论文阅读_VideoReTalking
1 | 英文名称: VideoReTalking: Audio-based Lip Synchronization for Talking Head Video Editing In the Wild |

读后感
论文题目中的 in the wild 指的是非实验室的场景,应用在更为广泛的现实领域。
这两年出了更好的模型,但都没有开源,只能试用或者看看展示视频。这个模型好在可以直接下载使用。
1 | python3 inference.py \ |
给定人物视频和音频,合成的视频具有准确的唇声同步和修饰的面部表情。
相比之后只需上传一张照片和一段音频就能生成带有表情和上半身动作的视频,这种方法需要上传视频,主要编辑下半张脸,简单调节情绪,方法是对简单,但胜在可以不受限制地使用。
技术上主要是结合了之前的一些技术,规范化表情,在伪影修复和表情结合方面做了更细致的处理,提升了效果。
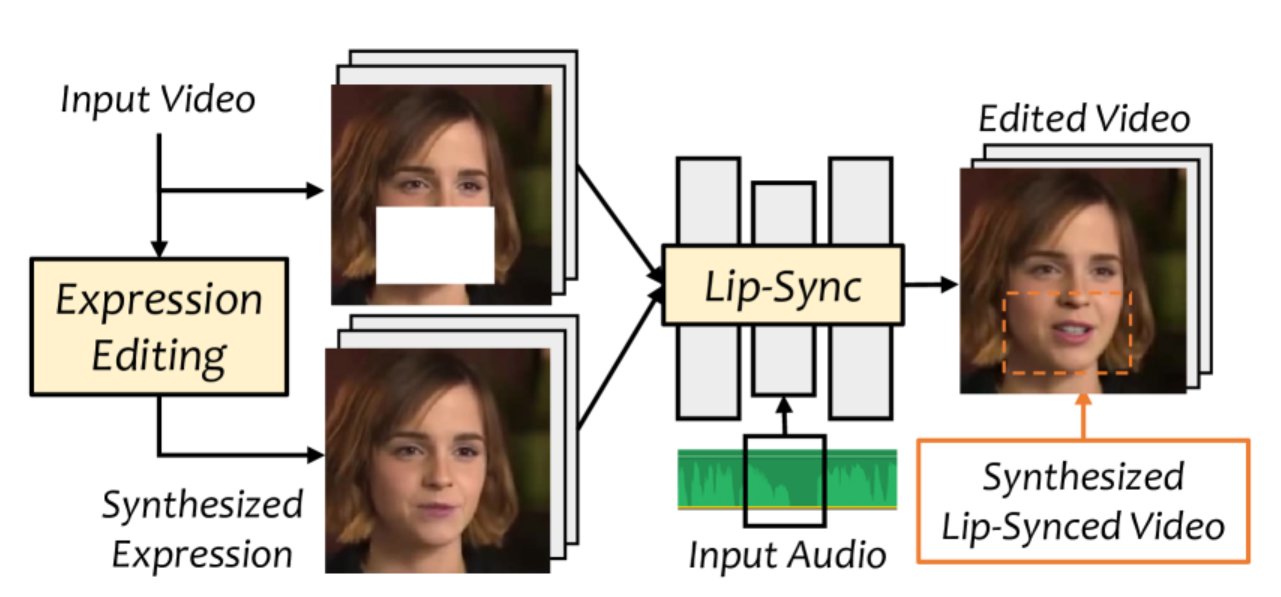
摘要
目标:根据输入音频编辑真实世界的说话头视频的面孔,即使具有不同的情绪也能生成高质量和口型同步的输出视频。
方法:提出了 VideoReTalking,将目标分解为三个顺序任务:(1)使用表情编辑网络生成具有规范表情的面部视频;(2)音频驱动的唇语同步;(3)面部增强网络改善照片逼真度。
结论:所有模块可以在顺序管道中处理,无需用户干预。该系统是一种通用方法,无需针对特定人物重新训练。在两个广泛使用的数据集和野外示例上的评估表明,该框架在唇语同步准确性和视觉质量方面优于其他最先进方法。
引言
根据输入语音音频编辑说话控制头部视频的任务具有重要的实际应用。例如,可以将整个视频翻译成不同的语言,或在视频录制后修改语音,这项任务被称为视觉配音。
之前的方法通常需要使用目标说话者的语料库进行训练,才能获得个性化模型。然而,这些方法不支持情感编辑,并且在更改语音内容时通常效果不好。
框架
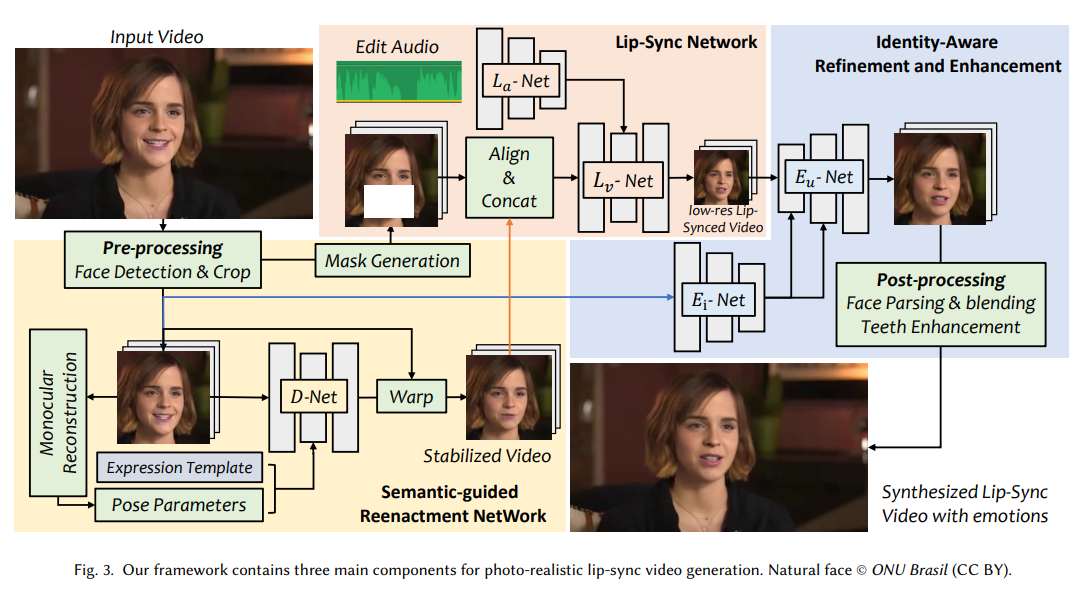
