论文阅读_Segment_Anything
name_ch: 切分任何东西
name_en: Segment Anything
paper_addr: http://arxiv.org/abs/2304.02643
date_publish: 2023-04-05
demo: https://segment-anything.com
读后感
论文提出 Segment Anything (SA) 模型,无需精调,即可通过文本提示进行图像分割(抠图)。
SA 基于将 Transformer 模型应用到图像处理领域 ViT 论文阅读_ViT,对图像的无监督学习 MAE 论文阅读_MAE,以及文本图像相互映射的 CLIP 论文阅读_图像生成文本_CLIP,可以说它是图像领域大模型落地的一个精典范例。
之前的图像分割模型,比如要识别图中的猫,先需要做一些标注数据,用工具把图中的猫标注出来,然后用这些标注数据在 pretrain 模型的基础上 fine-tune。
SA 论文解决了两个问题:把文字描述和图中形象联系起来;在不 fine-tune 的情况下解决 zero-shot 问题。另外,本文的一大亮点是:用先交互后自动的方式标注了数以十亿记的图片,实现了标注功能的自我提升。
摘要
Segment Anything (SA) 即分割一切,论文的成果是最终发布了模型SAM,它无需 fine-tune 即可对图中任何物体进行分割,且能通过文本提示分割图像,效果可与有监督学习媲美。论文同时发布了超过 1B 图片,11M 的 mask 标注的数据集 SA-1B。
介绍
提示学习帮助大语言模型提升了处理 zero-shot 问题的能力;CLIP 和 ALIGN 模型又提供了文本和图像对齐的方法,以供下游任务使用,比如 DALL-E 的生成图片。本文主要研究图像分割:通过文本提示抠图。
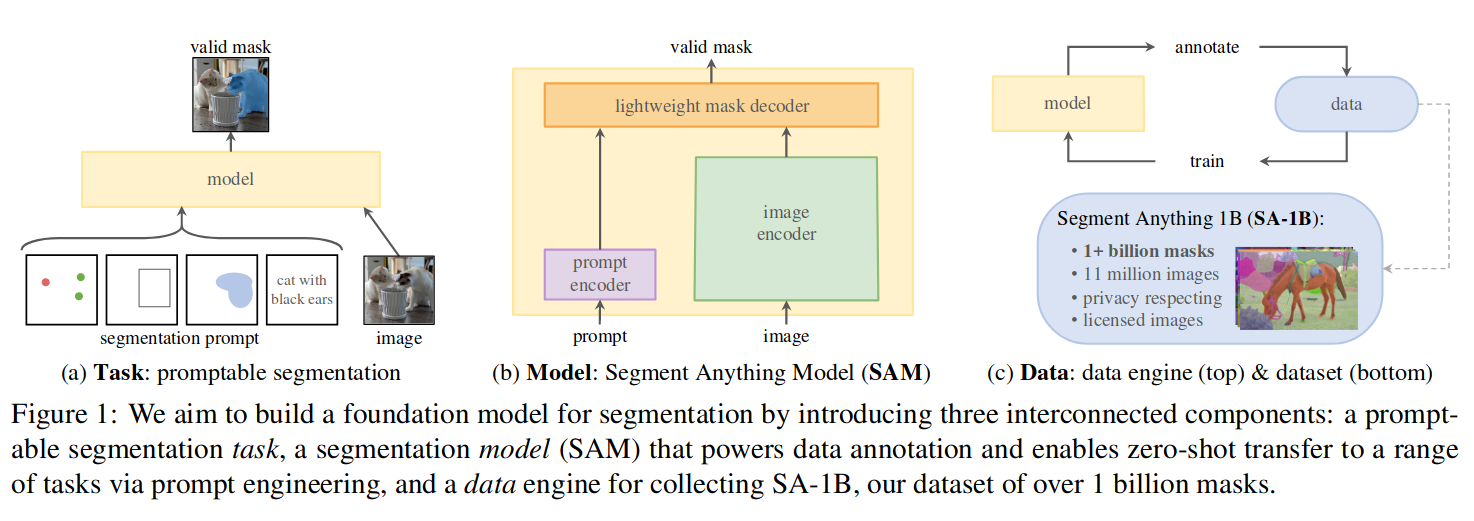
具体通过三个相互关联的组件来构建模型:任务、模型、数据。
任务
提示工程近年在自然语言和视觉建模方面产生巨大影响,文中提出了可提示的图像分割。如图 1-(a) 所示,通过提供图片,及各种各样的提示来分割出所需区域。提示可包含:描述文本、空间中的点(星)、区域(方块)等。在提示不明确的情况下,可能存在多个对象(如:衣服和穿衣服的人),至少能合理地分割其中一个对象。
在预训练阶段,构造了可能与具体使用方法相似的任务以训练模型,生成了具有泛化能力的图像分割器,以解决 zero-shot 问题。后期可通过提示和下游任务组合,桷建更大系统中的组件来执行新的、不同的任务。
模型
设计模型结构 SAM,需要支持:灵活的提示,实时计算,歧意识别。
