论文阅读_胶囊网络_CapsNet
介绍
英文题目:Dynamic Routing Between Capsules
中文题目:胶囊之间的动态路由
论文地址:https://papers.nips.cc/paper/2017/file/2cad8fa47bbef282badbb8de5374b894-Paper.pdf
领域:深度学习
发表时间:2017
作者:Sara Sabour,Nicholas Frosst,Geoffrey E. Hinton
出处:NIPS(机器学习和计算神经科学的国际会议)
被引量:3466
代码和数据:https://github.com/naturomics/CapsNet-Tensorflow
阅读时间:22-03-29
其它介绍
大牛 Geoffrey E. Hinton 提出的 “胶囊网络” 到底是啥?
精读
1 摘要
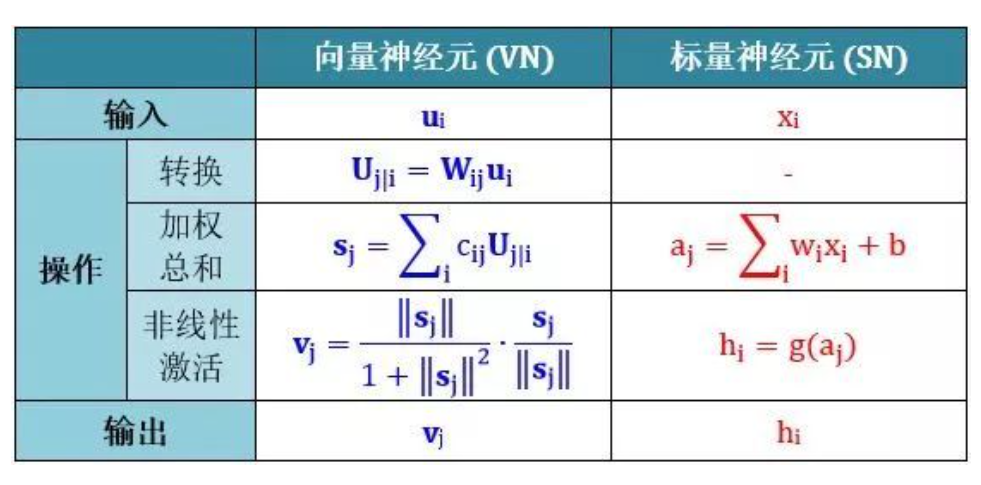
胶囊是一组神经元,其激活向量能表示特定类型的特征,比如一个对象或对象部分。文中用激活向量的长度表示存在的概率,用方向表示参数。一层激活胶囊通过变换矩阵为高层胶囊提供实例化参数。当多个低层胶囊预测一致时,高层胶囊被激活。实验部分使用 MNIST 数据集,证明在识别高度重叠的数字时,文中方法明显优于当时的卷积神经网络。
2 介绍
人类视觉通过确定的视点序列来忽略不相关的细节,以确保只以最高分辨率处理光学阵列的一小部分。在本文中,假设多层视觉系统在每个注视上创建了一个解析树状结构(不是所有都往下传,选部分往下传)。
解析树是从固定的多层神经网络中雕刻出来的,就像雕塑是从岩石上雕刻的一样。每一层可以分解成多个神经元组称为胶囊,解析树的每个节点都与一个激活的胶囊有关,通过迭代路由选择(路由(routing):底层胶囊匹配高层胶囊,并将向量传递到高层胶囊的过程),每个激活的胶囊将选择其上层的一个胶囊作为其在树中的父节点,对于更高级的视频系统,迭代过程将解决将部件分配给整体的问题。
激活的胶囊可以表征实体的不同特性,比如位置,大小,方向,变形、速度、色调、纹理等。“是否存在”是一个特殊的特征,比较简单的方法是使用一个逻辑单元描述是否存在的概率。文中作者使用向量的模长来表征其是否存在,用向量的方向来描述其特征。使用非线性方法,保证方向不变,改变其大小的方式,将其限制在 1 以内。
胶囊的输出是向量,因此,可以使用动态路由来让胶囊的输出被发送到其上层与之匹配的父节点。将输出路由到可能父节点的概率之后归一化到 1(softmax)。对于每个可能的父节点,胶囊使用它的输出和权重矩阵计算出 " 预测向量 ",当预测向量与其可能的父节点匹配度高时,就增加其耦合系数,减少其它可能父节点的耦合系数,从而进一步增加了对其父节点输出的贡献(具体算法见第二部分)。这种通过路由选择的方式明显优于原始的最大池化方法,它允许一层的神经元忽略其下层最活跃特征以外的其它特征。
