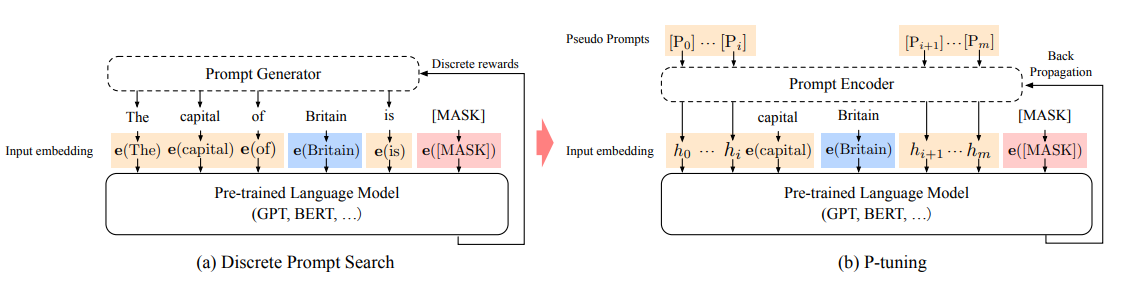
主图:一个关于“英国的首都是 [MASK]”的提示搜索的例子。在蓝色区域表示上下文(“英国”),红色区域表示目标(“[MASK]”),橙色区域表示提示。在(a)中,提示生成器只接收离散的奖励;在(b)中,连续的提示嵌入和提示编码器可以通过可微的方式进行优化。
2 P-Tuning v2
1 | 英文名称: P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks |
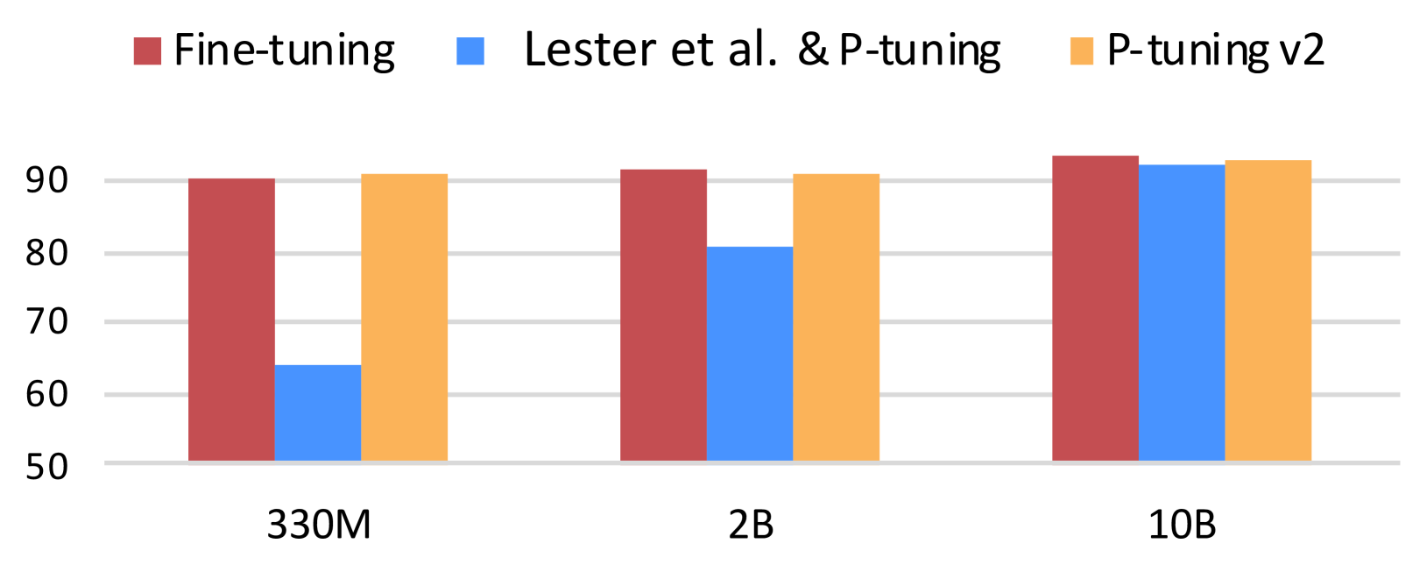
目标:研究的目的是探索如何通过优化提示调整方法,在各种模型规模和自然语言理解任务中实现普遍有效的目标。
方法:最显著的改进是在预训练模型的每一层应用连续提示,而不仅仅是输入层。深度提示调整增加了连续提示的容量,并缩小了不同设置下微调差距的范围,尤其适用于小型模型和复杂任务。
结论:研究发现,经过适当优化的提示调整方法可以在各种模型规模和自然语言理解任务中达到与微调相当的性能,而只需调整 0.1%-3% 的参数(P-tuning 调整 0.01% 参数)。P-Tuning v2 被认为可以作为微调的替代方法,并为未来研究提供了一个强有力的基准。
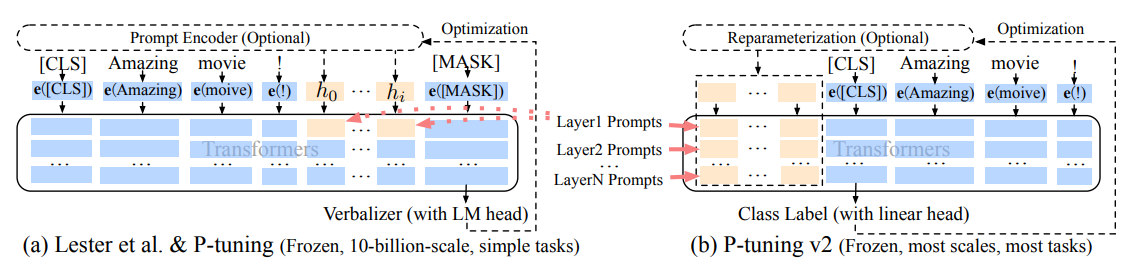
主图:P-tuning 到 P-tuning v2 对比。橙色块(即 h0,…,hi)指的是可训练的提示嵌入;蓝色块是由冻结的预训练语言模型存储或计算的嵌入。
3 实际使用
- ChatGLM-6B 62 亿参数;
- INT4 量化级别下最低只需 6GB 显存即可运行;
- INT4 量化级别下最低只需 7GB 显存即可 p-tuning v2 微调;