具体实现如图 -1(b) 所示,一个图像编码器生成图像嵌入,一个指令编码器生成提示嵌入,然后用一个轻量的 mask 解码器将二者结合用于分割任务。
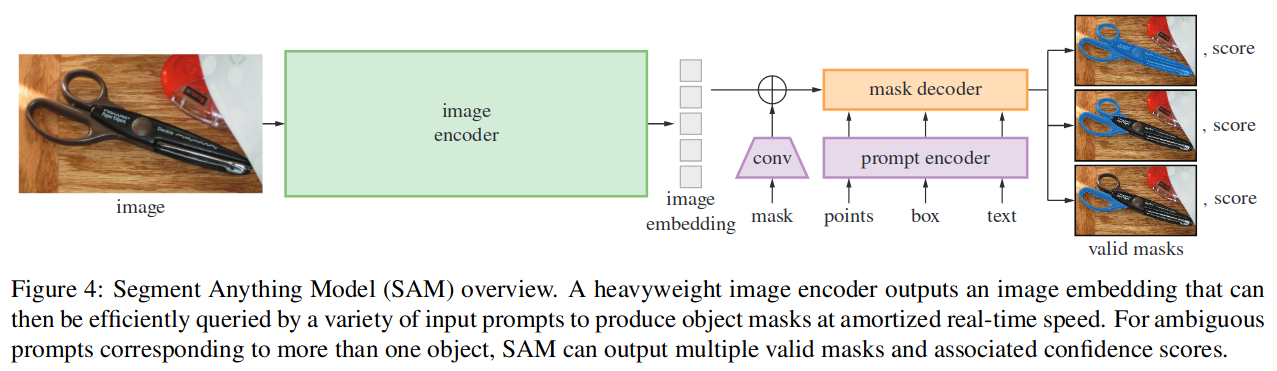
图像编码器
基于 ViT 的图像编码器,只在图像输入时生成一次图像嵌入,嵌入生成后,可与多个提示结合,以节约算力,每次只需要 50ms,以满足 web 交互的需要。针对歧义问题,设计了一个提示多个 mask 的方案。
本文中把图像先缩放成 1024x1024,短边补齐,然后分成 64x64 块个 16x16 的块。
指令编码器
考虑两组提示:稀疏(点、框、文本)和密集(mask)。稀疏提示通过位置编码关联每个提示类型的学习嵌入和来自 CLIP(文本与图像映射)的嵌入。密集提示(mask)使用卷积嵌入,可与图像嵌入逐元素求和。
解码器
mask 解码器将图像嵌入、提示嵌入和输出 token 映射到 mask。该模型对 Transformer 解码器块进行了修改,后跟动态 mask 预测头。使用提示自注意力和交叉注意力来更新所有嵌入;然后对图像嵌入进行上采样;MLP 将输出 token 映射到动态线性分类器,再计算每个图像位置的蒙版是前景的概率。
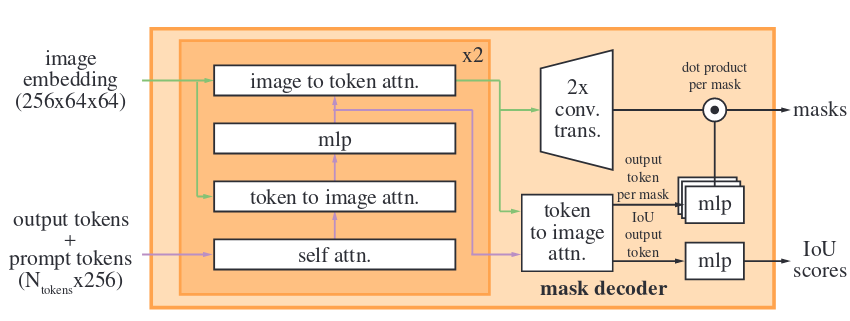
歧义问题
如果给出的提示不明确,模型将生成多个有效 mask。因此,修改模型以预测单个提示的多个输出 mask,发现 3 个 mask 输出足以支持大多数常见情况(嵌套 mask 通常最多三个深度:整体、部分和子部分)。
数据引擎
大模型需要大量不同分布的图片及 mask 训练,而现有的数据集并不丰富。
文中提出建立一个数据引擎 data engine,模型标注数据,数据又反过来训练模型,循环往复。具体包含三个阶段:
辅助手动:SAM 协助标注者注释 mask。
标注者被要求按照突出的顺序标记对象,并被鼓励在标注超过 30 秒后处理下一张图像。使用常见的公共分割数据集进行训练,然后开始交互标注,总共对模型进行了 6 次再训练,每个 mask 的平均注释时间从 34 秒减少到 14 秒,每张图像的平均 mask 数量从 20 个增加到 44 个。
半自动:SAM 自动生成 mask,使用上一个阶段训练的结果训练一个边界识别器。自动标注图片,让标注者专注于注释剩余的对象,以提升 mask 的多样性。
根据新收集的数据重新训练模型 5 次。对象的标记更具挑战性,平均注释时间回到 34 秒,每张图像的平均 mask 数量从 44 个增加到 72 个 mask,其中包括自动 mask。
全自动:SAM 自动标注,为每张图像平均产生约 100 个高质量 mask。