卷积神经网络能够将在图像中一个位置获得的权重值转换到其他位置,这对图像解析非常有帮助。为了实现这一点,文中方法使除了最后一层胶囊之外的所有胶囊都是卷积的。与 CNN 一样,使更高级别的胶囊覆盖图像的更大区域。而与 max-pooling 不同的是,不丢弃有关实体在区域内的准确位置的信息。对于低层的胶囊,采用“place-coded",随着层次提升,更多的位置信息在胶囊的输出向量的实值分量中作为“rate-coding”。更高级别的胶囊代表着更复杂、更多自由度的实体,这表明胶囊的维度应该随着我们在层次结构中的上升而增加。
胶囊网络和传统神经网络相比的主要改进包括:将输出从标量变为向量,通过路由替代最大池化方法,对比如下:
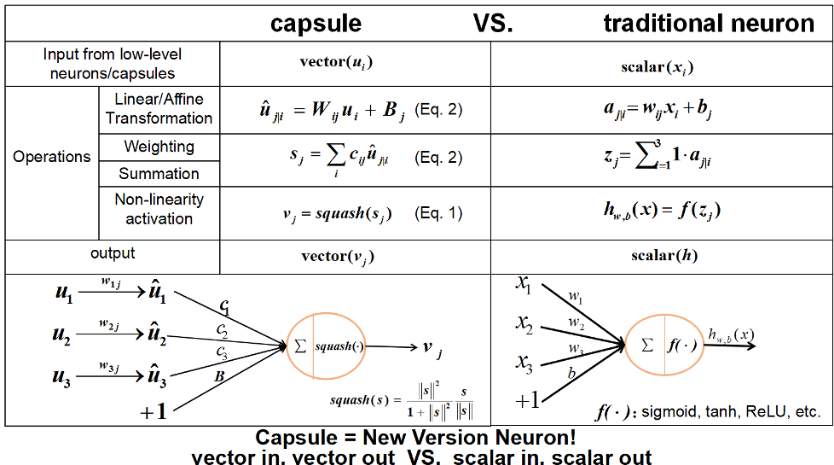
3 计算胶囊的输入输出
文中提出的胶囊实现方法利用动态路由,简单直接且效果好。
希望用胶囊输出向量的长度来表示实体出现的概率,因此,使用非线性的激活函数 squashing(压榨),来保证输出模长在 0 到 1 之间。辨别任务可以很好地利用该方法。

式中的 vj 是胶囊的输出,sj 是全部输入;式中左边是模长,右边是方向。
除第一层以外,sj 是所有其上一层“预测向量”^uj|i 的权重加和:
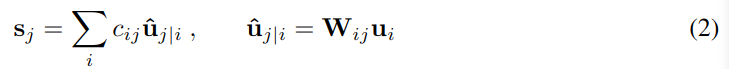
其中 i 指的是第 l 层中的胶囊,j 指的是第 l+1 层中的胶囊。^uj|i 通过 l 层胶囊输出 ui 和权重矩阵 Wij 计算到的;cij 是耦合系数,它是在计算动态路由过程中迭代算出的。
耦合系数 cij 使用 softmax 计算得出,所有胶囊的 cij 加和为 1。

bij 是对数先验概率,它描述的是胶囊 i 与胶囊 j 的匹配关系;bij 描述 l 层和 l+1 层之间胶囊 i 和 j 的相似度;b 越高,c 越高。
bij 也可以和其它权重同时学习,它依赖于两个胶囊的位置和类型,而与当前输入图片无关。通过衡量当前每个胶囊输出的 vj 与胶囊 i 作出的预测^uj|i 的一致性,迭代地计算耦合系数。
一致性通过计算点积 \(a_{ij}=v_j.\hat{u}_{j|i}\) 得到,它被用于调整 bij。两个向量点积用于描述它俩的一致性,向量越相似 bij 越大。
在卷积胶囊层中,每个胶囊层向上面层中的每一种胶囊层输出一个局部向量网格(涉及层中的多个点),该网格的每个成员以及每种胶囊层使用不同的变换矩阵。
路由函数计算方法如下:

函数的输入是 u,输出是 v。
输入参数包含 l 层的输出^uj|i,迭代次数 r 和层 l;
b 用于描述第 l 层 (i) 和第 l+1 层 (j) 中各个胶囊的关系,将其初值设成 0;
进的 r 次迭代;
使用 softmax 把 b 转换成 0-1 之前的 c;
然后利用 c 与 l 层的输出 u 计算出 sj;