文中提出了一种跨模态视频修复框架。在驱动音频和情绪调制参考系的引导下,框架填充了被遮罩的下半脸。为此,设计了一个口型同步网络。这个网络使用掩蔽的下半部分脸框、给定的音频和原始视频帧作为输入,生成口型同步视频。
3.1.语义引导重演网络
规范化表情:通过语义引导重演网络来编辑脸部下半部分的表情,见图 -3 中的黄色部分。然后,具有稳定表情的帧将作为进一步唇部合成的参考。如图 -4 所示:D-Net 用于从原始视频中删除与说话相关的动作,其中 w/o 𝐷-Net 是直接使用原始帧作为参考,生成的嘴唇将根据原始嘴唇进行修改。

(小编说:简单来说,输入视频包含头部动作和面部表情,合成后的表情可能与音频的意思不符。因此,先使用语义引导网络去除了视频中的表情。)
3.2.口型同步网络
口型同步网络(𝐿-Net)用于通过新音频直接编辑原始视频,见图 -3 中的粉色部分。与之前的方法不同,本文使用𝐷-Net 预处理帧作为标识和结构参考,并使用音频和遮蔽下半脸的视频的原始帧作为条件,以合成与输入音频同步的口型视频。
L-Net 包含两个子网络:L_a 和 L_v,分别用于音频和视频处理。其详细结构见图 -5。
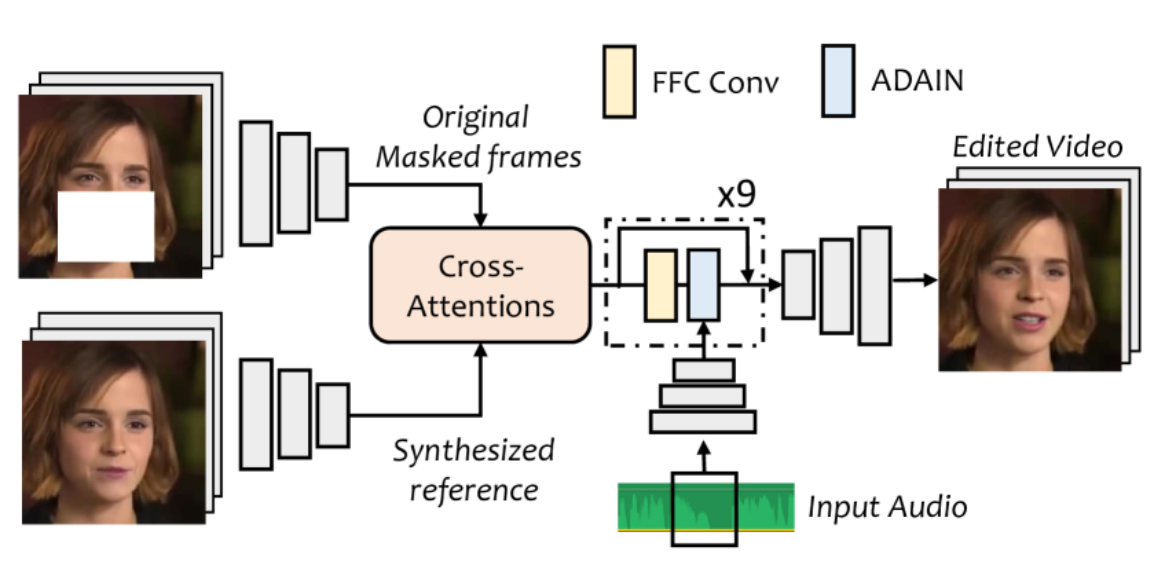
在音频处理方面,从原始音频中提取梅尔频谱图,并使用基于 ResNet 的编码器提取时间窗口 F_audio ∈ ℝ256×1×1 的全局音频向量。时间窗口设置为每帧 0.2 秒,得到 80×16 维度的特征进行处理。
在图像生成方面,通过两个不同的编码器从预处理的参考图像和原始掩码图像中提取图像特征 F_ref 和 F_orig ∈ ℝ256×H×W。接着,使用两个交叉注意力块自动建模像素之间的关系,计算特征的像素对应矩阵并扩大接收场。然后,用九个残差快速傅里叶卷积块完善特征,并通过 AdaIN 块注入音频特征。这些模块在每个 FFC 块后逐通道归一化视觉特征。最后,通过一系列卷积上采样层生成最终结果。
3.3.身份感知增强网络