在此阶段,开发了歧义感知模型,即使在模棱两可的情况下也能预测有效的 mask。最终生成的数据集有 99.1% 来自于全自动标注。
最终产生 SA-1B 数据集,超过 10 亿个带 mask 的数据集,图片全部由 SAM 自动标注,平均每个图像 100 个 mask。
模型效果
建立自己去 meta 网站试一试,不用梯子即可使用。
https://segment-anything.com/demo
自己上传图片试了一下,把头发和脸分开,两只手可以分开,肉色的衣服和皮肤,边缘还比较完美,mask 后效果就很像动画效果。不知道修图师和插画师作何感想,娃们还会不会再去学插画和素描?是不是应该先去研究一下 AlphaGo 出来之后,围棋班有没有受影响?
本地搭建环境
源码基于 Pytorch,从 predictor_example 来看,接口非常简单,只要稍微做过一些图像模型的人都能看懂,mask 区域被直接返回,我没找到调用 CLIP 的图文对齐部分,只试用了切割部分。
下载源码
1 | git clone https://github.com/facebookresearch/segment-anything.git |
基于 docker 运行
1 | docker pull pytorch/pytorch:1.13.1-cuda11.6-cudnn8-runtime |
进入 docker 后,安装 jupyter
1 | pip install jupyter_nbextensions_configurator jupyter_contrib_nbextensions |
我的环境还安装了以下工具
1 | apt-get update |
测试一下不同参数量的模型:
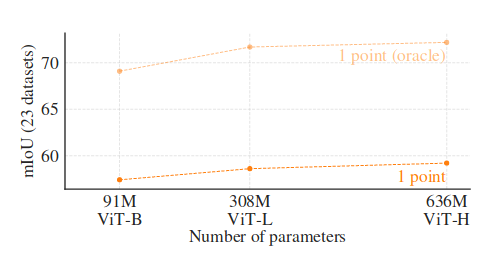
ViT-B(base), ViT-L(Large), ViT-H(Huge)。
目前最大的模型是谷歌团队的 ViT-22B 模型,其参数 22B。
默认使用 ViT-H,下载约 2.4G,GPU 内存用满 11G。
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
效果如下:

下载 ViT-B,下载约 358M,GPU 内存用到 8G 左右,
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
比较后可以看到,大模型的 mask 效果明显更好一些:

不是特别大的模型,如果有 GPU,在家用速度也能接受,从此拥有了自己的抠图小助手。
参考文章
ViT 模型:论文阅读_ViT
MAE 模型:论文阅读_MAE