sj 通过激活函数 squash(相当于卷积网络中的池化和激活函数)计算出该 l+1 层的输出 vj;
通过 u 与 v 的相似性迭代改进路由 b;
最终返回输出 vj。
由此可见,与卷积网络提最重要差异是:它不仅计算了向下一层传的具体内容,还通过路由计算了是不是要往下传(b 和 c),传给谁(哪个 j)。
4 边际损失
以数字识别 MNIST 为例,只需要识别数字 0-9,可将其看成 k=10 的分类问题。
使用实例向量的模长来表征实体(数字)存在的概率。为了识别图中可能出现的多个数字,在顶层,使用 Lk 分别评价每个胶囊 (k) 的损失。
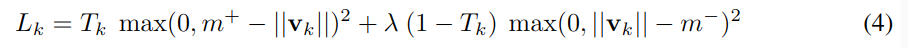
当图片中存在该数字时 Tk=1,m+ 上边界设为 0.9,m- 下边界设为 0.1,λ用于权衡两个边界的权重,它控制无法识别该数字时的损失,以免在开始学习时胶囊的模长变得太小。文是将λ设为 0.5,损失函数是所有胶囊损失的加和。
5 胶囊网络结构
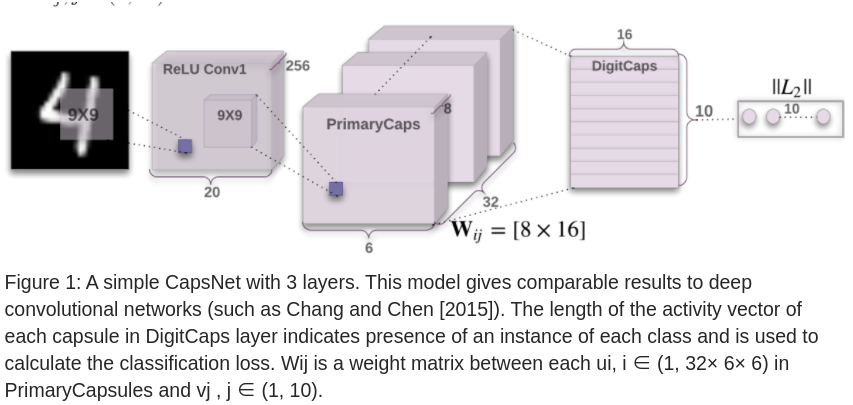
图 -1 展示了一个简单的胶囊网络结构,由两个卷积层和一个全连接层组成。Conv1 是卷积核 9x9 的卷积层。
MINIST 图片大小为 28x28,卷积核大小为 9x9,步长为 1,输出为 20x20 的卷积结果(28-9+1->20),通道数为 256,它将像素转换成局部特征,作为胶囊的输入(左图)。
PrimaryCapsules(中图)是低层的多维实体,它根据图像反推出物体的信息(反向渲染)。它与普通卷积把所有输出拼接在一起的方法不同,这也是胶囊的特性。
第二层(PrimaryCapsules)是 32 通道的卷积胶囊层(每个 PrimaryCapsule 包含 8 个卷积单元,9x9 的卷积核,步长为 2),每个 PrimaryCapsule 的输入是上一层 Conv1 输出的 256x81,所有 PrimaryCapsules 共有 32×6×6 输出((20-9+1)/2->6 是卷积后的输出个数,32 是通道数),注意此处输出的是向量(变标量输出为矢量输出是胶囊最重要的改进之一),每个输出是 8D 向量,6x6 网格共享权重 Wij。
最后一层DigitCaps(右图)对于每个数字有 16D 的输出。将 8D 转成 16D,使用权重 Wij。
模型只在第二层和第三层进行路由,第一层输出 1D,因此不需要定向。所有 bij 初值都为 0,因此,开始时输出 ui 对 v0-v9 有相等的概率。
5.1 重建图片
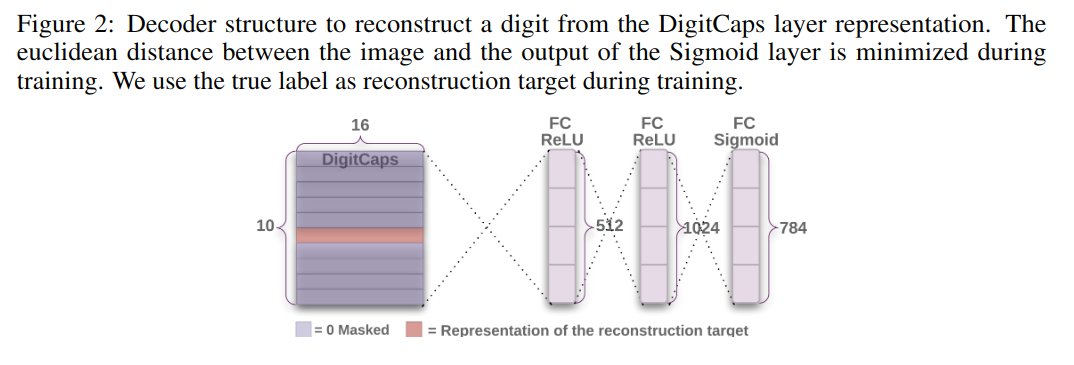
如图 -2 所示,在第三层之后又加入了三个全连接层,用于重建与原始图片相同的图片,图片大小也为 28x28=764。