𝐿-Net 的结果仍然不完美,因为在高分辨率的说话人头像数据集上训练模型非常困难。为了解决这个问题,作者提出了一个身份感知增强网络 E-Net,其灵感来自最近的图像生成网络,如图 -3 中的蓝色部分所示。为了获取高分辨率的说话人头像数据集并进行对齐以便上采样,首先使用基于 GAN 的面部恢复网络来增强低分辨率数据集。然而,在训练期间,增强的高分辨率数据集与测试期间 D-Net 输出的模糊图像之间存在领域差异。
为避免这种差异,将增强后的帧及其对应的音频输入 L-Net,生成 E-Net 的低分辨率输入。理想情况下,L-Net 使用条件音频生成与原始帧相同的唇部运动。这样,就可以直接使用高分辨率输入作为监督。
3.4.后处理
在将生成的图像粘贴回原始视频时,删除伪影,包括牙齿生成的瑕疵和边界框。利用预训练的面部恢复网络通过面部解析来增强牙齿部分。对于面部边界框问题,使用面部解析分割生成的面部,并通过多带拉普拉斯金字塔混合方法将其粘贴回原始视频。
4.训练
框架是使用 Pytorch 实现的,单独训练每个模块。训练后,可以按顺序测试整个框架,无需人工干预。
4.1.各模块训练
在 VoxCeleb 数据集上训练了网络,该数据集包含 22496 个具有不同身份和头部姿势的视频。输入帧的大小被调整为 256 × 256,并在裁剪后的面部上进行训练,类似于原始方法。
4.2.评估
从视觉质量和口型同步方面评估了所提出的方法:由于无法获得 ground truth 视频,故选择 Fréchet inception distance(FID)和累积概率模糊检测(CPBD)来评估生成视频的视觉质量。较低的 FID 分数意味着生成的图像更接近数据集分布。CPBD 反映了结果的清晰度。
另外,选择 LSE-C 和 LSE-D 来评估唇形同步的质量。在数据集方面,在低分辨率数据集(LRS2)和高分辨率数据集(HDTF)上评估了文中框架。分别创建了 100 个 20 秒的音频视频对,用于 LRS2 和 HDTF 数据集评估。
5.结果
主实验结果如下:
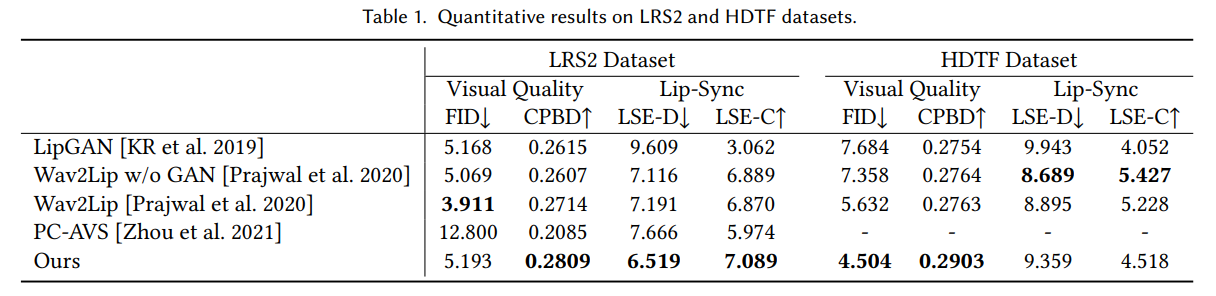
此外,人工评估和消融实验也证明了模型和三个模块的有效性。