使用重建后计算两图差异作为损失函数,尽量用第三层的输出还原图片。在训练过程中,我们屏蔽了除正确数字胶囊的活动向量之外的所有内容。将重建损失限制在 0.0005,使它不会在训练时主导边际损失,这样做保证了模型的健壮性,并保留了图片的重要特征,重建结果如图 -3 所示:

6 胶囊网络用于 MNIST
数据集使用 60K 数据作为训练集,10K 数据作为测试集。表 -1 展示了实验结果:
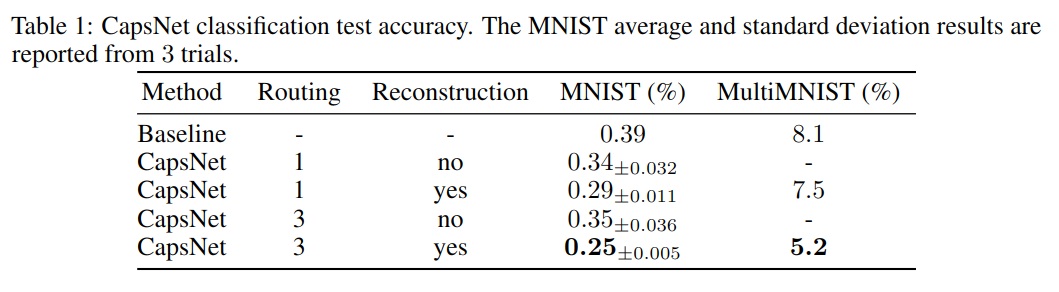
其中 Baseline 是三层卷积网络,参数 35.4M,而 CapsNet 在不重建的情况下为 8.2M 和 6.8M 参数。
6.1 胶囊的各个维度代表什么
从图 -4 中可以看到,通过对输出的 16 个维度上扰动,展示了不同维度的捕捉的不同特征。

6.2 仿射变换的健壮性
实验表明,在不使用仿射变换数据训练的情况下,文中模型对加入仿射扰动的测试,准确率能达到 79%,而传统模型只能达到 66%。
7 MultiMNIST 数据集
MultiMNIST 是将 MNIST 数据叠加得到的数据集。训练数据大小为 60M,测试数据为 10M。
结果如图 -5 所示,重建的数字分别用红色和绿色显示,其中 L(l1,l2) 是图中的数字,R(r1,r2) 是重建的数字。图中左半边是识别正确的,右半边的识别错误的。

8 代码示例
8.1 git 上高星示例
https://github.com/laubonghaudoi/CapsNet_guide_PyTorch/blob/master/DigitCaps.py)
8.2 主要模块
- main.py 程序入口
- PrimaryCaps.py 第一层胶囊
- DigitCaps.py 第二层胶囊
- Decoder.py 胶囊后的决策层
9 参考
胶囊网络全新升级!引入自注意力机制的Efficient-CapsNet
10 引申学习
10.1 引申一
- 论文题目:LEARNING TO PARSE IMAGES
- 相关概念:
- 可信网络(credibility networks)
- 从局部到整体,才更合理
- 对概率模型进行树状排序,局部组成整体
- 结构 256-64-4
- 其中隐藏层描述了 64 种潜在的分布
- 使用 EM 方法,是概率模型
- 解析树:类似于剪枝的筛选过程
10.2 引申二
- 论文题目:TRANSFORMING AUTO-ENCODERS
- 相关概念:
- 提出胶囊:最终输出类似 SIFT 的描述
- 自编码器的变体,其中做了 30 个胶囊(自编码器),每个胶囊加入一些人工干预(如平移、缩放、光照等),让它学习固定的某种特征(如平移不变性)。
- 使用 p 来(类似 gate)约束,超过一定范围后,这个胶囊就不使用了,由 p 值控制哪些局部信息组成整体信息
- 手动控制每个胶囊学到不同的东西,最终学到了视觉不变性。
- 模型泛化能力强。
- 胶囊抽取了某些部分的特征。
- 一个隐藏层的网络